Clear Sky Science · ja
劣化を考慮した赤外線・可視画像融合のためのVLM誘導ネットワーク結合劣化モデリング
雑多な世界で鮮明な夜間視覚を
現代のカメラは暗闇を見通し、熱を感知し、道路を監視できますが、撮影画像はしばしば完璧とはほど遠いものです。街灯がフレアを起こし、影が細部を隠し、センサーは斑点状のノイズを加えます。本研究は、一般的なカラー映像と熱を感知する赤外画像を新たな方法で融合し、両入力が大きく劣化している場合でも最終画像をより鮮明で信頼できるものにする手法を提示します。この手法は、自動運転車、監視システム、その他のスマートカメラが、夜間や悪天候、物が多い実世界のシーンなど、最も必要とされる状況でより信頼性を高める可能性があります。
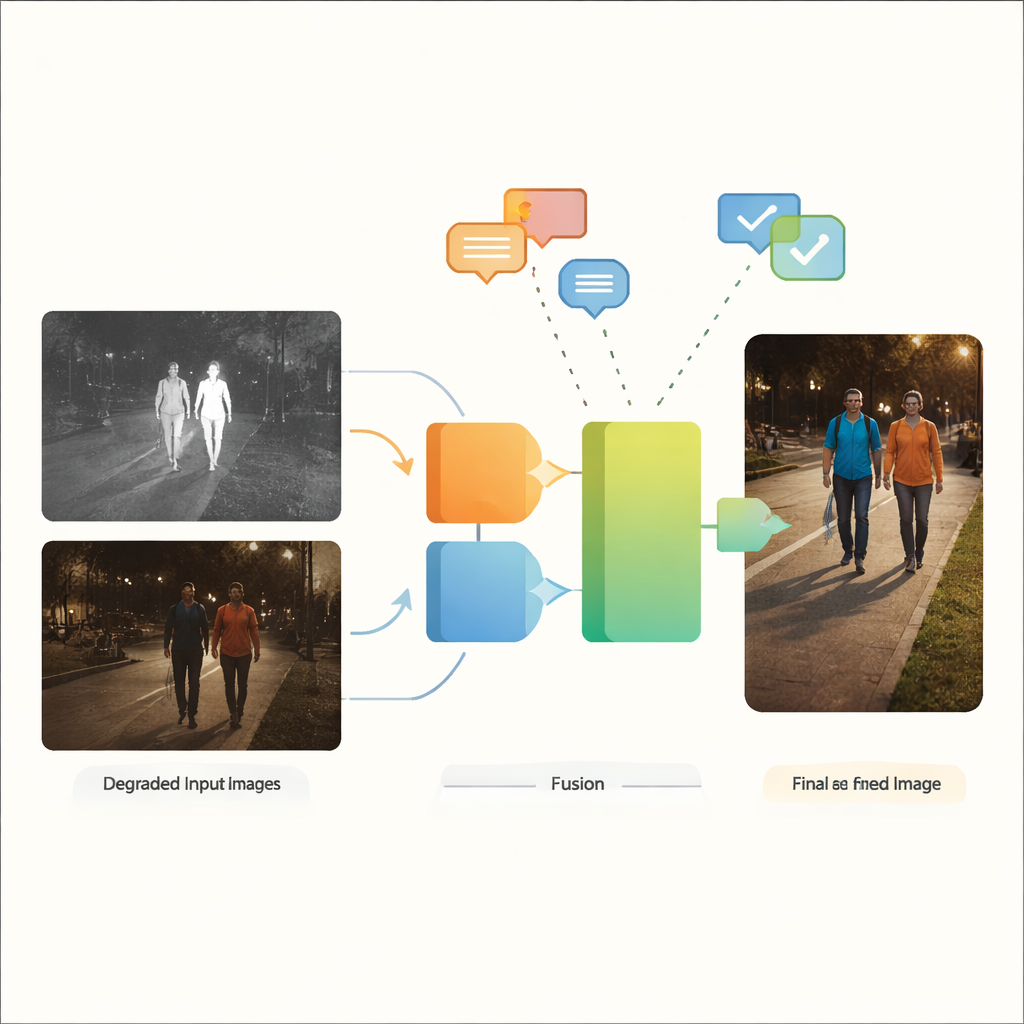
二つの目が一つより優れている理由
可視光カメラは人間が慣れ親しんだ豊かな色や質感を捉えますが、低照度や強い反射、深い影の下では苦戦します。一方、赤外カメラは熱を感知し、暗闇でも人や車両といった温かい物体を容易に検出できますが、画像は平坦で細部が欠けることが多いです。赤外と可視の画像融合は、赤外の鮮明な輪郭と可視の文脈的な詳細や色彩という双方の長所を組み合わせることを目指します。しかし従来の多くの融合手法は、入力画像が既にクリーンで高品質であることを前提としています。これは、街路や都市、産業現場のようにぼかし、ノイズ、暗い照明、露出過多がむしろ常態である実世界には適していません。
前処理が不十分なとき
既存のシステムは通常、劣化した画像に対して二つの切り離されたステップで対処します。まず個別の補正ツールが暗いシーンを明るくし、ノイズを低減し、コントラストを補正します。その後でようやく融合ネットワークが改善された画像をブレンドします。この二段構えのアプローチにはいくつかの欠点があります。各種の欠陥やセンサーごとに異なる補正ツールを選び、調整しなければならず、ワークフローが脆弱で複雑になりがちです。さらに重要な点は、単独の補正段階で失われたり歪められたりした情報は、その後の融合段階で回復できないということです。