Clear Sky Science · ja
連続制御強化学習のためのラムダ下側信頼限界を持つリスク感受性ツイン分布批評家
ロボットに慎重さを教える
今日最も優れたロボットやゲームプレイ用プログラムの多くは、試行錯誤で報酬を集めながら学習する強化学習に依拠しています。しかし、これらのエージェントはしばしば最大得点を追い求めるあまり、意思決定のリスクを無視しがちで、その結果学習が不安定になったり、時折クラッシュを招いたりします。本稿で提案する手法TDC-λ(Twin Distributional Critics with a Lambda Lower Confidence Bound)は、単に高い目標を追うだけでなく、学習中に一貫して安全性を保つことをエージェントに教えます。
学習マシンにおける安定性が重要な理由
TD3やSoft Actor–Critic(SAC)のような標準的な連続制御アルゴリズムは、複雑なシミュレータ内でロボットを走らせたり跳ばせたりバランスをとらせたりすることを可能にしてきました。しかし、これらの手法は通常、各行動を長期的に得られる報酬の単一の推定値で評価します。その単純なスコアは、学習過程にノイズがあるときに誤導されやすく、特定の行動の価値を過大評価してしまうことがあります。その結果、平均的には良好に見えても実行ごとに大きくぶれる学習曲線になり、物理マシンや安全性が重要なシステムに同じアルゴリズムを適用する際には問題になります。
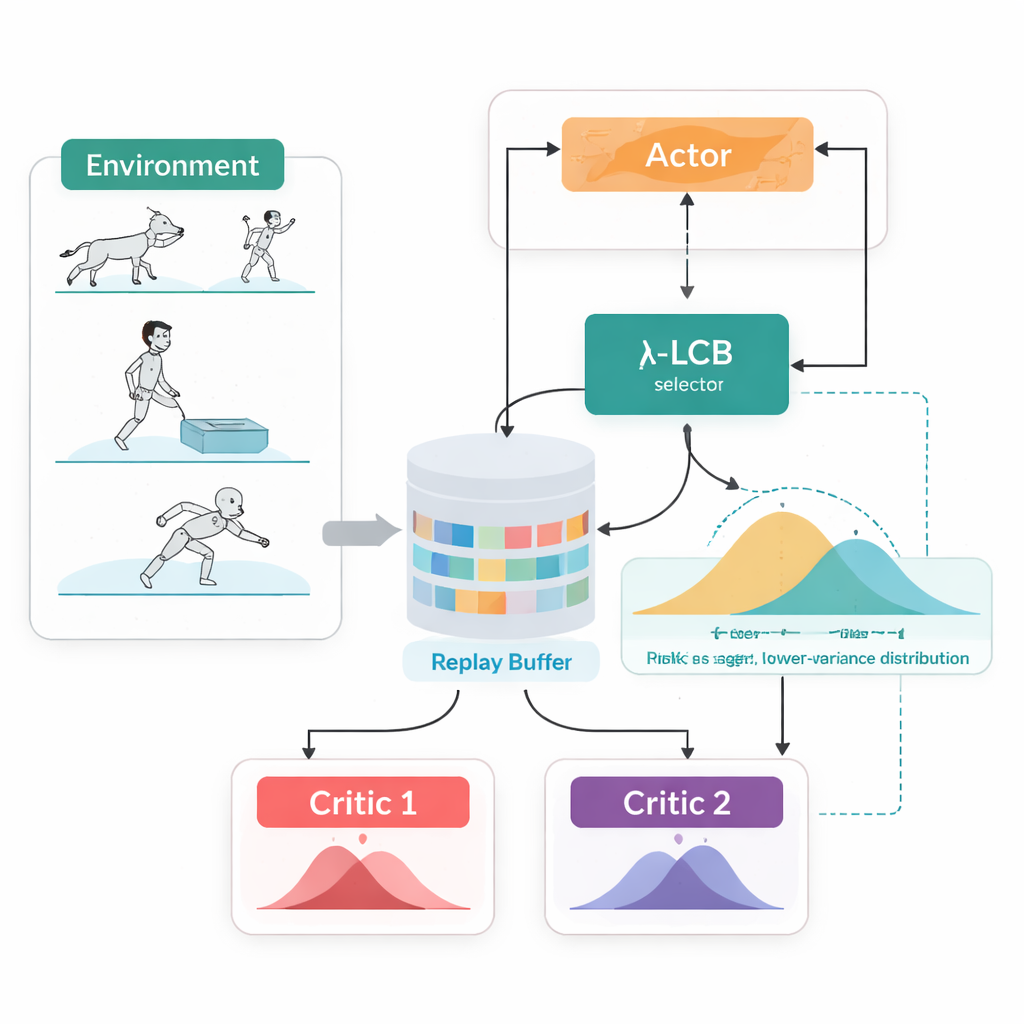
単一の数値ではなく、未来の分布を観る
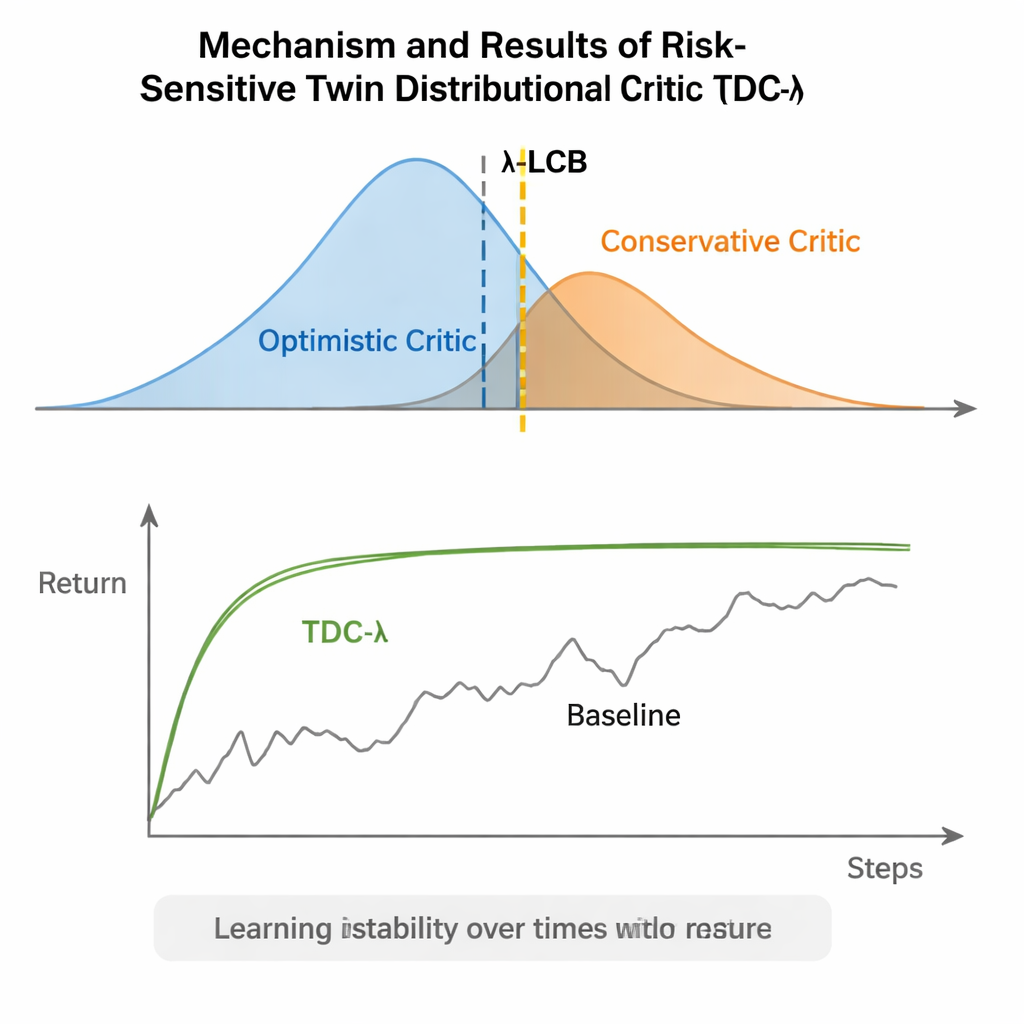
