Clear Sky Science · ja
転写因子結合部位予測のためのDNABERTベース深層学習フレームワーク
DNAの制御スイッチを予測する意義
体内のすべての細胞は基本的に同じDNAを持ちながら、脳細胞、肝細胞、免疫細胞といった種類で振る舞いが大きく異なります。その一因は転写因子と呼ばれる特殊なタンパク質で、これらは分子スイッチのように働き、短いDNA配列(結合部位)に結合して遺伝子のオン・オフを切り替えます。ゲノム全域でこれらの結合箇所を実験的に網羅することは時間と費用がかかります。本研究はTFBS-Finderという新しい人工知能モデルを紹介します。生のDNA塩基配列を解析して転写因子の結合位置をより高精度に予測でき、遺伝子制御や疾患研究を加速させる可能性があります。
DNAを言語のように読む
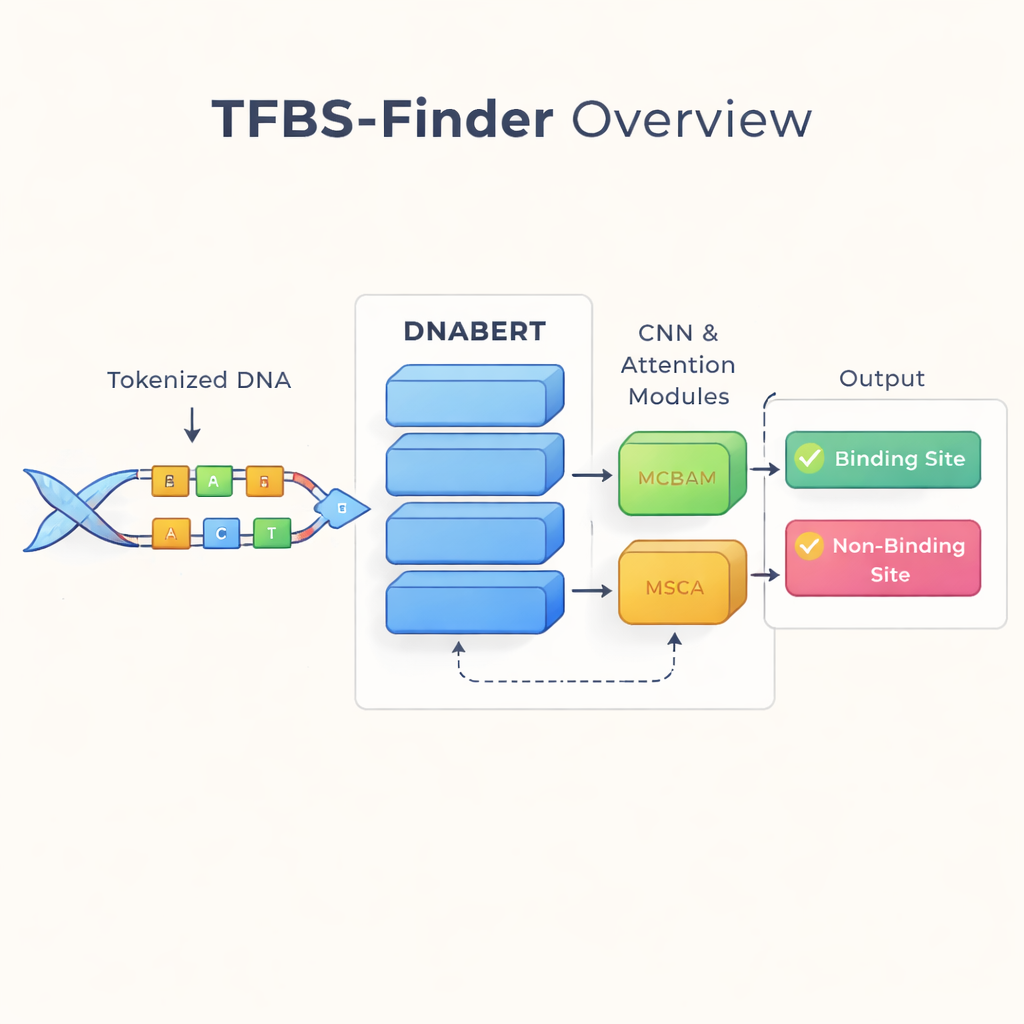
著者らは言語技術を変革した考え方を踏襲しています:DNAをテキストのように扱うのです。彼らはDNABERTという、単語の代わりにヒトのDNAで再学習したBERTモデルを用いています。DNABERTは単一の塩基だけを見るのではなく、重複する5文字の短い“単語”に分割して、それらの共起性を学習します。これにより、配列の一端にあるパターンと遠く離れた箇所のパターンの関係など、文脈を長距離にわたって捉えることができ、単語を孤立して理解するよりも文の意味を把握するのに似た利点があります。
局所的パターンを注目して見つける
DNABERTはグローバルな文脈把握に優れていますが、転写因子の結合は非常に短く正確なモチーフ—DNAの局所的なパターン—に依存することが多いです。そこでTFBS-FinderはDNABERTの上にいくつかの追加コンポーネントを組み込みます。畳み込みニューラルネットワーク(CNN)は配列埋め込みを走査して繰り返し現れる局所的な形を強調し、画像処理がエッジや角を検出するのに似た役割を果たします。MCBAMとMSCAという二つの注意モジュールは調整可能なスポットライトのように働き、有益な特徴を強調しノイズを抑えます。これらのブロックは大局的な文脈と微細な局所情報のバランスを取りながら、あるDNA断片が真の結合部位を含むかを判定します。
各構成要素の有効性を示す
これらの要素が本当に必要かを検証するために、チームは広範なアブレーション実験を行い、モジュールを系統的に除去・再配置して165のベンチマークデータセット(29の転写因子、32の細胞型を網羅)で再学習しました。標準的な予測性能指標に基づく評価では、完全版のTFBS-Finderが一貫して最良の成績を示しました。DNABERTのみを用いる簡略版や注意モジュールの一方を欠いた版は明らかに精度を落としました。統計検定により、これらの性能低下が偶然によるものではないことが確認され、グローバルな配列理解と局所パターンへの入念な注意機構の組み合わせが重要であることが示されました。
