Clear Sky Science · ja
DMSCA: 畳み込みニューラルネットワークにおける特徴表現強化のための動的マルチスケールチャネル空間注意機構
コンピュータにより良い注意の向け方を教える
現代の画像認識システムは猫や交通標識、スキャン画像中の腫瘍を検出できますが、画像内部のどこに注目すべきかを常に正しく判断できるわけではありません。本稿では、これらのシステムが画像の最も重要な部分に集中できるようにする新しい手法を示し、精度を高め現実世界の雑多な条件下でも信頼性を向上させます。Dynamic Multi-Scale Channel-Spatial Attention(DMSCA)と呼ばれるこの手法は、既存の畳み込みニューラルネットワークに組み込めるもので、画像の「何(what)」と「どこ(where)」をより賢く把握できるようにします。
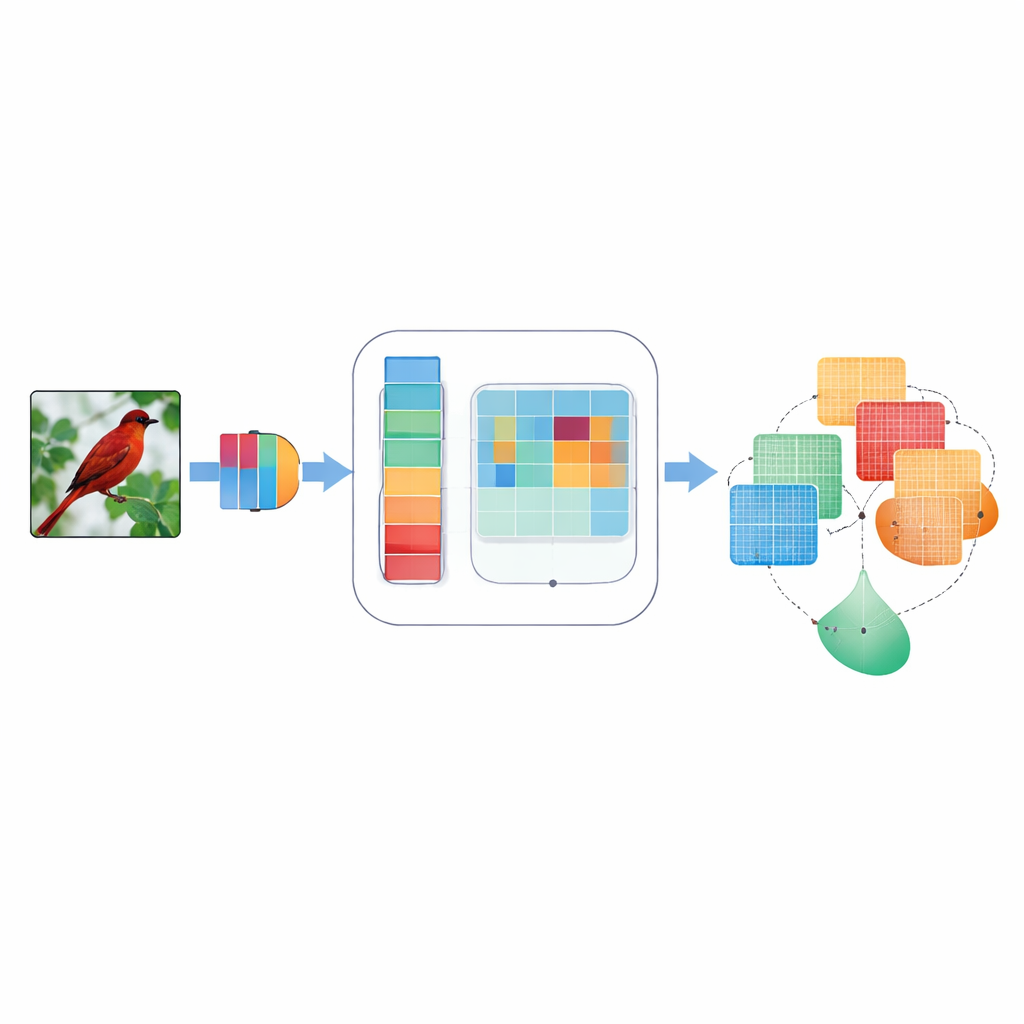
なぜフォーカスが機械視覚で重要なのか
多くの視覚アプリケーションを支える畳み込みニューラルネットワークは、内部の信号を等しく重要だと扱いがちです。そのため、鳥の羽のかすかな縁と空の一部が同程度に扱われることがあり、種の識別に役立つのは前者だけの場合がある、という問題が生じます。従来の「注意」手法は、チャンネルに沿ってあるいは画像の二次元配置に沿って内部信号の重み付けを試みましたが、多くは固定的で手作りのルールに依存したり、単一スケールの情報しか見なかったり、画像ごとに適応できない硬直した結合を用いていました。その結果、微細なディテールを見落としたり、「水平対垂直」のような方向性を無視したり、画像がノイズやブレを含むときに扱いにくくなることがありました。
より賢い注意の付加モジュール
