Clear Sky Science · ja
臨床トークン最適化による大規模言語モデルの医療知識表現強化
なぜ医療の「読み取り」を賢くすることが重要か
すべての医療用AIアシスタントの背後には、単純だが重要な技術がある。それはテキストをAIが理解できる単位に切り分ける方法だ。この「切断」が特に複雑な中国語の医療用語でうまくいかないと、医師の記録や患者の質問の重要な点を見落とす可能性がある。本稿は、その最初のステップに対して小さく的を絞った変更を加えるだけで、既存のシステムを一から作り直すことなく、大規模言語モデルが中国語の医療データをよりよく読み、推論し、質問に答えられるようになることを示す。
テキストを適切に切り分ける
現代の言語モデルは文字や単語を直接読むわけではなく、まずトークンと呼ばれる短い単位に変換する。英語では空白が単語境界を示すため比較的うまく機能するが、中国語は事情が異なる。空白がなく、多くの医療表現は長く専門性が高い。主に英語向けに設計された標準的なトークナイザは、これらの表現を任意の断片に分割しがちだ。モデルが病名や検査項目を複数の離散した断片として見ると、その用語の本来の意味を学びにくくなり、医療質問への応答があいまいになったり不正確になったりする。
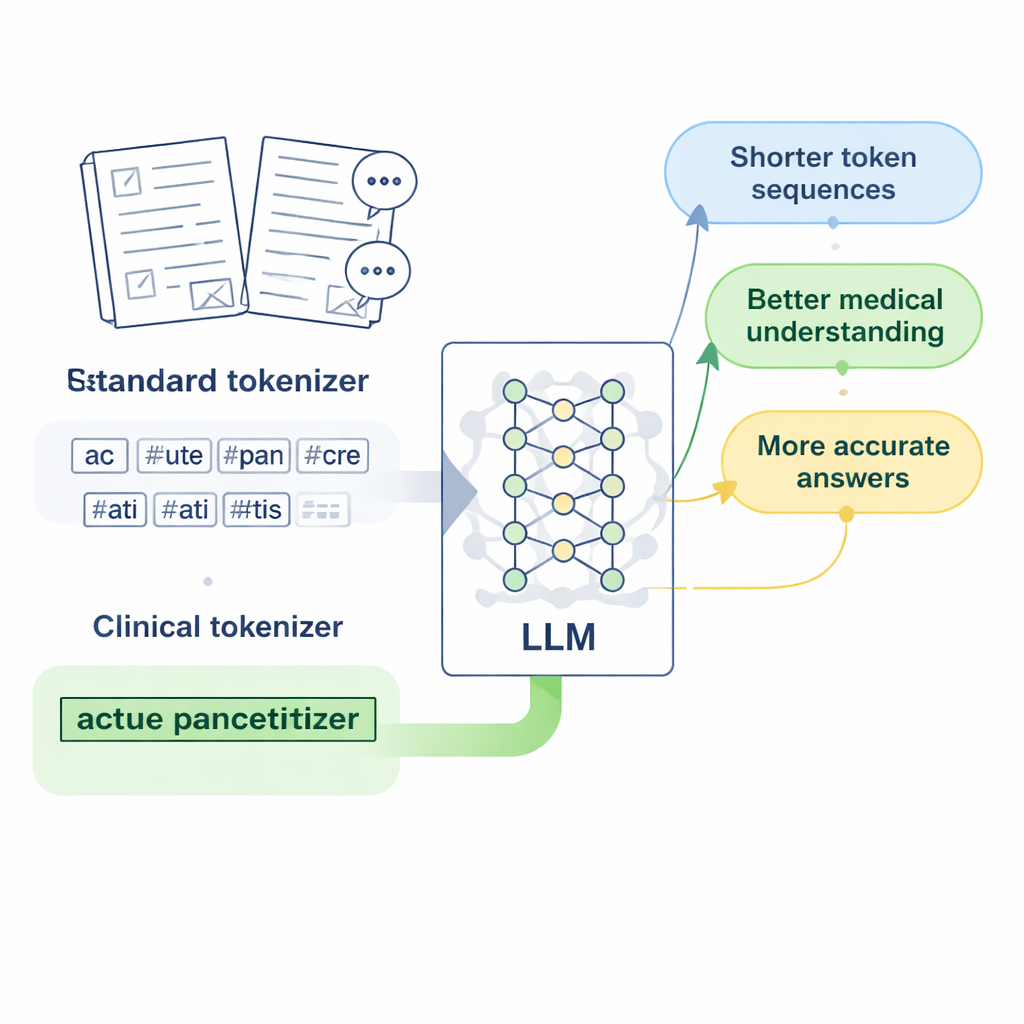
中国医学のための「臨床トークン」を設計する
研究者らは、人気のあるオープンソースの大規模言語モデルであるLLaMA2に着目し、トークナイザにより豊かな医療語彙を教えたらどうなるかを問いかける。彼らは、精査された中医薬のデータベース、数千件の臨床記録、医師と患者のQ&Aペアなど、大規模な中国語医療テキストを収集する。Byte Pair Encodingのバイトレベル版をSentencePieceツールで実装して新しいトークナイザを訓練し、一般的な医療表現を一つの単位として保持することを学習させる。著者らはこれらの新単位を「臨床トークン」と呼び、既存のLLaMA2語彙に統合して拡張することで、モデルが既に持つ知識を捨てることなく中国語医療語をより良くカバーする。
より良いトークンからより良い医療モデルへ
