Clear Sky Science · ja
比較的蒸留によるノイズラベルの補正:ドメイン適応アプローチ
なぜデータの乱れが増えているのか
現代の人工知能はデータを基盤として成り立っていますが、そのデータはしばしば誤りや欠落、ラベルの不整合を含んでいます。例えば猫の写真に誤って「犬」というラベルが付くと、学習システムは誤導され、精度や信頼性が低下します。本稿はその現実的な問題に取り組みます。つまり、訓練ラベルが不完全で、トレーニング画像がオンラインストアのような環境と実世界の写真のような異なる環境から来る場合でも、画像認識システムをうまく学習させる方法です。
異なる世界をまたいだ学習
実務では、モデルはラベルが丁寧に確認された「ソース」領域で学習し、ラベルが乏しく誤りを含みやすい「ターゲット」領域で性能を発揮しなければなりません。たとえば、スタジオで撮影されたオフィス用品は整っていて正しくラベル付けされる一方、ウェブカメラや日常の写真は乱雑でラベルが不揃いです。従来のドメイン適応手法は、両領域の統計を合わせることでこのギャップを埋めようとしますが、ターゲットのラベルが利用可能な場合でも正しいと仮定することが多く、クラウドソーシングのタグ、低品質センサ、自動注釈ツールのある実用環境ではその仮定は危険で破綻しがちです。
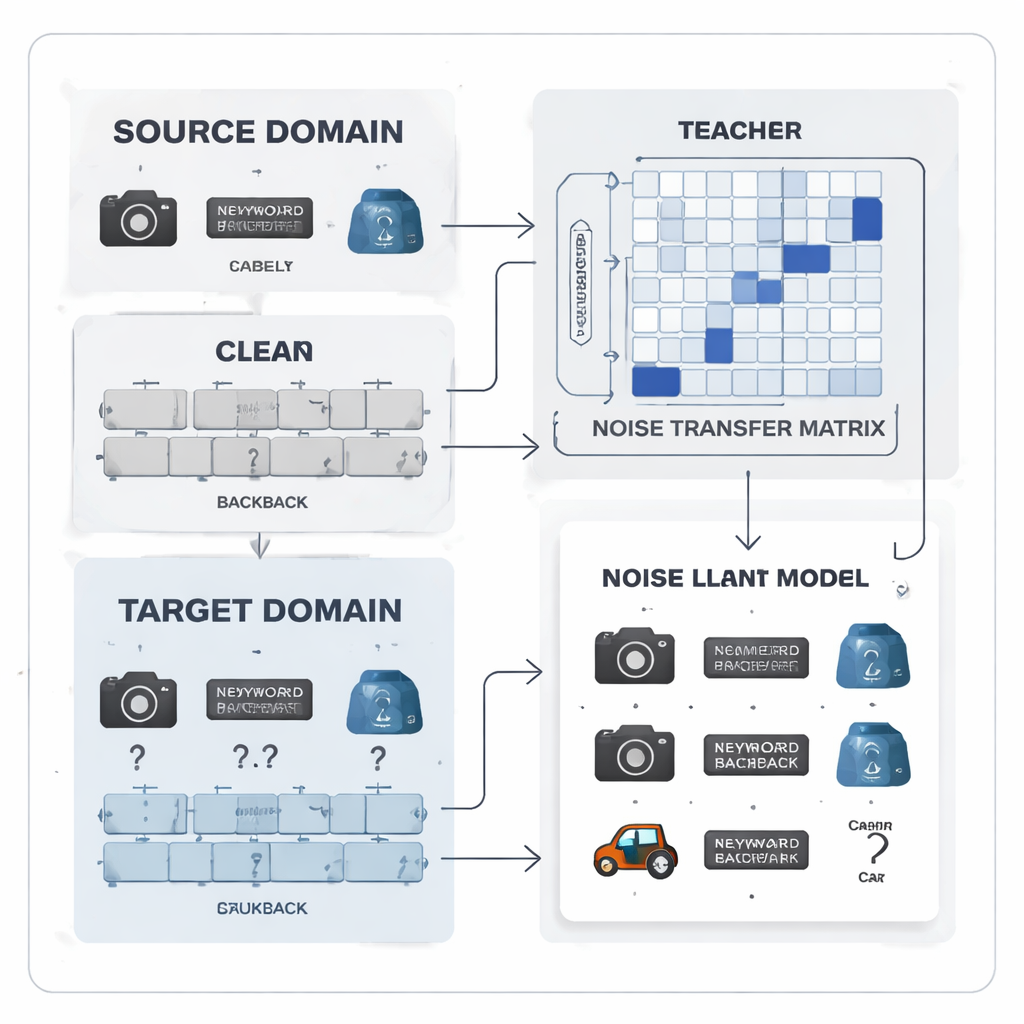
ラベル誤りを学習可能なパターンに変える
著者らはラベルノイズを無秩序な乱れとして扱うのではなく、学習可能なパターンとして扱うことを提案します。彼らは「ノイズ転送行列」を導入し、各真のクラスが他のクラスに誤ラベルされる確率を捉えるテーブルとして表現します。少数の完全な“アンカー”例からこの行列を推定するのは、ラベルがノイズを含みクラス分布が不均衡な状況では現実的ではないため、この行列は訓練中に直接学習されます。