Clear Sky Science · ja
深層マルチラベル学習におけるプラグアンドプレイ型ラベル相関強化モジュールの研究
タグが多すぎる問題を機械に教える
オンラインストア、法務アーカイブ、医療データベースはいずれも、新しい文書に迅速に適切なラベルを付けるソフトウェアに依存しています。しかし現代のシステムは、製品カテゴリから医療トピックまで数万、あるいは数百万にも及ぶ可能なタグに直面することが多く、各テキストに必要なのはごく少数のラベルだけです。本論文はLabel Correlation Enhancement Network(LCENet)という新しい付加モジュールを提案します。既存の深層学習モデルが、実データにおいてラベルが自然に共起するパターンをよりよく利用できるようにし、テキストタグ付けの精度向上と高速化をもたらします。
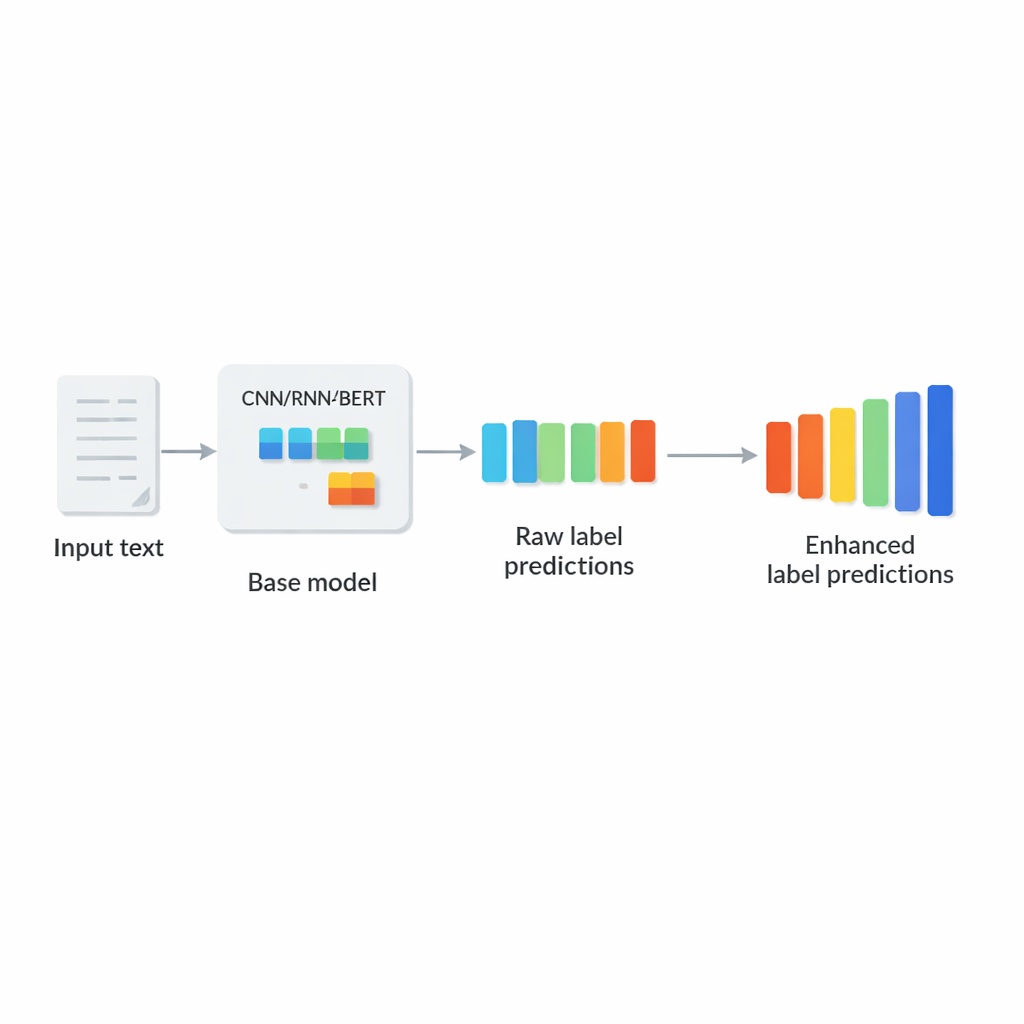
ウェブ規模のラベリングが難しい理由
多くの実用例は研究者が「極端マルチラベルテキスト分類」と呼ぶ領域に入ります:短い説明や長文から、膨大なラベルカタログの中から少数の関連ラベルを選ぶ必要があるのです。例として、ECサイトの商品にカテゴリを割り当てる、医学論文にMeSH語を付与する、広告をウェブページにマッチングする、法令文書を詳細な法コードにマッピングする、といった用途があります。これらはいずれも三つの共通課題を抱えます:ラベル数が非常に多いこと、多くのラベルが稀であること、そして各テキストが使うラベルは少数に限られることです。従来手法は問題を多数の小さな分類器に分割したり、ラベルを低次元ベクトルに圧縮したりしますが、単純な単語出現数に頼ることが多く、意味やラベル間の関係性を十分に捉えられないことがしばしばあります。
標準的な深層モデルがいまだ見落としている点
