Clear Sky Science · ja
ユーザー行動に基づくDNSフィンガープリント
なぜあなたのウェブ訪問は見えない痕跡を残すのか
ウェブを閲覧するたびに、あなたのコンピュータはドメインネームシステム(DNS)と呼ばれる一種の住所録に静かに各サイトへの経路を尋ねます。その問い合わせは消えてしまうわけではありません。日々や週単位で蓄積されると、どの種類のサイトをいつどれくらい頻繁に訪れているかというパターンを形成します。本稿は、これらのパターンが行動的フィンガープリントとして十分に特徴的であり、強力なアルゴリズムがユーザーを識別できること――たとえ表示上のIPアドレスが変わっても――を示し、セキュリティの機会と深刻なプライバシー上の疑問の双方を提示します。
インターネットの電話帳とあなたの習慣
DNSは、人間にとって読みやすいウェブアドレス(例:www.google.com)を、コンピュータ同士が通信するために用いる数値のIPアドレスに変換するために存在します。多くの人は意識しませんが、検索、動画のストリーミング、メールの確認、アプリの更新などのたびに1件以上のDNSクエリが発生します。これらのクエリは通常、ローカルや公共のDNSサーバで処理され、単純な記録として記録されます:どのIPアドレスがどのドメインをいつ問い合わせたか。これらの記録を十分に集めれば、業務ツールやクラウドストレージからソーシャルネットワークやストリーミングまで、ユーザーが頼っているオンラインサービスの詳細な図が得られます。従来の研究はこれらの痕跡を使ってマルウェアの検出やデバイス種別の特定を行ってきましたが、本研究はより直接的な問いを投げかけます:繰り返されるDNS行動だけで個々のユーザーや端末を特定できるのか?
日々のクリックを行動フィンガープリントに変える
著者らは、ある地域のインターネットプロバイダから3か月間にわたって収集された大規模で公開可能なDNSデータセットを基に構築しています。毎日、彼らは各アクティブIPアドレスのDNS活動をコンパクトな要約に集約します:総クエリ数、問い合わせた異なるドメイン数、そして重要な点として、そのドメインが「一般的なビジネス」「ソフトウェア/ハードウェア」「ソーシャルネットワーキング」など75のコンテンツカテゴリのどれに分類されるかの割合です。各IPアドレスは少なくとも80%の日で出現するものだけを残し、ユーザーごとに十分な履歴を確保し、冗長またはほとんど空の特徴は慎重に取り除きます。さらに、統計手法を用いて高度に相関する項目を検出し、極端なクエリ量の外れ値を除外した後、主成分分析でデータを圧縮して、有用な変動の大部分がはるかに少ない次元で保存されるようにします。t‑SNEと呼ばれる手法でクリーンなデータを可視化すると、多くのIPアドレスが密で明確に分離したクラスタを形成することがわかり――自動分類が実現可能である初期の兆候となります。
機械学習モデルを試す