DMSCAは小さな付加モジュールとして設計され、ResNetのような既存のニューラルネットワークに全体構造を変えずに挿入できます。内部には、孤立して働くのではなく協調して動作する6つの密接に結合されたパートがあります。あるパートは画像全体を要約して大域的な状況を捉え、別のパートは各内部チャネルがどれほど重要かを学習します。ここでは、必要に応じて判断を鋭くしたり緩やかにしたりできる制御可能な「温度」パラメータを用います。空間側では複数のウィンドウサイズを同時に使って微細なテクスチャから大きな形状までを捉え、長いエッジや縞模様が埋もれないように水平・垂直方向に明示的に注意を払います。最後に、単にこれらの信号を足し合わせるのではなく、ピクセルごとにチャネル由来の「何」情報と空間由来の「どこ」情報のどちらをどれだけ信頼するかを学習します。
多スケールと多方向で画像を見る
画像のどこを見るべきかを把握するために、DMSCAはまず多くの内部チャネルを圧縮して、背景の傾向と目立つ特徴の両方を強調するコンパクトな二層マップにします。そのマップを複数の並列フィルタ(異なるサイズ)に通します。小さなフィルタは毛や羽のような微細なディテールをとらえ、大きなフィルタは頭全体や体などの形状を捉えます。同時に、方向性ユニットが行(横)と列(縦)を別々に走査して重要な構造の正確な位置を保持します。これらの水平・垂直ビューは互いに作用しあえるようにされており、例えば強い垂直信号が適切な水平位置を強化できます。その結果、ネットワークに対して何が重要かだけでなく、それがどこにありどのスケールで重要かを伝える豊かな注意マップが得られます。
何が最も重要かをネットワークに決めさせる
