Clear Sky Science · ja
マルチラベルテキスト感情検出のためのハイブリッド積み重ねアンサンブル学習フレームワーク
テキストから感情を読み取ることが重要な理由
日々、人々は感情をソーシャルメディア投稿、レビュー、メッセージに注ぎ込んでいます。この言葉の洪水の中には、メンタルヘルスの問題の早期警告、増加するヘイトスピーチ、危機や災害に対する世間の反応といった重要な兆候が隠れています。しかしコンピュータは多くの場合「肯定的」か「否定的」かしか判断できず、現実の人々がしばしば同時に表す複雑な感情の混在を見落としがちです。本稿では、一つのテキスト内で複数の感情を認識させる新しい方法を紹介し、それを英語だけでなく高度な人工知能の恩恵をほとんど受けてこなかった言語にも適用する手法を探ります。
単純な肯定・否定を超えて
従来の感情分析ツールは鈍い温度計のようなもので、ムードが良いか悪いかは示せても、怒り、恐れ、希望、安堵といった同時に存在する感情を区別することはできません。著者らは、このより豊かな感情のパレットを理解することが、災害対応、セラピー支援、カスタマーケアなどの用途で不可欠だと主張します。たとえば恐れと緊急性が混じったメッセージは即時の対応を要するかもしれませんし、悲しみと楽観が混じるメッセージは別の種類の支援を必要とするかもしれません。複数の感情を並列に捉える、いわゆる「マルチラベル」感情検出は、より敏感で人間に配慮したシステムへの重要な一歩です。
見過ごされてきた言語に声を与える
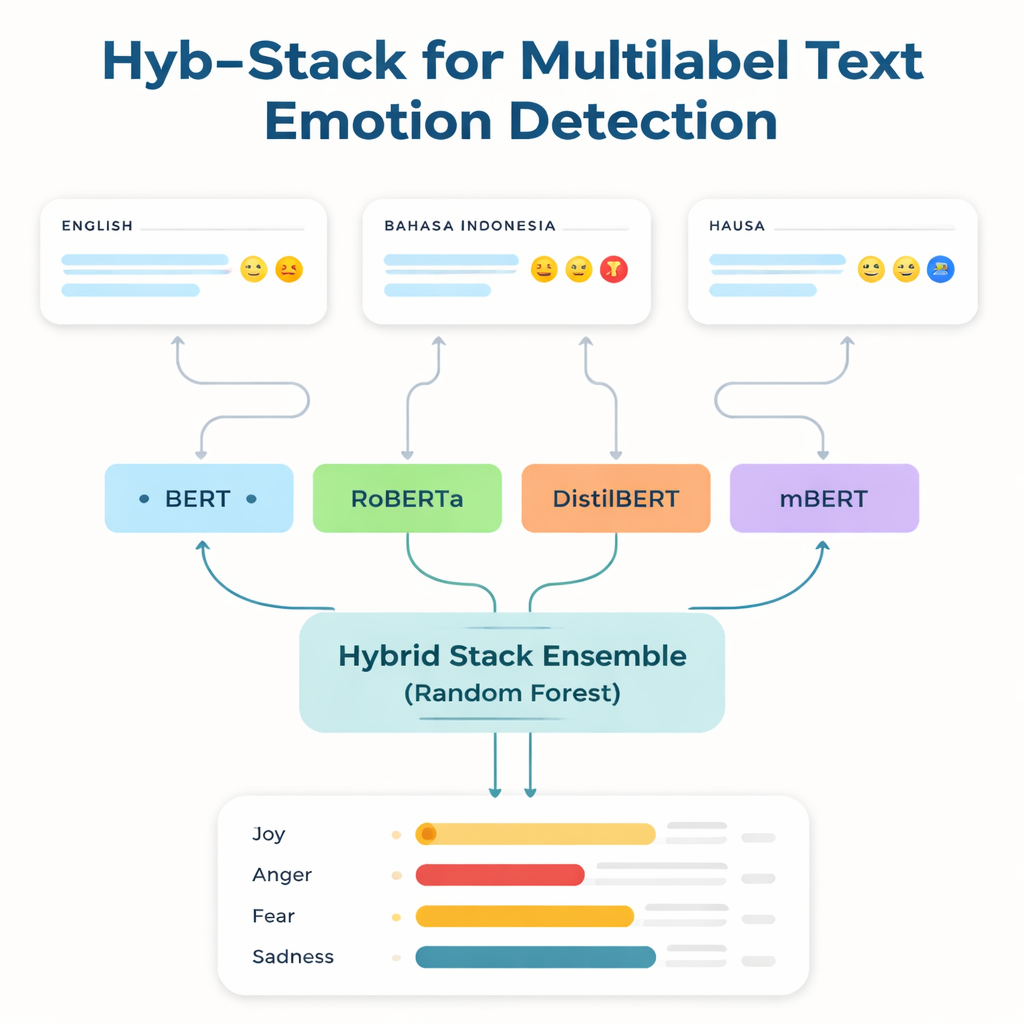