学習を始めるために、方法はカテゴリごとの「プロトタイプ」、つまり強力な事前学習済みモデルで抽出された各クラスの平均的な特徴の指紋を構築します。これらプロトタイプ間の類似性を用いて行列を初期化することで、たとえば類似したオフィス用品のように混同しやすいカテゴリが初期段階から強く結び付けられ、システムが早期にラベルを訂正する能力を獲得します。
教師–生徒の連携でよりクリーンな信号を得る
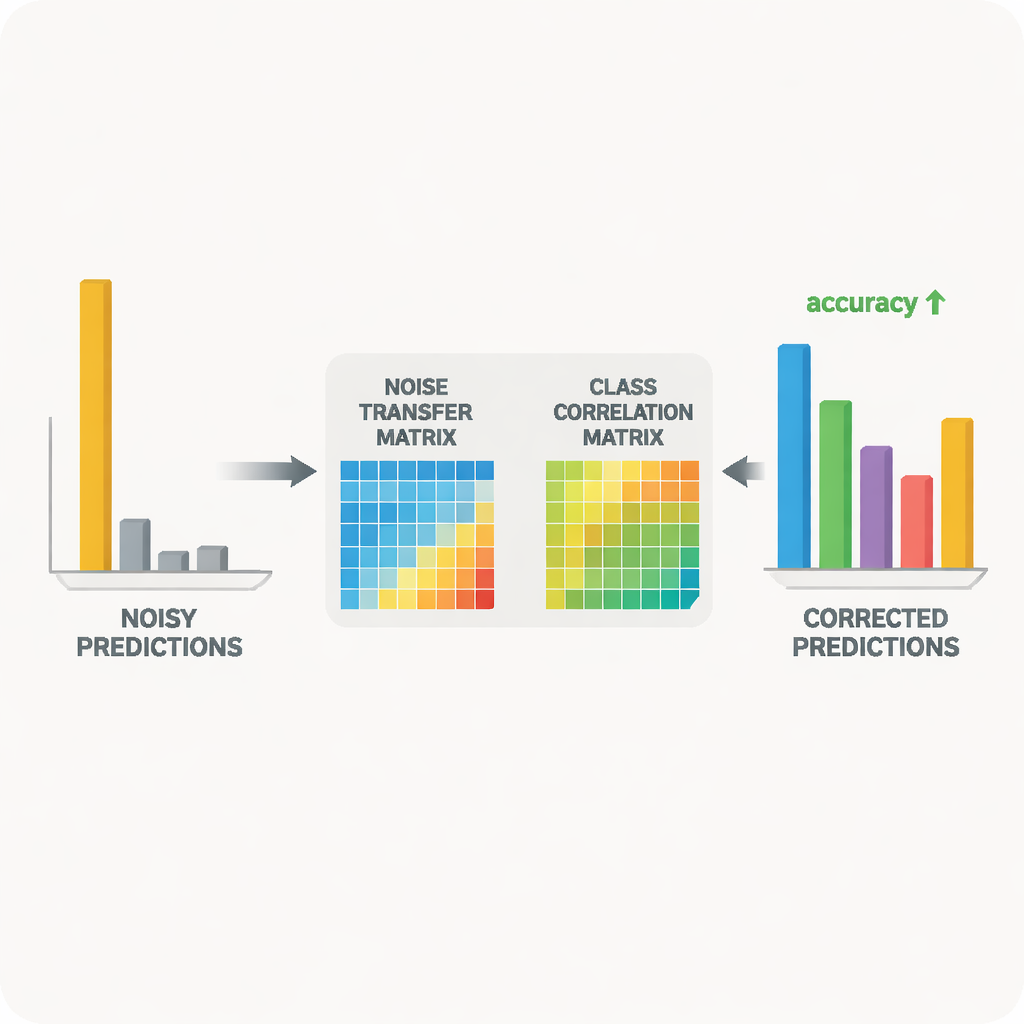
システムの中心は教師–生徒のニューラルネットワークペアです。教師は大量のラベルなしデータから豊かな視覚特徴を学んだ大規模な自己教師あり視覚モデルに基づきます。生徒はノイズのあるターゲットデータでよく動作することを目的とした軽量ネットワークです。教師はクラス間の関連性を示すソフトな予測スコアを出力し、そこからどのラベルが共起しやすいかを要約するクラス相関行列を構築します。この行列はガイドとして機能し、ノイズ転送行列をより現実的な訂正へと導きます。同時に、生徒は蒸留として知られる過程を通じて教師の振る舞いに合わせて訓練され、コントラスト学習は同一画像の異なる増強ビューに対して両ネットワークが類似した内部表現を与え、異なる物体には区別された表現を与えるよう促します。
訂正の安定化と過信の回避
ノイズ転送行列を自由に変化させるだけでは、それが不安定になったり外れ値に過敏になったりする危険があります。これを防ぐために、著者らは特異値分解に基づく数学的手法を用い、行列を基本的な伸縮方向に分解します。これらの方向が示す全体の“体積”を罰則することで、ノイズを増幅するような極端な歪みを抑制します。もう一つの問題は、モデルが自己確信を持ちすぎてほとんどの確率を単一のクラスに割り当ててしまうことです。そのような鋭い予測では誤ったラベルを調整しにくくなります。これに対処するため、手法はツァリス(Tsallis)エントロピーに基づく一種のエントロピー正則化を追加し、予測確率をより滑らかに保ちます。これにより、ノイズ転送行列が誤ったクラスからより妥当な候補へ確率質量を部分的に再割り当てしやすくなります。
