Clear Sky Science · ja
高性能な倍精度ヴェーダ乗算器アーキテクチャの効率的な計算と設計
なぜ高速な数値演算が重要なのか
ビデオをストリーミングするとき、スマートフォンでナビゲーションを使うとき、あるいはAIが医用画像を解析するとき、専用のコンピュータハードウェアは静かに毎秒何十億という小さな計算を実行しています。これらの演算の大部分は「浮動小数点」数の乗算であり、3.14159のような実数をコンピュータが表現する標準的な方法です。本稿は、その中核コンポーネントの一つである、高速かつ省エネルギーな乗算器を構築するより賢い方法を探ります。着想は古代インドのヴェーダ数学にあり、それを現代のデジタルハードウェアに応用することで性能を向上させます。
古代の計算トリックから現代チップへ
浮動小数点演算はデジタル信号処理、画像処理、通信、深層学習アクセラレータの基盤です。標準的な乗算器は幅の広い二進ビット列(倍精度では64ビット)を扱う必要があり、チップ面積や消費電力を浪費せずに高速で動作しなければなりません。Booth法、Karatsuba法、アレイ乗算器などの従来手法は、速度、ハードウェア規模、設計の複雑さの間でトレードオフをとります。ヴェーダ数学はインドで発展した16の古典的算術規則を含み、その中の乗算手法「Urdhva Tiryakbhyam(垂直・斜め法)」は部分積を高度に並列に生成します。これにより中間段階と必要なハードウェアを減らせます。研究者たちはこれらの考えをデジタル回路に適用してきましたが、倍精度浮動小数点演算に用いるときには未だ冗長が残る設計が多くあります。
この新しい乗算器の特徴
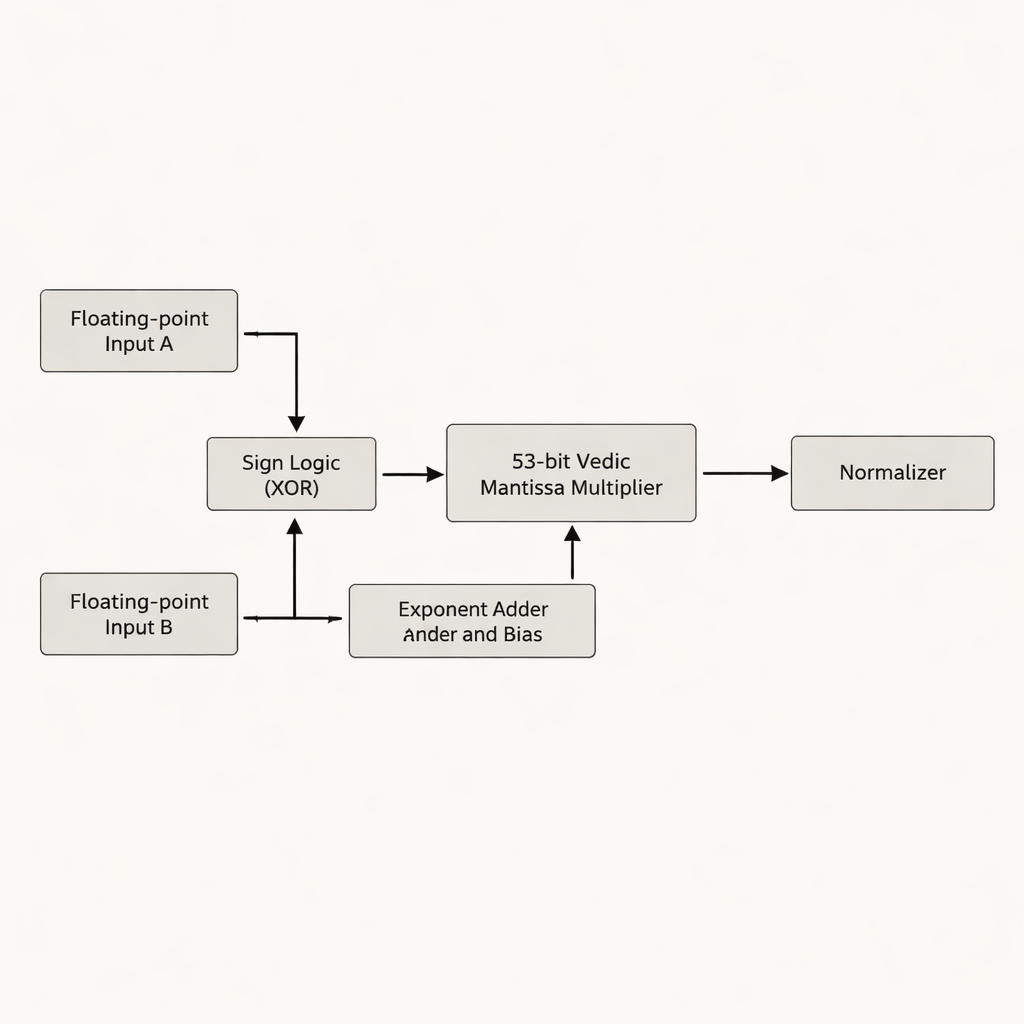
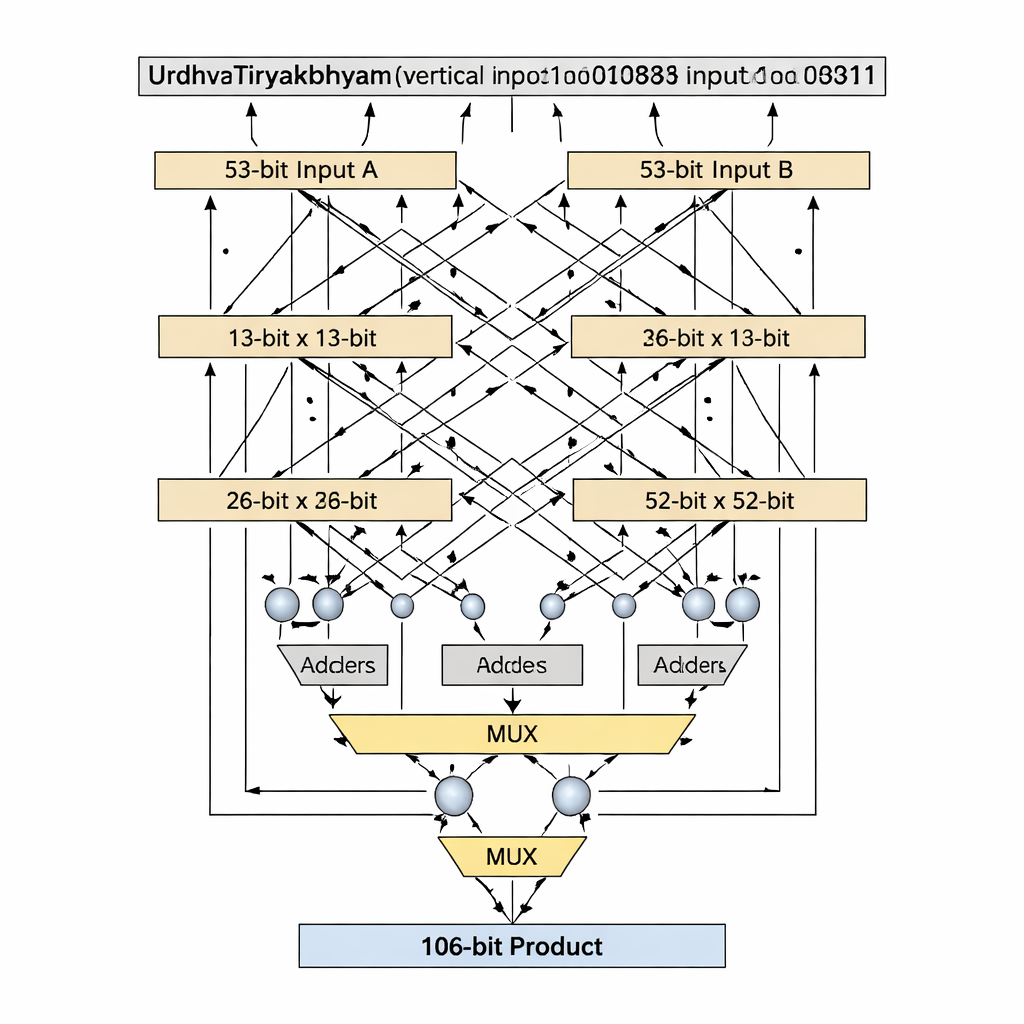