強力な言語技術の多くは英語や限られた主要言語で学習・調整されています。ラベル付きデータが少なくデジタルツールも乏しいリソースの少ない言語の話者はしばしば取り残されます。このギャップに取り組むため、研究者らは三つのデータセットに焦点を当てます:よく知られた英語の感情ベンチマーク、攻撃的・ヘイト発言に焦点を当てたインドネシア語(バハサ・インドネシア)コレクション、そして彼らが新たに作成したハウサ語のTwitterコーパスHaEmoC_V1です。ハウサ語データセットは一万二千件を超える厳密にクリーニングおよび注釈されたツイートを含み、各ツイートには怒り、喜び、信頼、悲観、予期など11種類の感情のうち一つ以上がタグ付けされています。専門のレビュワーがラベルを検査し、評価の一致度は注釈が一貫性と信頼性を備えていることを示しました。
複数の賢い読者を一つに結集する
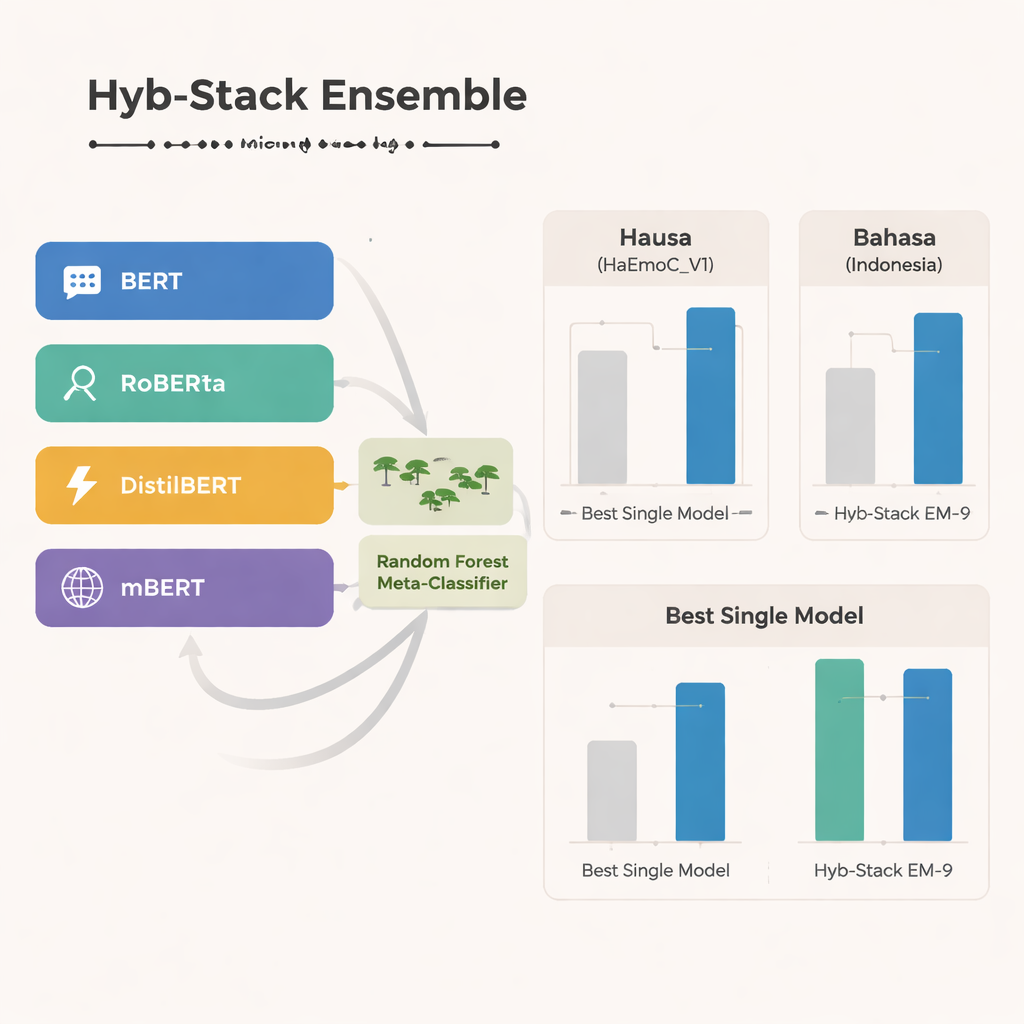
研究の中核にあるのはHyb-Stackと呼ばれるハイブリッド積み重ねアンサンブルで、言語に対する「専門家委員会」のようなものです。四つの高度なトランスフォーマーベースのモデル(BERT、RoBERTa、DistilBERT、そして多言語版のmBERT)がそれぞれテキスト中の感情信号を読み取るようファインチューニングされます。単一のモデルだけを信頼する代わりに、Hyb-Stackはそれらすべてに予測させ、各モデルの内部スコアを第二段階の意思決定器であるランダムフォレスト分類器に入力します。このメタ分類器は各モデルの強みをどう重み付けするかを学習し、感情の共起に関する複雑なパターンを捉えます。研究チームはまた、単純に予測を平均する手法や事前の性能で重み付けする手法など、より単純なアンサンブル方法もテストして、積み重ねが本当に有利かどうかを検証しています。
ハイブリッド手法の性能