新しいトークンを追加することは第一歩に過ぎず、モデルはそれらに対する良好な表現(埋め込み)を学ぶ必要がある。チームはLLaMA2の内部埋め込み層を調整して拡張語彙のベクトルを格納できるようにし、新たなベクトルの初期化方法を二つ試す。一つは各語の既存のサブパーツのベクトルを平均する方法、もう一つは慎重にスケール調整したランダム値を用いる方法だ。逆説的に、ランダム初期化の方が性能が良く、これはモデルを誤った初期推定に固定してしまうのを避けるためと考えられる。著者らはその後、医療テキストで続けて訓練を行い、LoRAと呼ばれる資源効率の高い手法で指示型の医療Q&Aに微調整を施し、Medical-LLaMAと呼ぶ専門化バージョンを作成する。
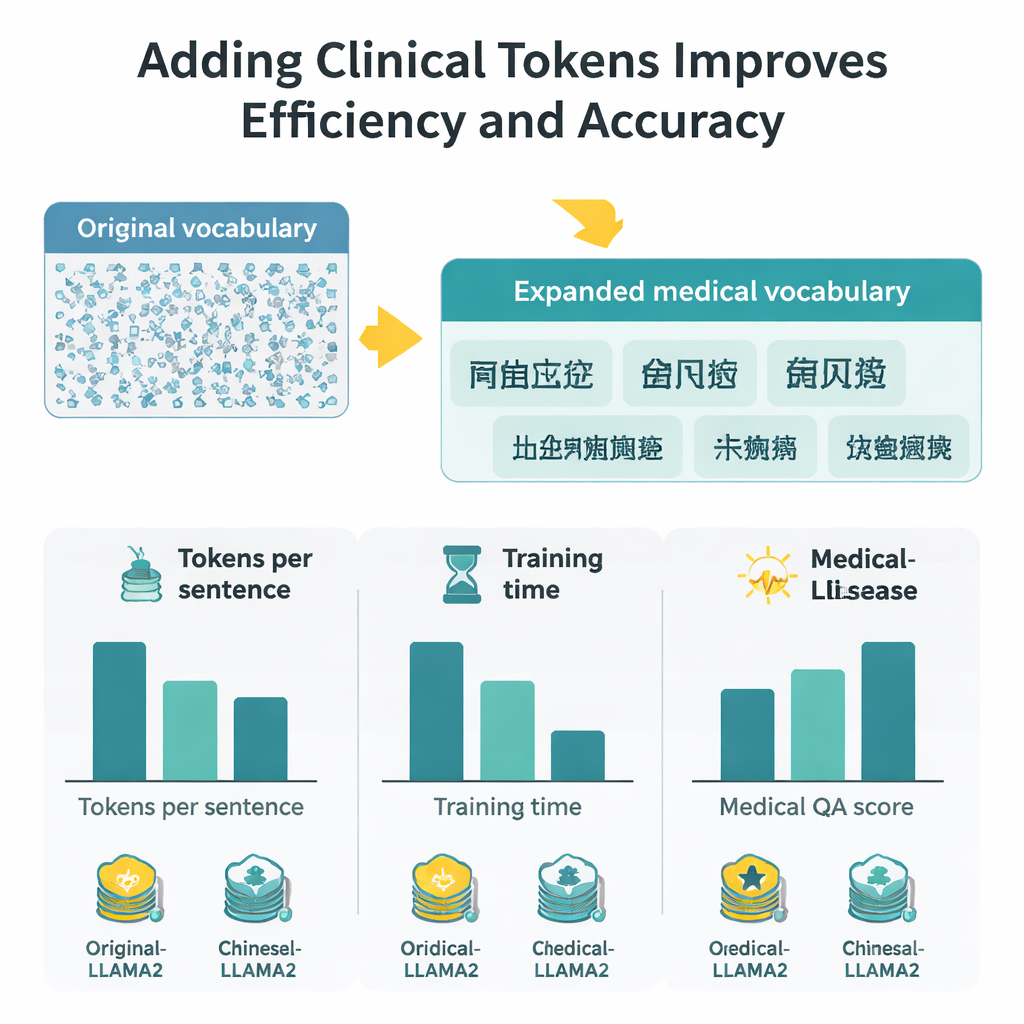
速度・文脈量・精度の向上を測る
語彙を拡張したことで、中国語の各文字に必要なトークン数は約半分になり、同じ固定トークン窓でより長い文章を処理できるようになる。実際には有効な中国語コンテキスト長は概ね2倍になり、大規模な医療Q&Aセットでの微調整時間はほぼ半分に短縮された。応答の質を評価するために、著者らは二つの評価戦略を組み合わせる:生成応答が参照にどれだけ意味的に近いかを測るBERTScoreと、関連性・正確性・完全性・流暢性を評価する洗練された評価モデル(DeepSeek-R1)だ。これらの指標において、Medical-LLaMAは元のLLaMA2と医療専用トークンを含まない中国語最適化版の双方を一貫して上回った。また、医療エンティティ認識や臨床テキスト分類といった関連タスクでも小さく安定した改善を示し、非医療の一般的な質問への性能も維持された。
将来の医療AIにとっての意味
非専門家向けの要点は、AIの「読書眼」を賢くする――ここでは医療言語の切り分け方を改善する――ことで、健康関連の質問を理解し応答する能力が明確に向上することだ。既存モデルの語彙に適切な臨床トークンを挿入するだけで、大規模な再訓練や新しいアーキテクチャを必要とせず、効率と精度の両方が向上する。研究は7Bパラメータモデルと中国語医療テキストに限定されるが、初期の言語処理層をドメインに合わせて調整し、軽く再訓練するという実践的なレシピを示している。この戦略は、標準モデルが読み取りに苦労する言語や専門領域において、臨床医や患者の信頼できるパートナーとなる将来の医療AIツールの実現に寄与する可能性がある。
引用: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
キーワード: 医療言語モデル, 中国語の臨床テキスト, トークン化, 臨床語彙, 医療質問応答