著者らは、浮動小数点数の有効桁を保持する仮数部(マンティッサ)に焦点を当てた倍精度浮動小数点乗算器を提案します。多くの従来設計が52ビットの仮数を54ビットにパディングするのに対し、彼らは実際の53ビット有効仮数を維持し、チップ上で余分なストレージや配線を消費する「空白」ビットを避けます。設計の核心はUrdhva Tiryakbhyamに基づく53ビットのヴェーダ乗算器で、より小さなブロックを階層的に組み合わせます:3ビット単位が6ビット単位を形成し、それが12ビット、13ビット、26ビット、52ビット単位となり、最終的に53ビット段に結合されます。アーキテクチャは符号計算、指数の加算とバイアス処理、仮数の乗算と正規化という3つの主要段階に仕事を分離し、IEEE-754浮動小数点標準に整合させつつ冗長な回路を削減します。
素数サイズのブロックでより洗練されたハードウェア
重要な革新は、13や53のような素数幅のビット長をどのように扱うかにあります。これらは等分割できないため、標準的なヴェーダ分解では扱いにくくなったり無駄が生じます。著者らは「素数ビット」アルゴリズムを導入し、小さめの(n−1)ビットのヴェーダ乗算器に加え、加算器、マルチプレクサ、そして単一の追加論理ゲートを巧みに再利用することで、パディングを行わずにnビット乗算器をエミュレートします。13ビット段では入力を1ビットと12ビットに分割し、12ビットのヴェーダ乗算器で部分積を作成し、最上位ビットに基づく条件選択(マルチプレクサ)と少数の加算器で構成します。同じ手法は52ビットコアを用いて53ビットへと拡張されます。この最適化により、信号が通過する最長の論理連鎖であるクリティカルパスが短くなり、論理素子数も抑えられます。
速度・面積・電力で得られた実測的な利得
設計はVerilogハードウェア記述言語で表現され、Vivadoツールを用いてXilinx Zynq FPGA上に実装されました。13、26、52、53、64ビットのヴェーダ乗算器の中で、提案する53ビットユニットは遅延、論理使用量(ルックアップテーブルやI/Oピン)、推定電力のバランスが良好でした。