Clear Sky Science · ja
知的最適化と進化アルゴリズムによる擬似ランダム性テスターの境界サンプル生成
ほとんどランダムであることが日常のセキュリティに重要な理由
オンラインで買い物をしたり、スマートフォンを解除したり、個人的なメッセージを送るたびに、目に見えない数学的なサイコロがデータを守るために振られています。これらのサイコロは暗号鍵として使われる、いわゆる長い乱数ビット列の形をとります。もしそのビット列がほんのわずかでも期待されるランダム性を欠くと、巧妙な攻撃者は利用できるパターンを見つけてしまうことがあります。本稿は、極めてランダムに見えながら微小な欠陥を隠す「ほとんどランダム」なテスト列を人工的に作り出す新しい方法を探り、エンジニアが我々のデジタル生活を守る機器を厳密にストレステストできるようにすることを目的としています。
乱数が十分にランダムでないとき
現代のセキュリティシステムは、二種類の乱数生成器に依存しています。真の乱数生成器は電子雑音や量子ゆらぎなど予測不可能な物理現象に基づき、一方で擬似乱数生成器は短いランダムなシードを長い系列に変換するアルゴリズムを用います。実際には、どちらの品質も最終的にはエントロピー源と呼ばれる物理的な不確実性源に依存します。残念ながら現実のエントロピー源は脆弱で、温度変化、ハードウェアの経年劣化、設計上のミスにより静かにランダム性が低下することがあります。こうした問題を検出するために、NISTのような標準化団体は出力ビットが十分にランダムに見えるかをチェックする統計テスト群を定めています。デバイス側でも稼働中に自分の出力を監視する「リアルタイム乱数テスター」を組み込むことが増えています。しかし、組み込みチェッカーが本当に有効かを試すための、現実的で検出の難しい故障ケースを生成する良い方法はこれまでありませんでした。
ランダムテストにギリギリで失敗する列の設計
