Clear Sky Science · ja
ラベルグラフ最適化とハイブリッド損失関数によるクロスモーダル検索の向上
画像と言葉を横断してより賢く検索する
私たちは毎日、写真や動画、テキストの海をスクロールしています。短いキャプションに合うすべての画像のように、正確に欲しいものを見つけるには、コンピュータが画像と言語をどれだけうまく結びつけられるかが鍵になります。本稿は、その結びつきをより正確にする新しい手法を探ります。特に多くの概念や物体が同時に現れる現実世界の雑多な場面で有効です。その結果、入力した語句だけでなく我々の意図をよりよく「理解」する、より賢い検索ツールが実現します。
1枚の写真に多義性があることの重要性
単一の画像がひとつの対象だけを示すことはまれです。海でブリーチするクジラの写真には、海、空、波、風、野生生物が同時に写っているかもしれません。こうした写真にタグを付けるとき、私たちはしばしば微妙に関連する複数のラベルを付与します。既存の検索システムは通常、これらのラベルを無関係なチェックボックスのように扱いますが、その単純化は有用な手がかりを捨ててしまいます。例えば「クジラ」がしばしば「海」と共起するなら、一方が見えればもう一方の可能性が高まります。本研究は、検索がある概念を探す際に関連の深い表現も見つけられるよう、ラベル間の隠れた結びつきを捉えることに注力します。

つながるラベルの網を構築する
著者らは、ラベル同士の関係をモデル化する Two-Layer Graph Convolutional Network(L2-GCN)という手法を導入します。簡単に言えば、それぞれのラベル(「空」や「クジラ」など)をネットワーク上の点として扱い、点どうしの線はそのラベルがどれだけ共起するかを反映します。この手法では各ラベルが繰り返し「近隣」の情報に耳を傾け、関連ラベルから情報を取り込んで自らの表現を磨きつつ独自性を保ちます。この処理を経て、並列の概念(「海」と「ビーチ」)から階層的な概念(「動物」と「クジラ」)まで、現実の場面の構造をよりよく表現する豊かなラベル記述が得られます。
画像と言葉が共通の空間を共有するように学習する
もちろん、ラベルだけでは不十分で、システムは画像とテキスト自体からも学ぶ必要があります。フレームワークは既存の手法を用いて生のピクセルや単語を数値的な特徴に変換し、両者を意味を直接比較できる共通空間に投影します。生成対向ネットワークの押し引きに着想を得た敵対的モジュールは、画像かテキストのどちらか一方の特性に頼りすぎることを抑制します。これにより共通空間はフォーマットではなく内容に集中し、賑やかな通りの写真とそれを説明する短いキャプションが意味的に近く配置されるようになります。