実際の画像集合での有効性の実証
研究者らは、この手法をクロスドメイン物体認識のために広く使われる2つのベンチマーク、Office‑31 と Office‑Home で検証しました。これらは商品写真、クリップアート、実世界のスナップショットなど複数のスタイルにわたる日常のオフィス用品の画像を含みます。「あるスタイルで学習し別のスタイルでテストする」各種タスクにおいて、本手法は特にドメイン間のシフトが大きく最も困難なケースで、主要なアルゴリズムと同等かそれ以上の性能を示しました。詳細な解析により、ノイズ行列の体積制御、クラス相関によるガイド、エントロピー平滑化という各構成要素がそれぞれ測定可能な改善をもたらしていることが示されました。学習された行列と特徴空間の可視化は、訓練が進むにつれて誤ラベルされた例が徐々に正しいカテゴリへ引き寄せられ、ソースとターゲットの画像分布がよりよく整合していったことを裏付けました。
日常のAIシステムにとっての意義
非専門家にとっての主要な結論は、この研究が実験室の整った条件からより乱雑な実世界の環境へ移行する際に、人的・機械的なラベル誤りに対してAIモデルをより寛容にする点です。ラベルがどのように誤るかを明示的に学習し、強力な教師モデルを使って修正を導くことで、手法はノイズのある学習信号を浄化し、より正確で堅牢な分類器をもたらします。追加の計算コストは必要ですが、本手法は“野生”で収集された大規模かつ不完全なデータセットをより安全かつ効果的に活用できる未来を示しており、手作業による煩雑な注釈への依存を減らす道を指し示します。
引用: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
キーワード: ノイズのあるラベル, ドメイン適応, 知識蒸留, 画像分類, 半教師あり学習