Clear Sky Science · ja
歯科専門試験における大規模言語モデルの成績比較解析
将来の歯科医にとって賢いチャットボットが重要な理由
人工知能は医師や歯科医の学習と職務のあり方を急速に変えています。最も目に見えるツールの一つが、大規模言語モデルを基盤とする会話型チャットボットであり、多くの人気あるAIアシスタントと同じ技術です。本研究は単純だが重要な問いを立てました:歯科学生がこれらのツールを用いて口腔顎顔面放射線学の競争の激しい専門試験に備えた場合、機械は実際にどれほど良く回答できるのか?
実際の試験でAIを検証する
その答えを得るために、研究者たちはトルコの歯科専門化入学試験(DUS)に注目しました。この試験は高度研修プログラムへの進学者を決めるものです。全国試験の過去問題から、放射線物理や画像取得法から顎の腫瘍や副鼻腔疾患に至るまで、放射線専門医が習得すべき分野を網羅する208問の択一問題を選びました。大部分は文章問題でしたが、より小さい割合で放射線画像の解釈を必要とする問題も含め、実臨床の診断業務を反映しています。
7つのチャットボットが同じ試練に挑む
次に、研究チームは各問題をトルコ語で、異なる大規模言語モデルに基づく広く使われている7つのAIチャットボットに提示しました:ChatGPTの2バージョンに加え、Gemini、Copilot、DeepSeek、Claude、Grokです。会話間の影響を避けるため、各質問は慎重に個別に入力されました。別の研究者が各AIの回答を公式解答と比較し、正誤を判定しました。最後に、著者らは標準的な統計検定を用いてモデル全体および各科目別の比較を行いました。
誰が最も高得点で、どこでつまずいたか
全体では、ChatGPT 4.0が際立っており、約91%の正答率を示しました。CopilotとGeminiが続き、中〜高80%台の精度でした。一方、ChatGPT 4.5、DeepSeek、Claude、Grokはやや劣後しました。分野別に見ると、口腔病理や唾液腺疾患では特に成績が良く、正答率は90%近くあるいはそれを超えることもありました。対照的に、放射線解剖学や軟部組織の石灰化は明らかに難易度が高く、システム全体の得点を押し下げており、AIが細かな詳細を扱う際の苦手分野を示唆しています。
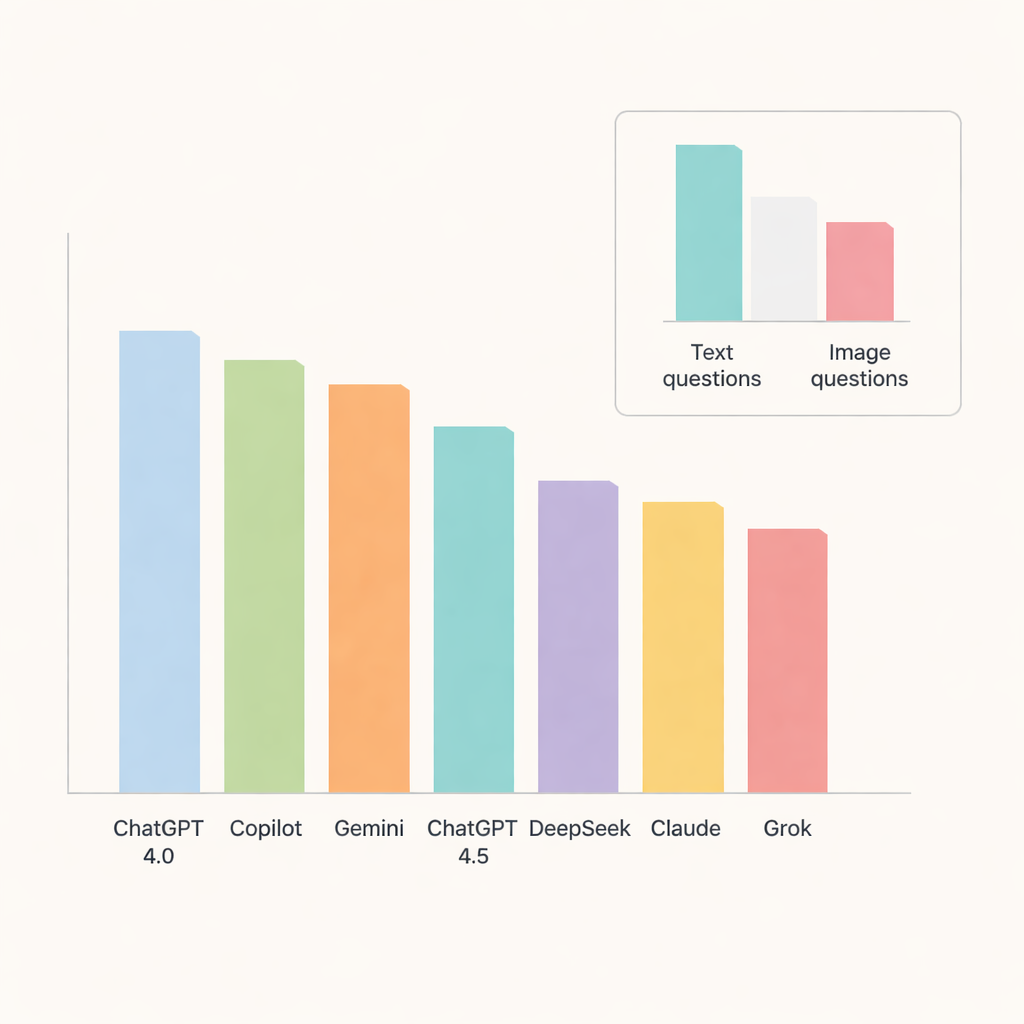
画像は依然として文章より難しい
重要な検証は、チャットボットが画像を文章と同等に扱えるかどうかでした。ここで限界が明確になりました。画像ベースの問題では正答率が急落し、上位のモデルでさえ影響を受けました。ChatGPT 4.0、Gemini、Copilotがこのカテゴリをリードしましたが、視覚問題に対しては約3分の2しか正解できませんでした。DeepSeekは画像問題で最も成績が悪く、正答率は3分の1強にとどまりました。多くのモデルで文章問題と画像問題の差は統計的に意味のあるほど大きく、医療画像の解釈が現状の汎用AIにとって依然として難題であることを裏付けています。
学生と患者にとっての意義
本研究の要点は、現代のチャットボットが歯科教育において強力な補助となり得ること、特に放射線学の事実確認や試験形式の問題演習に有用である点です。しかし、最も優れたシステムでさえ、視覚的に負担の大きい問題や高度に専門的なトピックで十分な精度を欠くことがあり、専門家の判断に安全に取って代わるには至りません。学生や臨床家にとって、これらのツールは単独の権威ではなく、賢い学習パートナーや意思決定支援として位置づけるのが適切です。適切な注意と監督のもとで使用すれば、学習を加速し高品質な説明へのアクセスを広げる可能性がありますが、最終的な診断と治療の責任は訓練を受けた専門家にあることに変わりはありません。
引用: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
キーワード: 歯科教育, 人工知能, 大規模言語モデル, 口腔顎顔面放射線学, 医療試験