最近の研究の中には、特定の劣化タイプに特化したネットワークや、単一の劣化モダリティを扱う言語誘導モデルを導入したものもあります。しかし赤外と可視の両方が劣化し、しかもしばしば異なる形で劣化している状況では、これらの戦略は依然として手動による前処理に大きく依存し、混在した実世界条件で苦労します。
劣化を理解する融合ネットワーク
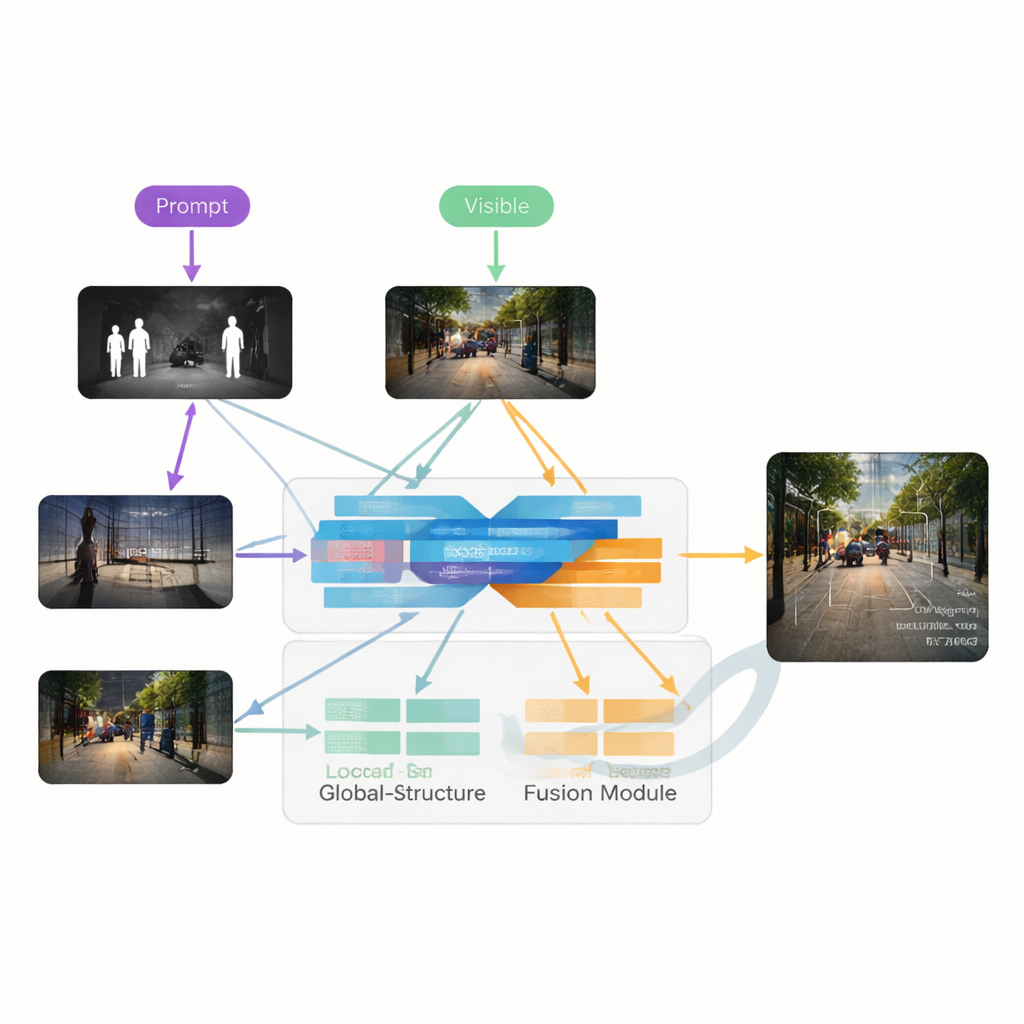
著者らはVGDCFusionという、新しい深層学習フレームワークを提案します。これは劣化処理を融合プロセス自体に組み込むものです。主要な考え方は、ネットワークにどのような問題が予想されるかを言葉で伝え、その知識を特徴抽出と融合の各段階で活用することです。短いテキストプロンプトはタスク(赤外–可視融合)や、低照度、露出過多、低コントラスト、ノイズなどの具体的な問題を記述します。CLIPのようなビジョン・ランゲージモデルがこれらのプロンプトをコンパクトな数値記述子に変換します。これらの記述子は二つの主要構成要素を導きます。すなわち、各モダリティごとに動作するSpecific-Prompt Degradation-Coupled Extractor(SPDCE)と、劣化の種類に配慮しつつモダリティ間で情報を融合するJoint-Prompt Degradation-Coupled Fusion(JPDCF)です。
誘導された融合プロセスの仕組み
各SPDCEモジュールの内部では、プロンプト由来の指示がネットワークを重要な特徴へと導き、アーティファクトから遠ざけます。マルチスケールの畳み込み層はエッジやテクスチャを保持するために局所領域を観察し、Transformer層はより大規模な構造や文脈を捉えます。これらは協働して、例えばノイズだらけの赤外フレームで重要な熱シグネチャを強調したり、露出不足の可視画像で淡い車線を際立たせたりしつつ、センサーノイズや照明の欠陥を抑制することを学習します。並行して、JPDCFモジュールは両ブランチからのクリーンアップされた特徴を受け取り、再びプロンプトに基づいてそれらを結合します。空間およびチャネル注意を用いて情報量の多い領域を強調し、残存する劣化をフィルタリングし、互いに補完する手がかり—たとえば歩行者の明るい赤外輪郭と可視カメラの色や背景構造—を合わせたうえで、三チャンネルの融合出力画像を再構築します。