TDC-λは、エージェントが将来を評価する仕方を変えることでこの問題に対処します。各行動について単一の期待報酬を予測する代わりに、完全な将来のリターン分布を出力する2つの独立した「批評家」を学習します。これらの分布から、アルゴリズムは平均的な結果だけでなく、可能性がどれだけ広がっているか(ばらつき)も計算します。そのばらつきは不確実性やリスクを反映します。下側信頼限界という単純なルールを用いて、TDC-λはより安全な結果を予測する批評家を好みます。これはわずかに楽観性が低いかもしれませんが、より一貫した証拠に支えられた予測です。1つの設定パラメータであるリスクパラメータλは、この慎重さの度合いを滑らかに調整します。λが0のときは従来のTD3風の振る舞いに近く、λが大きくなるほど保守的になります。
1つの学習ループで、2つの行動選択
TDC-λの実用的な特徴の一つは、決定的な行動選択と確率的(サンプリング)な行動選択の両方を単一の統一された枠組みでサポートする点です。学習中は、古典的な決定論的方策か、tanhで押し潰したガウス方策(行動をサンプリングして探索を促進)を選べます。どちらを選んでも、ツイン分布批評家の学習は同じ方法で行われ、評価時は常に決定的な平均行動が使われます。この設計は、テスト時に決定論的挙動がサンプリングよりも同等かそれ以上の性能を示すことが多いという先行知見を活かしつつ、学習時には探索に富んだ方策を許すものです。
手法の実地検証