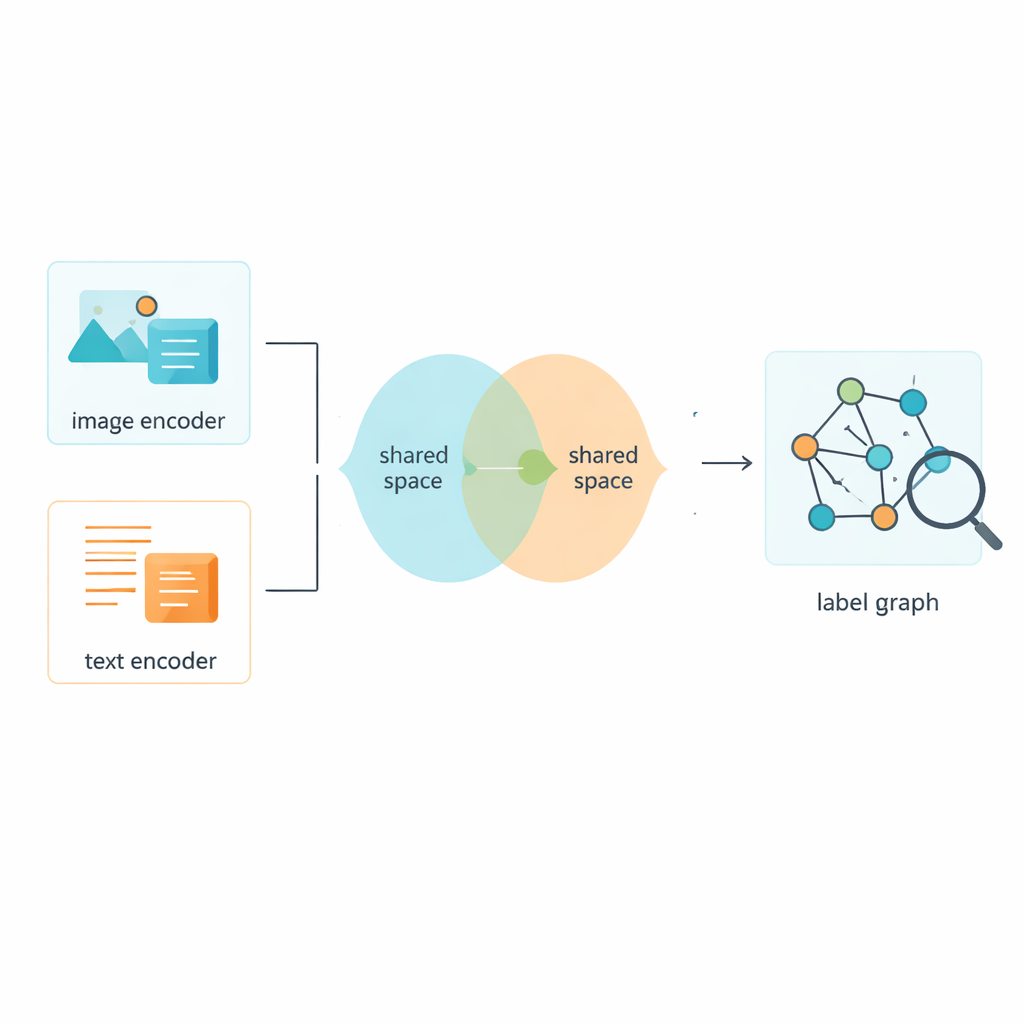
より鋭い識別のためのハイブリッド学習戦略
このようなシステムの訓練には一つの学習規則だけでは不十分です。著者らは Circle-Soft と名付けた複合損失関数を設計し、二つの補完的な考え方を混ぜ合わせます。一方は同一カテゴリの例を柔軟かつ適応的に密集させつつ異なるカテゴリを押し離すことを促します。もう一方は同じ場面を記述する画像とテキストが異なる形式を越えてどれだけ整合するかに注目します。チューニング可能な重みがこれら二つの目的のバランスを取り、モデルが一方の過剰適合に陥らないようにします。さらに分類損失や敵対的損失が、洗練されたラベル表現と共通の画像–テキスト特徴との整合性を促します。
検索はどれだけ改善するのか?
これらのアイデアが検索性能に結びつくかを評価するために、著者らは MIRFlickr、NUS-WIDE、MS-COCO の三つの実世界の画像–テキスト対コレクションで手法を試しました。これらのデータセットは、街の風景から野生生物まで日常的な場面を網羅する、タグやキャプション付きの数千から数十万枚の写真を含みます。三つのベンチマークすべてで、新しいアプローチはグラフベースのラベルモデリングを用いる他の高度な手法を含む多様な競合法を一貫して上回りました。厳格な検索指標での改善は約0.5ポイントから1ポイント程度と控えめに聞こえるかもしれませんが、成熟したベンチマークでは小さな改善でも内容理解の精度向上を示します。実用的には、短いテキストクエリや画像を入力したときに、関連するクロスモーダルの一致が結果の上位に表示されやすくなるということです。
日常の利用者にとっての意義
専門家でない人への要点は、ラベルの扱いと学習規則を賢くすることで、画像と言葉の結びつきが目に見えて改善するということです。ラベルを孤立したタグとしてではなく相互に結びつく網として扱い、視覚情報とテキスト情報が共有空間で出会う形を丁寧に作ることで、このフレームワークは複雑で多トピックな場面におけるクロスモーダル検索の信頼性を高めます。こうした技術は、我々の言葉が画像と完全に一致しない場合でも、意味するものを見つけ出すより直感的な写真ライブラリやメディアプラットフォーム、インテリジェントアシスタントを支えるようになるでしょう。
引用: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
キーワード: 画像-テキスト検索, マルチモーダル検索, グラフニューラルネットワーク, セマンティックラベル, 機械学習