手法の検証
有用性を実証するために、研究チームは低照度や露出過多の可視画像、ノイズや低コントラストの赤外画像を含む複数の公開データセットでVGDCFusionを評価しました。彼らはオートエンコーダ、畳み込みネットワーク、敵対的生成ネットワーク(GAN)、Transformerなど、幅広い最新融合手法と比較しました。標準的な画質評価尺度を用いた結果、VGDCFusionはエッジの鮮明さ、コントラスト、自然な色再現において一貫して優れた融合画像を生成しました。これは競合手法が入念に調整された前処理の利点を与えられた場合であっても同様でした。新しい手法は、著しく劣化したシナリオで主要指標を平均して約15%改善しました。さらに、生成した融合画像を一般的な物体検出システムに入力すると、赤外または可視単独、あるいは他の融合ネットワークを用いるよりも検出精度が高まることが示されました。
より安全なシステムのための明瞭な視覚
簡単に言えば、本研究は画像融合ネットワークに予想される視覚的問題を伝え、それを一体化したステップで修正・融合させることが、補正と融合を別々に扱うよりもクリーンで情報量の多い画像を生むことを示しています。劣化モデリングを融合プロセスに結びつけ、各層で言語による指示を使うことで、VGDCFusionは頻繁な人手による再調整なしに多様で混在した形式の画像劣化に適応できます。この種の劣化認識型の賢い融合は、自動運転車から監視カメラまで、実世界の混沌で不完全な条件下でも視覚システムがより確実に見通せるようにする助けとなるでしょう。
引用: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
キーワード: 赤外線と可視光の融合, 低照度撮像, ビジョン・ランゲージモデル, 画像劣化, 自動運転の知覚