この処理済みデータセットを用いて、研究チームはユーザー識別を大規模な分類問題として取り扱います:ある日のDNS統計が与えられたとき、それが1,727のIPアドレスのどれに属するかを判定するのです。彼らはNaive BayesやRandom Forestのような古典的手法から、XGBoostや深層ニューラルネットワークのようなより高度な手法まで一連のモデルを比較します。各モデルはデータの異なるバージョン(生データ、再スケーリング、標準化、次元削減など)で学習・検証され、正しいクラスに割り当てられる頻度や精度・再現率の指標で評価されます。従来型のモデルもそこそこ良好に機能し、Random Forestは約73%の精度に達し、XGBoostは81%を超え、全クラスの99%以上を正しく区別します。しかし、特に優れているのはニューラルネットワークで、特徴ベクトルを日々の行動を表す一次元の画像のように扱うカスタムの畳み込みニューラルネットワーク(CNN)が目立ちます。
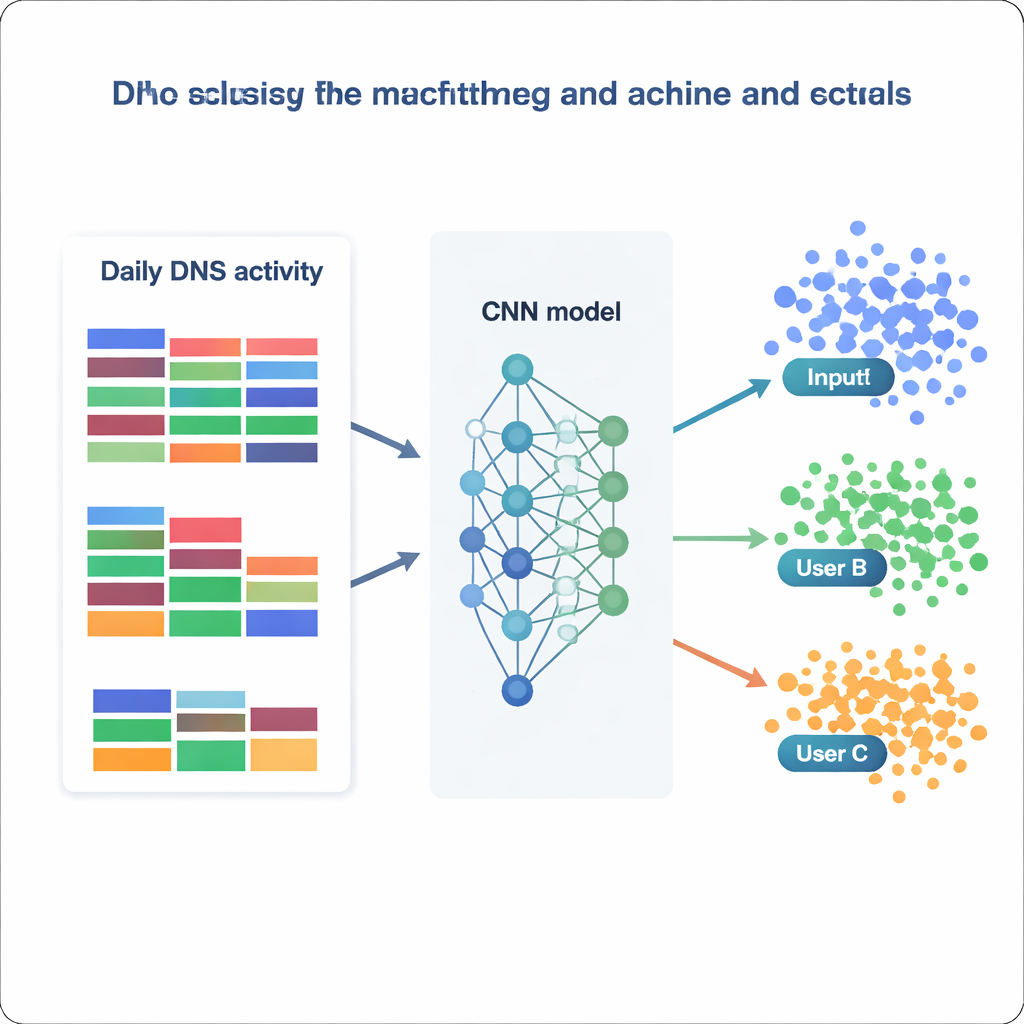
モデルはどこまで「あなた」を知り得るか?
正規化データで学習した最良のCNNは、保持データの日においてほぼ87%の確率で送信元IPを正しく識別し、1,727のうち1,694の異なるIPアドレスを正しく予測します。実務的に言えば、これは大多数のユーザー――あるいは共有IPの背後に隠れた小規模なグループ――が時間を通じて安定した認識可能なDNSパターンを示すことを意味します。モデルが最も依存する特徴を詳しく調べると、補完的な2つの戦略が見えてきます。あるモデルは一般的なビジネスやソフトウェアサービスのような非常に一般的なカテゴリに大きく依存し、広い習慣を捉えます。他方、XGBoostのようなモデルは、セキュリティや政治、ニッチな関心事に結びつくまれなが示唆的なカテゴリから追加の識別力を得ます。これらを合わせると、ドメイン名の完全な一覧を参照しなくても、単純に集計した統計量だけでユーザーを驚くほど高い信頼度で再識別できる構造が符号化されうることが示されます。
有望性、限界、そしてプライバシーへの影響
法執行機関やネットワーク防御者にとって、DNSフィンガープリントは、再犯者の追跡、乗っ取られた機器の発見、IPアドレスを頻繁に変えてブロックを回避するボットネットの検出といった作業に有用なツールとなり得ます。一方で、本研究は明確な限界も浮き彫りにします:DNSフィンガープリントは、パブリックIPが単一のユーザーに結びつく場合に最も安定しており、これは多くのユーザーがNATを介して1つのアドレスを共有する現在のIPv4環境よりも、個別のアドレスが割り当てられることの多いIPv6の方が現実的です。DNSサーバの頻繁な切り替えや公共Wi‑Fiの利用も信号を弱めます。最も重要なのは、こうした追跡が通常のユーザーには見えにくい重大なプライバシーリスクを孕んでいる点です。DNSのログ取得は大半が不可視かつ受動的に行われるため、クッキーや侵襲的なスクリプトをインストールしなくても行動追跡が起こり得ます。著者らはデータセットとモデルを公開しており、透明な研究が必要だと主張して、DNSベースのフィンガープリントによるセキュリティ上の利益と黙示的な監視の可能性を社会が天秤にかけ、どのような保護策や方針がこの強力なオンライン識別手法を制御するべきかを決めるべきだと論じています。
引用: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
キーワード: DNSフィンガープリンティング, ユーザー追跡, インターネットのプライバシー, ネットワークセキュリティ, 機械学習