Clear Sky Science · ja
ビデオ連続映像における暴力検出のための軽量畳み込みニューラルネットワークアーキテクチャ
人が見張らなくても済む群衆の監視
コンサートやスポーツアリーナから地下鉄の駅やショッピングモールに至るまで、カメラはほぼあらゆる混雑した空間を監視しています。それでも多くの映像は疲れた人間の目で監視されており、喧嘩や踏みつぶしの初期兆候を見逃しがちです。本稿は、低コストのハードウェア上でもリアルタイムにライブ映像をスキャンし、暴力行為を検出できるスリムで高速な人工知能の仕組みを検討し、事態が制御不能になる前に警備員が迅速に対応できるようにする方法を探ります。
ビデオで暴力を見分けるのが難しい理由
一見すると、コンピュータに「喧嘩」と「非喧嘩」を判別させるのは簡単に思えます:人が殴り合っているのを検出すればよい。しかし実際には問題は複雑です。照明が悪かったり急に変化したりすることがあり、群衆が視界を遮ったり、カメラが様々な角度に設置されていたりします。満員のロックコンサートは危険なことが起きていなくても混沌として見え、ボクシングの試合は暴力的に見えてもリングの中では通常の光景です。従来のビジョンシステムはフレームごとの手作りの動きパターンやエッジを見ていましたが、実験室では機能しても現実の過密な監視ネットワークではしばしば遅すぎたり不正確だったりしました。
カメラ映像向けのより洗練された“脳”
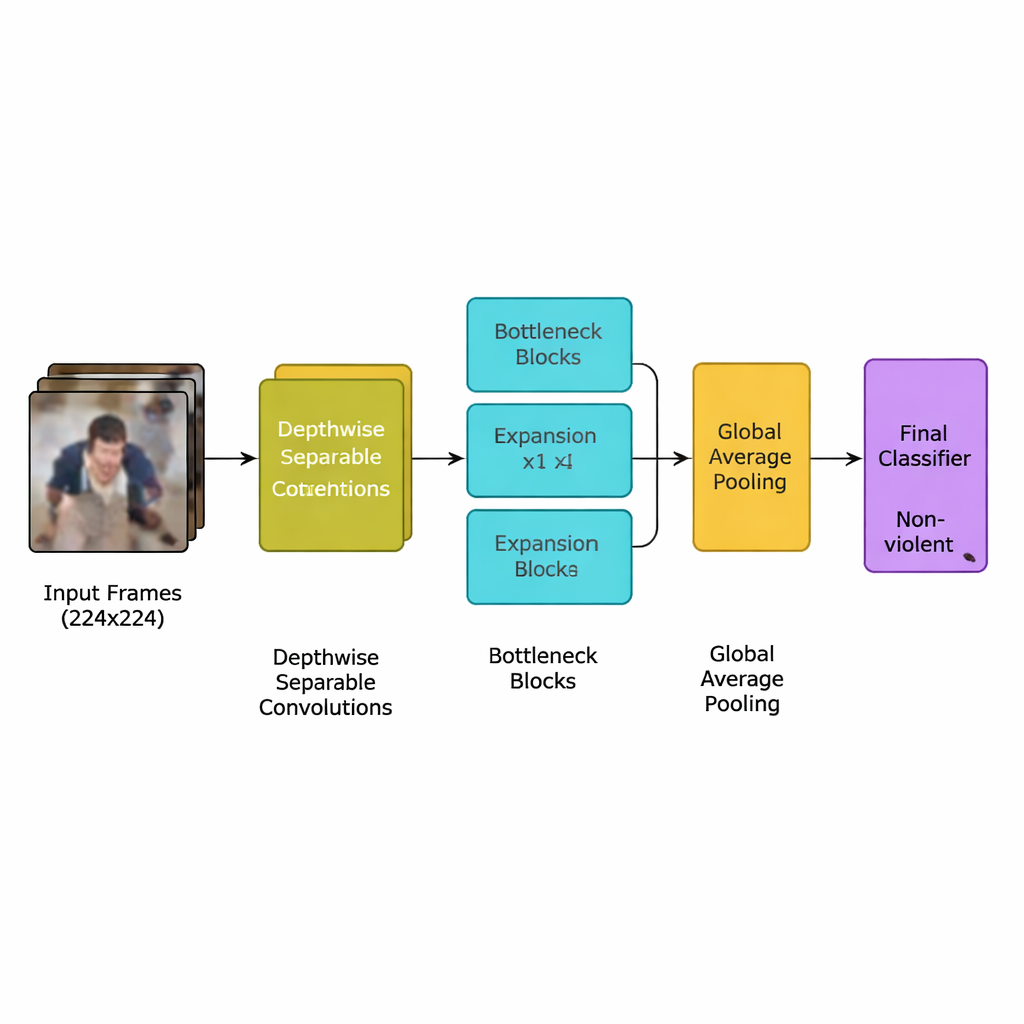
著者らはこの課題専用に設計された新しい深層学習モデル、効率的なモデル群であるMobileNetV2に由来する軽量畳み込みニューラルネットワーク(CNN)を提示します。高性能なグラフィックスプロセッサを必要とする重い層を多数使う代わりに、このネットワークは深さ方向に分離された畳み込み(depthwise separable convolution)を利用し、計算量を大幅に削減する小さく標的を絞った演算を行います。また、「インバーテッドボトルネック」ブロックを用いて、情報を一時的に拡張してから圧縮し、冗長性を落としつつ重要な動きの手がかりを保持します。これに加えて、空間的・時間的に暴力事件に典型的な動きパターンにネットワークの注意を向け、背景の雑音を無視するのに役立つsqueeze-and-excitationと呼ばれる注意機構を組み込んでいます。
生の映像から暴力アラートへ
