Clear Sky Science · ja
計量学習によるランク不要のテンソル分解
データの海からパターンを見つける
現代の科学は複雑なデータにあふれています:大量の医用画像、脳活動マップ、天文画像、材料のシミュレーションなどです。こうしたデータを理解するには、核心的な情報を失わずにより単純な形に圧縮する必要があります。本論文はそのための新しい方法を示します。ピクセルを忠実に再構成することにこだわるのではなく、サンプル間の真の関係性――どの脳がどの脳に似ているか、どの銀河形状がどれに近いか――を捉えることに注力します。こうして得られるデータのマップは、生の詳細ではなく意味を反映するものになります。
画像の再構成から類似性の計測へ
従来の多次元データ簡素化手法、いわゆるテンソル分解は和音を音に分けるような働きをします。データの「塊」を少数の基本パターンと重みへ因子分解するのです。この際、あらかじめ使えるパターン数(「ランク」)を指定する必要があり、評価は元データの再構成精度で行われます。これは圧縮やノイズ除去には最適ですが、「この二人の顔は同一人物か?」や「この脳スキャンは自閉症か典型群か?」のように正しい分類が再構成より重要なタスクには必ずしも適しません。
一方、ディープラーニングは別の考え方を普及させました:テンソルを代数的に分解する代わりに、ニューラルネットワークを通じてコンパクトな数値コード(埋め込み)を学習するというアプローチです。従来のオートエンコーダは依然として再構成に重心を置きます。本研究は目的を転換します。ランクを固定せずピクセル単位の復元を目指さない「ランク不要」フレームワークを提案し、代わりに距離尺度を学習します。同一人物・同一診断・同一物理クラスなど、近くあるべき点が埋め込み空間で近接し、異なるはずの点が遠ざけられるようにするのです。