著者らはTDC-λを、HalfCheetah、Hopper、Ant、Walker2d、Humanoidといった模擬ロボットが効率的に動くことを学ぶ必要のある5つの代表的なMuJoCoベンチマーク課題で評価しました。これらのタスク全体で、本手法はTD3、DDPG、SAC、ならびに流量ベースの先進的手法MEOWなど強力なベースラインと同等かそれ以上の最終性能を達成しつつ、繰り返し実行した際のばらつきが一貫して小さいことを示しました。Humanoidのようなより難しく高次元のタスクでは、やや大きめのλ(より慎重な目標推定)が最も良い長期リターンと最も狭い性能幅をもたらしました。PyBulletやNVIDIA Isaacといった他のシミュレータでの追加実験や、学習信号の変動を追跡する診断でも、TDC-λが学習を遅くすることなく安定化させるという知見が強化されました。
より安全な学習のための簡単な調整つまみ
日常的に言えば、TDC-λはエージェントが自己の楽観性をどれだけ信頼するかを決める際に「安全マージン」を与えます。可能な結果の完全な分布を学習し、λというつまみでより安全な批評家に傾くことで、アルゴリズムは学習中の大きな振幅を抑えつつ高い最終性能を維持します。実務者にとっては、学習の不安定さに応じて中程度に保守的なλから始めて調整することで、ロボットや他の連続制御システムのより信頼できるコントローラを構築する実用的な手段を提供します。広い意味でのメッセージは、エージェントが何を学ぶか(学習目標)を注意深く形作ることが、複雑なアーキテクチャに帰せられがちな堅牢性の多くをもたらし、高度な強化学習をより安定的かつ扱いやすくするという点です。
引用: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
キーワード: 強化学習, 連続制御, リスク感受性学習, 分布的批評家, ロボティクス