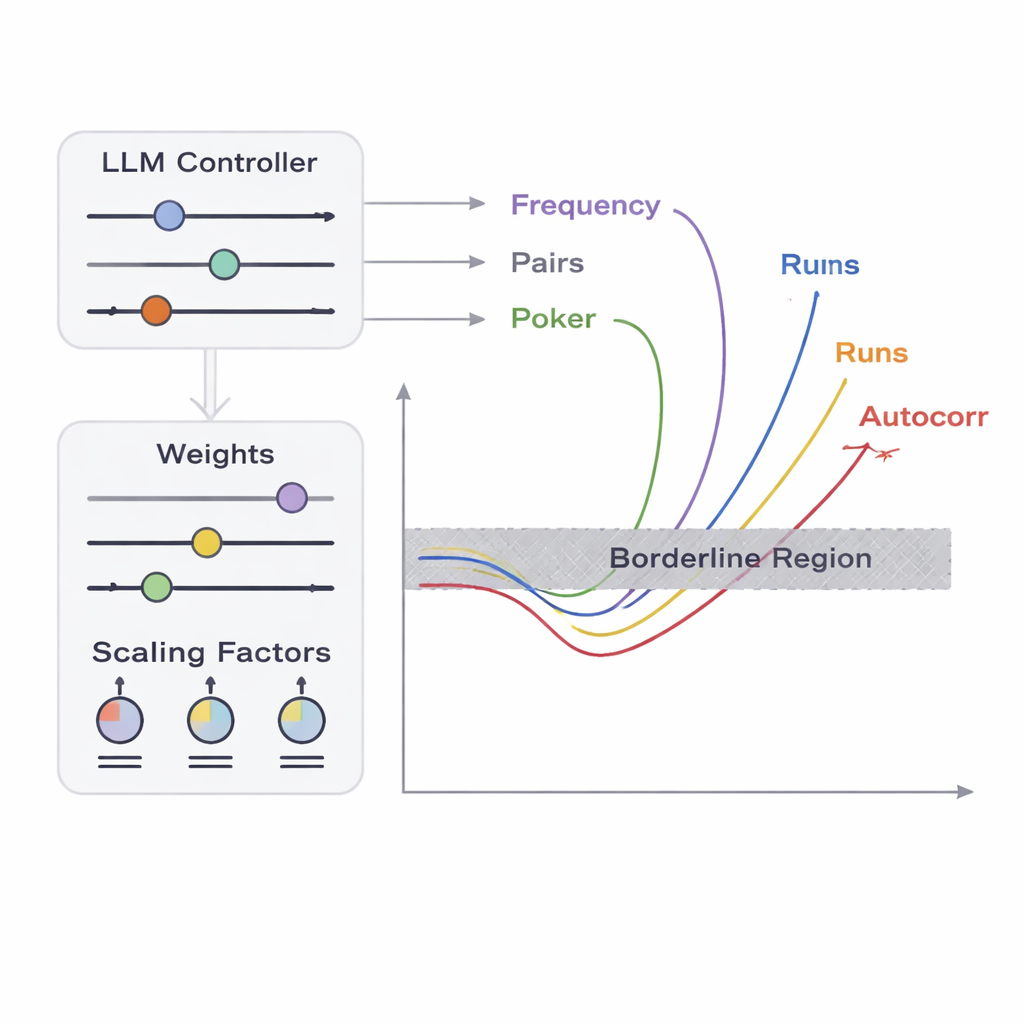
テスターの観点からすれば、出力がすべてゼロといった自明な失敗は容易に検出できます。本当の課題は境界ケースの検出です:理想的なランダム性とほとんど見分けがつかないが、ひとつまたは複数の統計検定で僅かに不合格になる系列です。著者らは、ゼロと一の出現頻度、ビットの対の振る舞い、短いパターンの分布、ビットとシフトされた自身との相関、同一ビットの連続長(ラン)の配列など、ビット列の異なる側面を見る5つの古典的テストに着目します。各テストに対して「境界ゾーン」を定義し、通常の受容閾値をわずかに破る狭い帯域を設けます。これらすべての狭い帯域に同時に長い系列が入る確率は、テスト同士が複雑で非線形に相互作用するため、偶然では極めて低くなります。ここで最適化とAIの出番です。
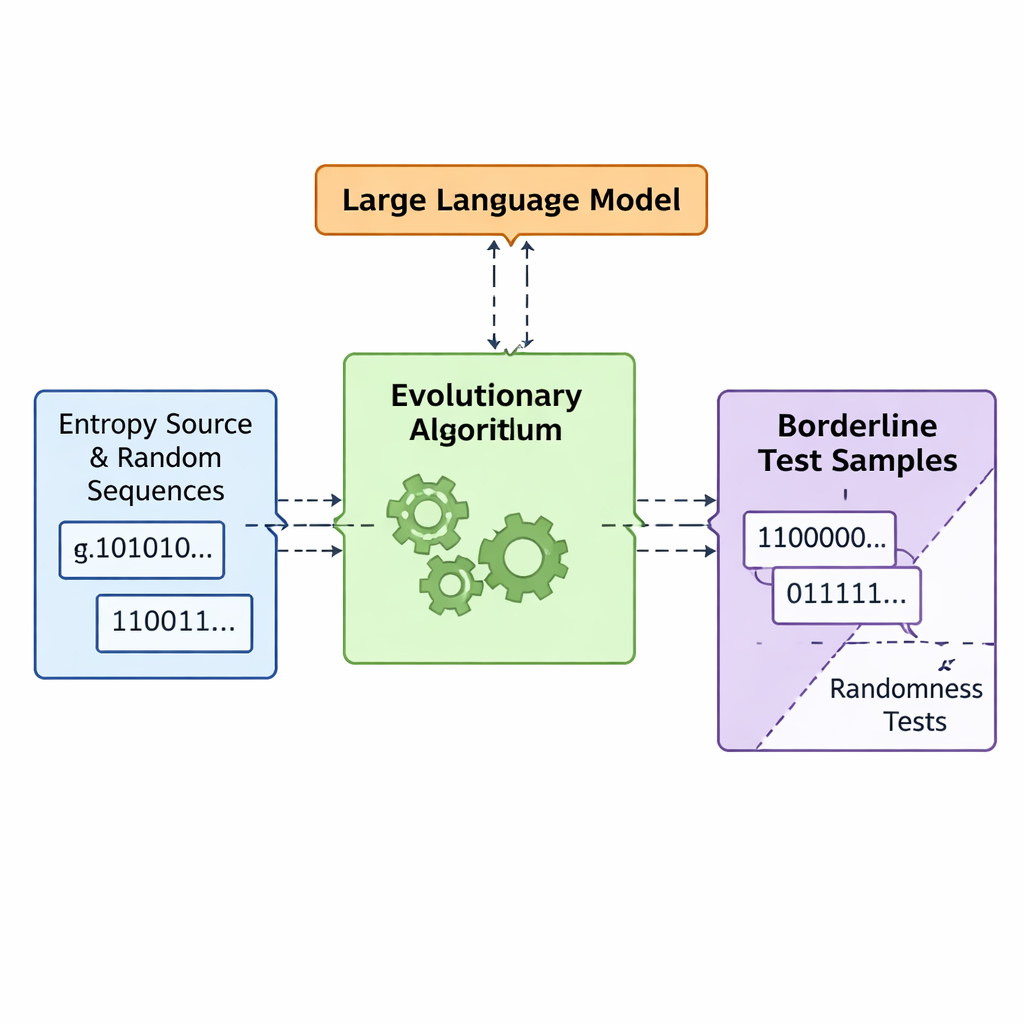
進化と言語モデルで“悪い”乱数を共同設計する
研究チームは、APAM‑IGLLMと呼ぶフレームワークを導入し、列生成を高次元の最適化問題として扱います。各候補列はビット列で、適合度(フィットネス)は5つのテストの境界ゾーンへどれだけ近づいているかを測る指標です。遺伝的アルゴリズムはこれらの列を繰り返し突然変異や組換えで変化させ、目標領域に近づく個体を保持します。その上で大規模言語モデル(LLM)が戦略コーチのように振る舞います。各世代で母集団の要約統計や短期の履歴を観察し、各テストが適合度に与える重みやスケーリング係数といった内部のつまみをどのように調整するかを提案します。これがフィードバックループを作り出します:遺伝的アルゴリズムが可能な列空間を探索する一方で、LLMが探索を誘導し、5つのテストスコアが微小な交差領域に向かって収束するようにします。そこが列がかろうじて非ランダムになる交差点です。
欠陥あるデータはどれほど完全なランダム性に近づけるのか?