画像の部位によって異なる戦略が必要になるため、DMSCAはチャネル情報と空間情報を組み合わせる際に固定のレシピを課しません。代わりに、小さな「ゲート」を構築して両者を検討し、各ピクセルごとにどちらの重みをどれだけ与えるかを決定します。背景が雑然としている場合は目立つチャネルにより依存し、鮮明な物体の縁では空間手がかりを重視するかもしれません。最後の適応的活性化段階は学習された調光スイッチのように機能し、真に有益な領域を増幅し残存ノイズを減衰させます。この多段階プロセスにより、強調領域が物体に関連した一貫した領域へと導かれることが、可視化されたヒートマップや強調領域と正解オブジェクトとの一致度の定量的評価によって確認されます。
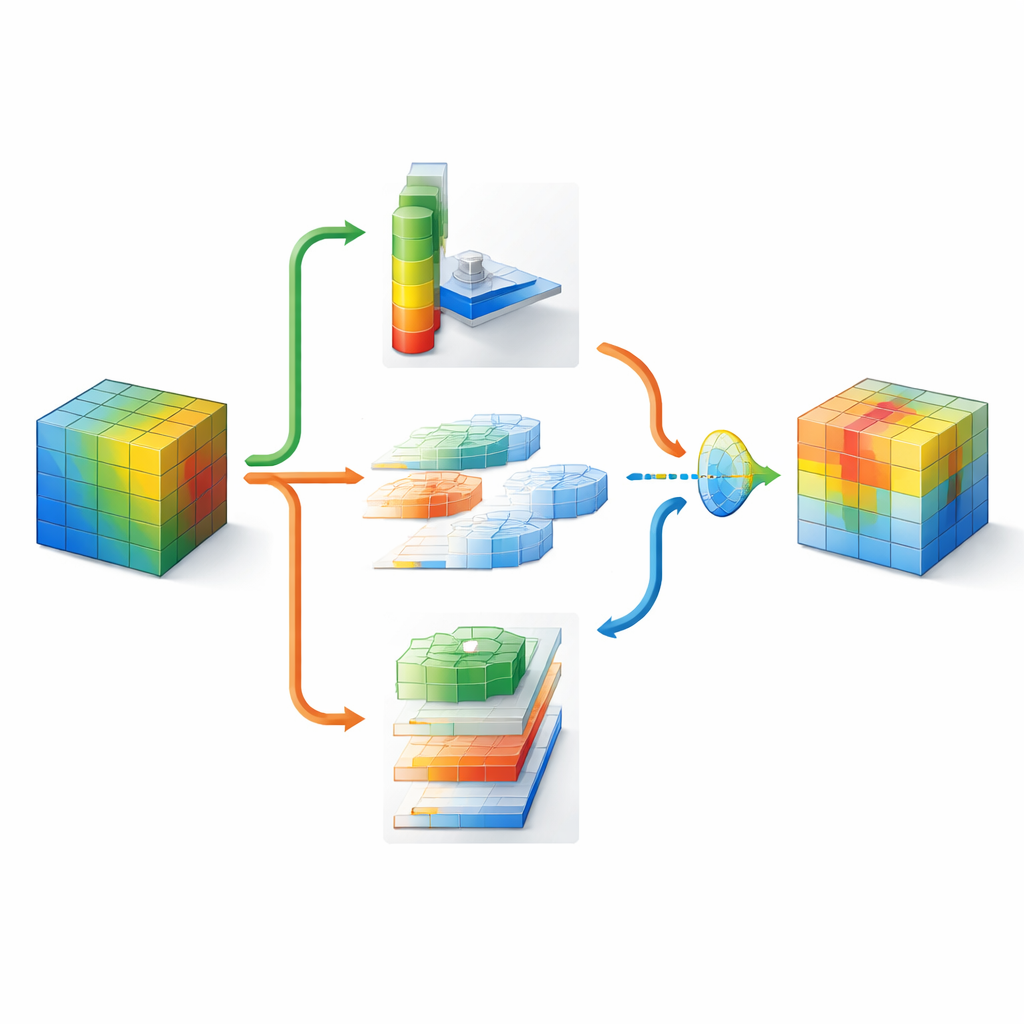
わずかな追加コストでより鮮明な視覚
著者らは小さな画像コレクションから大規模なImageNetデータセットまで、いくつかの標準ベンチマークでDMSCAを評価しました。人気のあるResNetモデルに追加した場合、DMSCAは小規模データセットで最大約2ポイント、ImageNetで約1.5ポイントの分類精度向上を一貫してもたらし、既存の多くの注意手法を上回りました。また、ノイズ、ブレ、強い圧縮などの一般的な画像劣化に対してモデルをより頑健にし、物体検出やシーンラベリングなどの関連タスクでも性能を向上させました。これらの利得は計算量とメモリの増加がわずかで済みます。簡潔に言えば、DMSCAは畳み込みネットワークに対して、何を注視し何を無視するかをより柔軟で文脈依存に判断させる手段を与え、人間の視覚が持つ選択的焦点に一歩近づけます。
引用: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
キーワード: 注意機構, 画像認識, 畳み込みニューラルネットワーク, 特徴表現, 堅牢なコンピュータビジョン