三言語すべてにわたり、多言語モデルのmBERTは単独モデルとして特に優れており、特に新規作成されたハウサ語データやインドネシア語のヘイトスピーチセットで良好な成績を示しました。しかしハイブリッドアンサンブルはさらに上回ります。特にEM-9と呼ばれる組み合わせ(BERT、DistilBERT、mBERTをHyb-Stack内で統合したもの)は一貫して最良の結果を出しました。これは個別のモデルや単純な平均化手法より高いF1スコア(一般的な精度指標)を達成し、最大の改善はリソースの少ないハウサ語およびインドネシア語データセットで見られました。詳細な誤り分析では、残る誤分類は通常、喜びと驚き、悲しみと恐れのように近接する感情間で発生しており、これは明確なシステムの失敗というよりも人間の感情の自然なあいまいさを反映しています。
実世界のシステムにとっての意義
一般読者にとっての主要な結論は、複数のAIモデルを賢く組み合わせることで、特に長らく技術的に軽視されてきた言語において、テキスト中の感情をより正確に読み取れるようになるということです。高品質なハウサ語感情コーパスを構築し、ハイブリッドアンサンブルが単一モデルや単純な投票方式を上回ることを示すことで、著者らはより包括的で感情に配慮したツールへと向かう実践的な道を提示しました。今後の研究では、より微妙な感情の色合い、コードミックス言語、絵文字、さらに多くの過小評価された言語への適用を進め、人々がどの言語を話していても、単に幸せか悲しいかではなく、なぜそう感じるのかまで感知できるシステムの実現を目指します。
引用: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
キーワード: 感情検出, 多言語NLP, アンサンブル学習, トランスフォーマーモデル, リソースの少ない言語