Booth法、Karatsuba法、その他のヴェーダ配置に基づく従来の倍精度乗算器と比較しても、新しいアーキテクチャは最悪ケースの遅延と必要なFPGA資源を大幅に削減し、周辺の浮動小数点回路に複雑さを追加しませんでした。仮数乗算が高速で論理深度が浅いため、スイッチング活動が減り、直接的な技術間の電力比較は難しいものの、電力–遅延積の改善が期待されます。
AIや信号処理への影響
実際の負荷で設計を検証するために、著者らは畳み込み演算が実行時間の大部分を占める畳み込みニューラルネットワークの畳み込みエンジンにヴェーダ倍精度乗算器を統合しました。従来のIEEE-754や以前のヴェーダ乗算器をこの新設計に置き換えると、畳み込みの遅延が短縮され、消費電力が低減し、推論時間が短くなり、分類精度は維持されました。デジタルフィルタリング、エッジ検出、医用画像処理など、計算負荷の高い他のタスクでも同様の利点が期待でき、高速な乗算器によりスループットが直接向上し、デバイスの放熱やバッテリー寿命の改善につながる可能性があります。
日常技術にとっての意味
平たく言えば、本稿はヴェーダ数学の巧妙な乗算法を借用し、それを現代の二進フォーマットに慎重に合わせることで、従来設計よりも小型で高速、かつ省エネルギーな乗算器を実現できることを示しています。この改良された基本ブロックはプロセッサ、信号処理チップ、AIアクセラレータに組み込めば、データ解析の高速化、応答性の向上、スマートフォンから医療用スキャナまでのシステムでの消費電力低減に寄与します。著者らはさらに、より低エネルギーを目指した可逆論理やより大きな処理単位への統合など今後の方向性も示しており、古代の算術と現代ハードウェアの結びつきは始まったばかりであることを示唆しています。
引用: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
キーワード: ヴェーダ乗算器, 浮動小数点演算, FPGA設計, デジタル信号処理, 畳み込みニューラルネットワーク