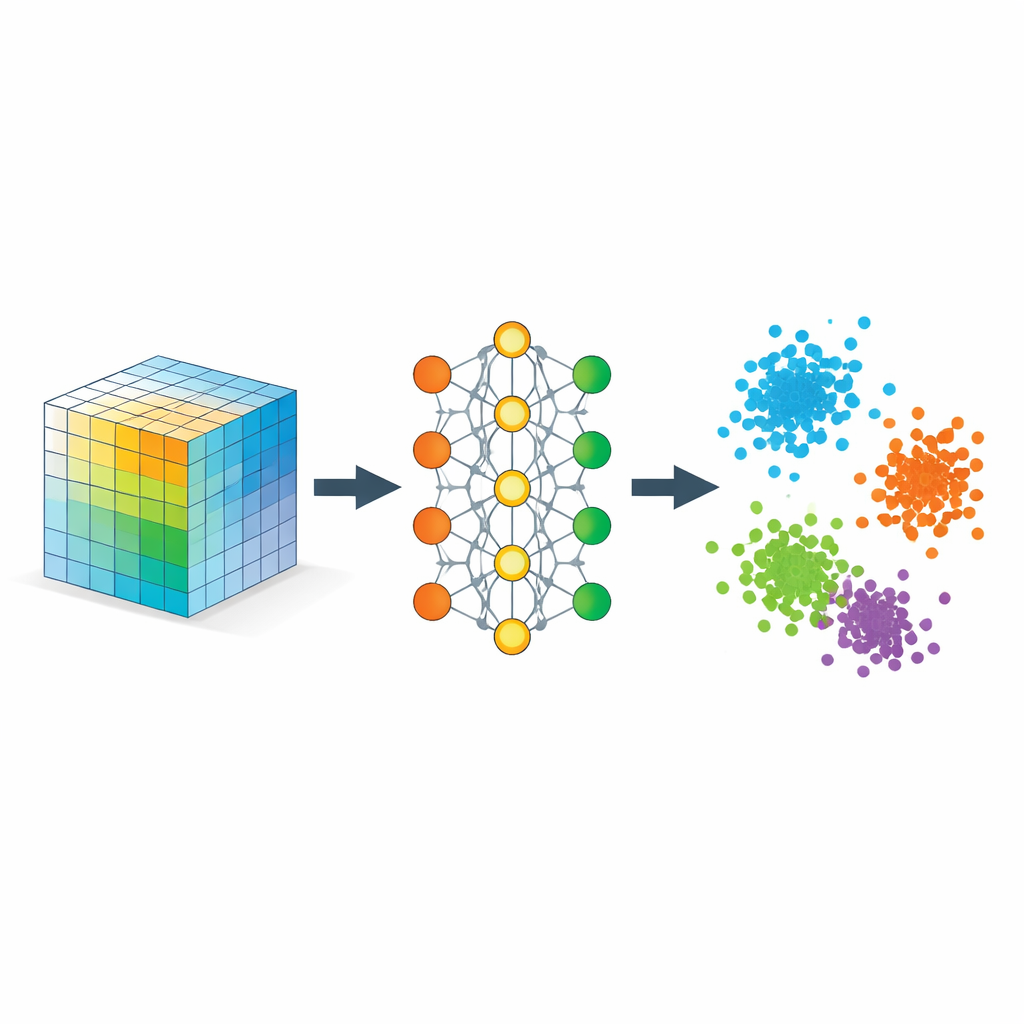
「近い」が何を意味するかネットワークに教える
重要な要素は計量学習と呼ばれる戦略で、ここではアンカー・正例・負例の三つ組(トリプレット)で実装されています。トレーニング中、ネットワークはアンカーが正例よりも負例に比べて安全マージン分だけ近くなると報酬を受けます。多数のこうしたトリプレットを経ることで、この単純な規則が埋め込み空間を彫刻し、距離がピクセルの類似性ではなく意味的な類似性を反映するようになります。さらに正則化項により情報を埋め込み次元全体に均等に広げ、すべてが一本の線に潰れるのを避け、元データで近接していた点同士が埋め込み後も概ね近く保たれるようにしています。
数学的には、著者らはこの埋め込みが柔軟なテンソル分解のように振る舞うことを示していますが、事前にランクを定める必要はありません。学習された座標は、データの異なる部分がどれほど強く整合するかを測る類似度テンソルの古典的分解の因子として解釈できます。モデルが冗長な方向に罰則を課すため、埋め込み次元を有効に使う傾向があり、意味のある成分がいくつ必要かをデータ自身が決めます。同時に、標準的な学習手続きが収束すること、得られた幾何構造がクラスを分離しつつ意味のある局所関係を大きく歪めないことについて理論的保証も提供しています。
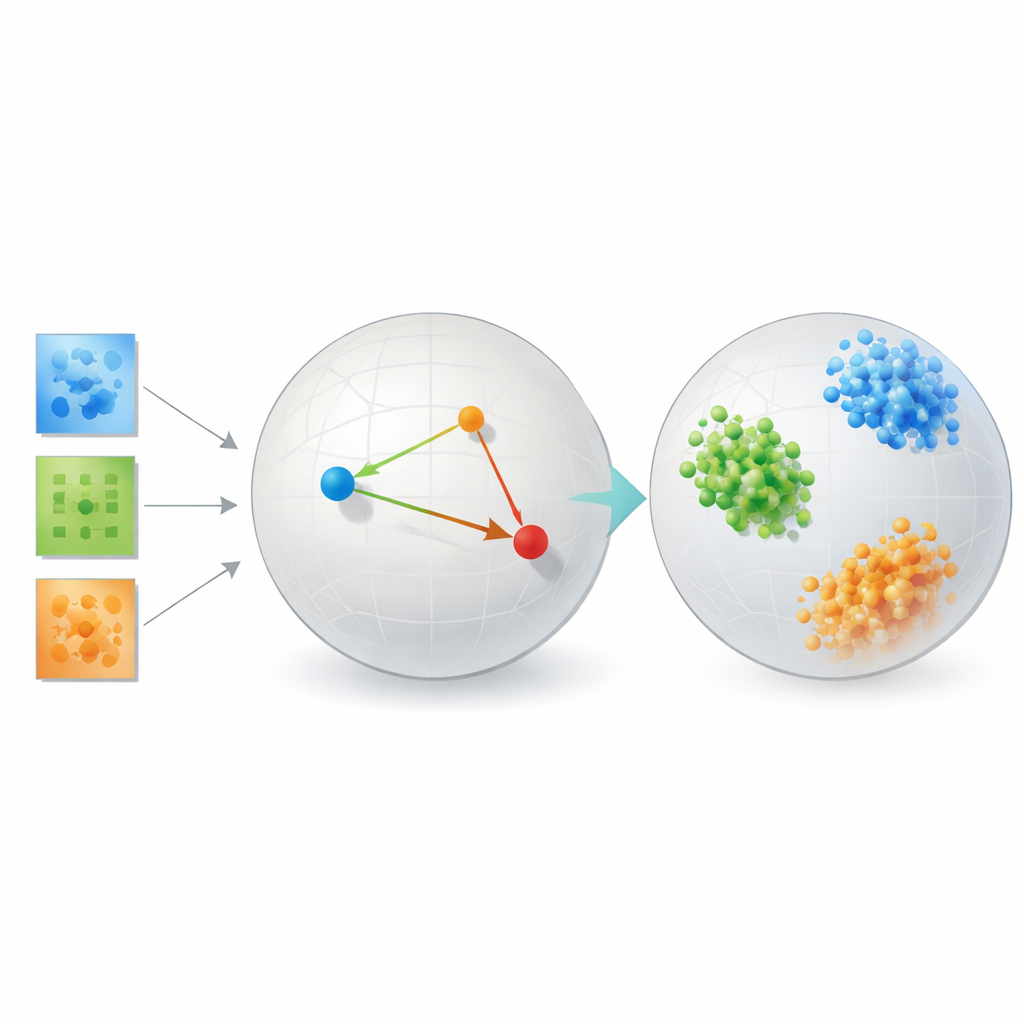
手法の実証
この手法が単なる美しい理論にとどまらないことを示すために、著者は複数の異なる問題で検証を行っています。顔認識ベンチマークでは、学習された埋め込みが同一人物の画像を緊密かつよく分離されたクラスタにまとめ、主成分分析や t-SNE、UMAP といった可視化ツール、固定ランクに依存する従来のテンソル分解を大きく上回りました。自閉症のある人とない人の脳結合データでは、再構成重視のテンソル手法やオートエンコーダよりも二群がより明確に分離される空間を発見し、脳領域間の相互作用に関する臨床的に重要なパターンに迫っていることを示唆しています。