CNNや再帰ネットワーク、BERTのようなTransformerベースのモデルなど、近年の深層学習アプローチは豊かな意味表現を学ぶことでテキスト理解を大きく改善しました。それでもほとんど全てのモデルは最終段階で重要な簡略化を行います:テキストをベクトルにエンコードした後、各ラベルを独立に予測してしまうのです。しかし実際にはラベル同士は強く相互作用します。例えば「糖尿病」とタグ付けされた医学論文は「インスリン抵抗性」も関係している可能性が高く、「スマートフォン」とタグ付けされたガジェットは通常「電子機器」や「通信機器」と関連します。これらのパターンを無視すると、高信頼のラベルが弱いラベルを支援することができず、矛盾した組み合わせを出力してしまうことすらあります。
ラベル関係を学習するプラグイン
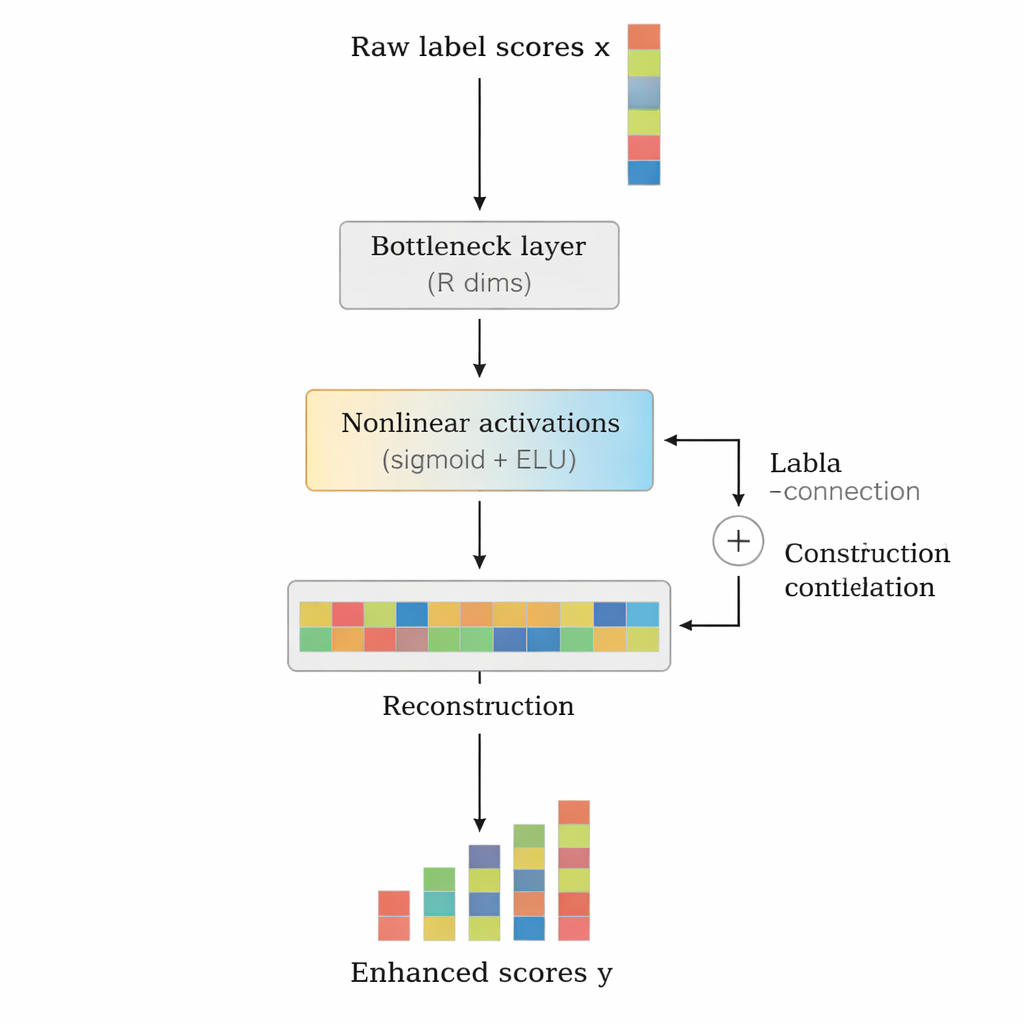
著者らはLCENetを、既存の任意の深層テキスト分類器の後段に置ける軽量なプラグアンドプレイモジュールとして提案します。ベースモデルのテキスト読み取り方法は変更せず、まず出力される生のラベルスコアを受け取り、それらをコンパクトな“ボトルネック”に通します。そこでは関連ラベルが近くに集まるような低次元表現の発見が強制されます。非線形活性化関数によって、単純な2項間の結びつきだけでなく複雑な高次の関連も捉えられます。残差(スキップ)接続が元のスコアを修正後の出力に直接渡すため、学習が安定し、モジュールが容易に性能を悪化させることがないように設計されています。重要な点として、LCENetは追加パラメータ数の増加をラベル数の2乗で増えるようなものから、より扱いやすい線形増加へと抑えるため、数十万のラベルがある場合でも現実的に運用できます。
モデルとデータセットを横断した有効性の立証