システム全体は明確なパイプラインに従います。まず映像ストリームをフレームに分割し、ほぼ重複するフレームを取り除きつつ喧嘩を示す突然の動きを保持するために5フレームに1フレームだけを残します。フレームは標準の224×224ピクセルにリサイズされ、背景ノイズを減らすために軽くぼかされ、トレーニング時にはランダムに反転や回転が加えられて異なるカメラ視点に対処できるようにします。こうして準備された画像は軽量CNNに入力され、生のピクセルが徐々に群衆行動のより高次のパターンへと変換されます。各フレームを要約する最終的なプーリングステップの後、小さな分類器が単純な判断を出します:暴力か非暴力か。モデルは約194万パラメータしか使用しないため(MobileNetやMobileNetV2の系譜より少ない)、遠隔のデータセンターではなくカメラ近くに置かれた控えめなデバイス上でリアルタイムに動作できます。
システムの実地試験
このコンパクトな設計がより大きなネットワークと競えるかを確かめるため、研究者らは2つの広く使われるベンチマークで訓練・評価を行いました。Real‑Life Violence Situations DatasetはYouTubeから収集した2000本の短いクリップを含み、日常の場面とさまざまな場所での実際の喧嘩の両方を示します。Hockey Fight Datasetはプロのアイスホッケー試合の1000本のクリップを収録し、通常のプレーとリンク上の乱闘に分かれています。これらのデータセット上で、提案モデルは実生活シナリオで約97パーセント、ホッケー映像で94パーセントのクリップを正しくラベル付けし、InceptionV3やVGG‑19などのより大きなCNNと同等またはそれを上回る性能を、はるかに少ない計算で達成しました。2つのデータセット間で交差テスト(片方で訓練して他方でテスト)を行っても、システムは依然として合理的に良好な性能を示し、一つの環境を丸暗記するのではなく一般的な動きパターンを捉えていることが示唆されました。
日常の安全性に与える意味
非専門家にとっての主な結論は、巨大なサーバや常時の人手を必要とせずに、手早く安価に暴力の可能性を自動的に検出するカメラシステムを構築できるようになったということです。研究は、注意深く剪定・調整されたニューラルネットワークが多数の映像ストリームを同時に監視し、危険な行動を検出した際にアラートを送信でき、公共交通のハブ、学校、病院、都市の通りに適した低消費電力ハードウェア上で動作し得ることを示しています。非常に暗いシーンや過密状態の処理、音声手がかりの追加など課題が残る一方で、本研究はスマートカメラが疲れ知らずの早期警報センサーとして機能し、人間の監視者の負担を減らしながら保護をより効果的にする未来を示しています。
引用: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
キーワード: 暴力検出, ビデオ監視, 軽量CNN, MobileNetV2, 公共の安全