細胞型を越えて機能し、既存手法を上回る
ある生物学的文脈で学習したモデルが別の文脈に一般化できるかは重要な問いです。著者らはよく研究された転写因子CTCFに注目し、ある細胞株のデータでTFBS-Finderを学習させ、他の細胞株で評価しました。すべての組み合わせで高いスコアを達成し、CTCF結合の組織横断的に共有されるコア特徴をモデルが捉えていることを示唆します。既存の9つの主要手法(従来の深層学習やBERTベースのモデルを含む)と比較して、TFBS-Finderは平均精度で上回り、結合部位のランキングもより信頼できる結果を出しました。また、最も類似する以前のモデルより若干高速でメモリ消費も少なく、性能向上が必ずしも計算負荷の増大を伴わないことを示しています。
モデルが何を学んだかを可視化する
複雑なAIシステムはしばしば「ブラックボックス」と批判されます。本研究では、その箱を開く試みとして、TFBS-Finderの判断に最も影響を与えたDNA位置を可視化しました。既知の結合モチーフを持つ二つの転写因子、CEBPBとGATA3について、配列に沿った重要度スコアを算出し、強い信号を持つ配列をクラスタリングしてコンセンサスパターンを作成しました。これらは確立されたデータベースの参照モチーフとよく一致し、予測された結合領域は独立に検出されたモチーフのインスタンスと重なっていました。これはTFBS-Finderが単に事例を丸暗記しているのではなく、転写因子がDNAを認識する生物学的に意味のある規則を学んでいることを示唆します。
遺伝学と医学への意義
TFBS-Finderは、DNAに埋め込まれた制御スイッチをより正確かつ解釈可能にマップする手段を提供します。転写因子が結合しやすい位置を特定することで、研究者は遺伝子制御ネットワークを解明し、重要な制御部位を破壊する可能性のある遺伝的変異の優先順位付けやより的確な実験設計に役立てられます。現段階ではシャッフル配列を人工的なネガティブとして用い、塩基配列のみを扱っているため、著者らは今後DNA形状などの構造情報や、より現実的な背景配列の導入を計画しています。これらのモデルが改良されるにつれて、非コード領域の変化が発生、進化、疾患リスクにどのように寄与するかを理解する強力な支援ツールとなる可能性があります。
引用: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
キーワード: 転写因子結合部位, 深層学習, DNABERT, 遺伝子制御, ゲノミクス