LCENetの汎用性を検証するため、著者らはそれをCNN系やBERT系のアーキテクチャを含む4種類の異なる深層モデルに組み込み、さらに生物医学や極端ラベル向けに設計されたシステムにも適用しました。評価は3つの公開ベンチマークデータセットで行われました:欧州の法務コーパス(EUR-Lex)、Amazon商品データ(AmazonCat-13K)、および50万を超えるラベルを持つ大規模なWikipediaコレクション(Wiki-500K)です。全モデル・全データセット・順位重視の6つの評価指標にわたり、LCENetは一貫して性能を改善し、最大規模データセットではトップ1精度を5ポイント以上引き上げたこともありました。学習曲線からは、ラベル相関構造の導入により初期からより明確な学習信号が得られるため、所定の精度に到達するために必要な訓練ステップ数がほぼ半分になることが多いことも示されました。
日常システムにとっての意義
既に深層モデルを用いてテキストにタグ付けを行っている実務者にとって、LCENetはシステムを再設計したり新しい注釈を収集したりすることなく、精度と学習速度を実用的に向上させる方法を提供します。ラベル空間自体を知識源と見なし、どのタグが共に現れやすいか、あるいは互いに排除し合うかを学び、予測をそれに応じて調整します。テキスト向けに開発されたものですが、出力間の学習された関係を用いて予測を強化するという同じ考え方は、画像やマルチモーダルデータ、その他の構造化予測タスクにも適用可能です。端的に言えば、LCENetは機械がラベルの関係を“記憶”するのを助け、孤立したチェックボックスのように推測するのではなく、概念の結びつきを理解した人間のように推測できるようにします。
引用: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
キーワード: 極端マルチラベルテキスト分類, ラベル相関, 深層学習, テキスト分類, ニューラルネットワーク