人工的に作った欠陥が現実的に見えるかを確かめるため、著者らは生成列を広く用いられるベンチマークと比較します。各バイトの予測不可能性を測るシャノンエントロピーとミンエントロピーを計算すると、おおむねバイトあたり7.6〜8ビットの値になり、理論的最大の8ビットに非常に近く、商用のハードウェア乱数源やNISTの公開ランダムネスビーコンと類似しています。さらにNIST SP 800‑22の統計テスト群を実行すると、境界列は高品質な真の乱数データとほぼ同じパターンで合格・不合格を示します。言い換えれば、標準的なツールから見ればこれらのサンプルは本質的に通常通りに見えるが、実際には複数の失敗閾値の近傍に意図的に配置されるよう設計されています。これにより、組み込みの乱数テスターの堅牢性を検証するための理想的な“敵対的”入力となります。
実世界のセキュリティにとっての意義
一般的な観点から見ると、本研究は暗号の根幹を支える乱数生成機構を安全に検査する新たな手法を提示します。明らかに破損した乱数や明らかに健全な乱数だけでデバイスを試験するのではなく、エンジニアは微妙なハードウェア故障や環境変化を模した、巧妙に作られたほとんど正常な系列で機器を叩くことができるようになります。もしリアルタイム乱数テスターがこれらの境界ケースを見逃すなら、それは銀行業務、セキュア通信、ブロックチェーンシステムなどに配備される前に修正すべき潜在的な盲点を示します。進化的探索を言語モデルで誘導することで、著者らはこのような要求の厳しいテストデータを生成する実用的なツールを提供し、デジタルセキュリティの見えない基盤の信頼性向上に寄与します。
引用: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
キーワード: 乱数生成器, エントロピー源, 進化的アルゴリズム, 大規模言語モデル, 暗号テスト