研究はまた、銀河形状や結晶構造の制御されたシミュレーションも含み、そこでは「真の」カテゴリが正確に知られています。ここでは計量学習フレームワークがほぼ完全に合成銀河や結晶を物理的な基礎タイプごとにクラスタリングしました。これらすべての設定において、本手法は元のピクセル配置への完全な忠実さをある程度犠牲にしてでも、類似性と差異が科学的意味と一致する表現を一貫して生成しました。重要なのは、比較的小規模な科学データセットでしばしば必要とされる大規模なデータと計算資源を要するトランスフォーマ系の深層モデルを訓練することなくこれを達成している点であり、そうしたモデルは本件では苦戦しました。
将来の科学データにとっての意義
限られた高次元データの中でパターンを探す科学者にとって、本研究は有望な視点の転換を提供します。再構成のためにランクを推定して最適化するのではなく、同一診断、同一材料相、同一天体クラスといった研究者が関心を持つ関係性を直接反映する埋め込みを求めることができます。提案するランク不要の計量学習フレームワークは、データが乏しい場合でも解釈可能で強力な埋め込みを構築できることを示しています。課題としてはクラス不均衡への対処や多カテゴリへのスケーリングなどが残りますが、メッセージは明確です:多くの科学的問題では、元の信号の全細部を再構成するよりも、良い類似性の概念を学ぶことのほうが価値が高いことがあるのです。
引用: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
キーワード: 計量学習, テンソル分解, 表現学習, 次元削減, 科学データ解析