Clear Sky Science · ja
AE-LFOG-YOLO: 適応アンカーと照明不変学習による堅牢な安全ヘルメット検出
なぜスマートなヘルメットチェックが重要か
大規模な建設現場や地下トンネルでは、単純な安全ヘルメットの着用が、危険一歩手前の出来事と人生を変えるような負傷の差を生むことがあります。しかし、実際の作業現場の混乱の中では、作業者がヘルメットを忘れたり着用を怠ったりし、人間の監督者が常にすべての角を見張ることはできません。本研究は、トンネルが薄暗く、照明のぎらつきがあったり、カメラからさまざまな距離に多くの作業者がいるような状況でも、誰がヘルメットを着用しているかを確実に判別する自動カメラシステムを構築する方法を探ります。
過酷なトンネル照明での視認の課題
トンネル工事現場は視覚的に極端な環境です。強いスポットライトはぎらつきを生み、深い影のポケットは詳細を隠します。人々はカメラに近づいたり遠ざかったりするため、ヘルメットはさまざまな大きさで映ります。既存のAI検出器はこうした状況でしばしば失敗します:暗部のヘルメットを見落としたり、他の丸い物体をヘルメットと誤認したり、非常に小さいまたは遠方の作業者に苦戦したりします。多くの既存システムは、検出前に画像を明るくしたりノイズ除去を行ったり、あるいは人気のあるYOLOモデルのいくつかの構成要素を手直しすることで改善を図ります。しかし、これらの手法は通常、単一の学習プロセスに組み込まれたものではなく取り付け的な対策に留まるため、性能の限界を残し、照明やシーンの配置が変わると堅牢性を欠きます。
悪条件の照明を無視するようカメラを教える新しい手法
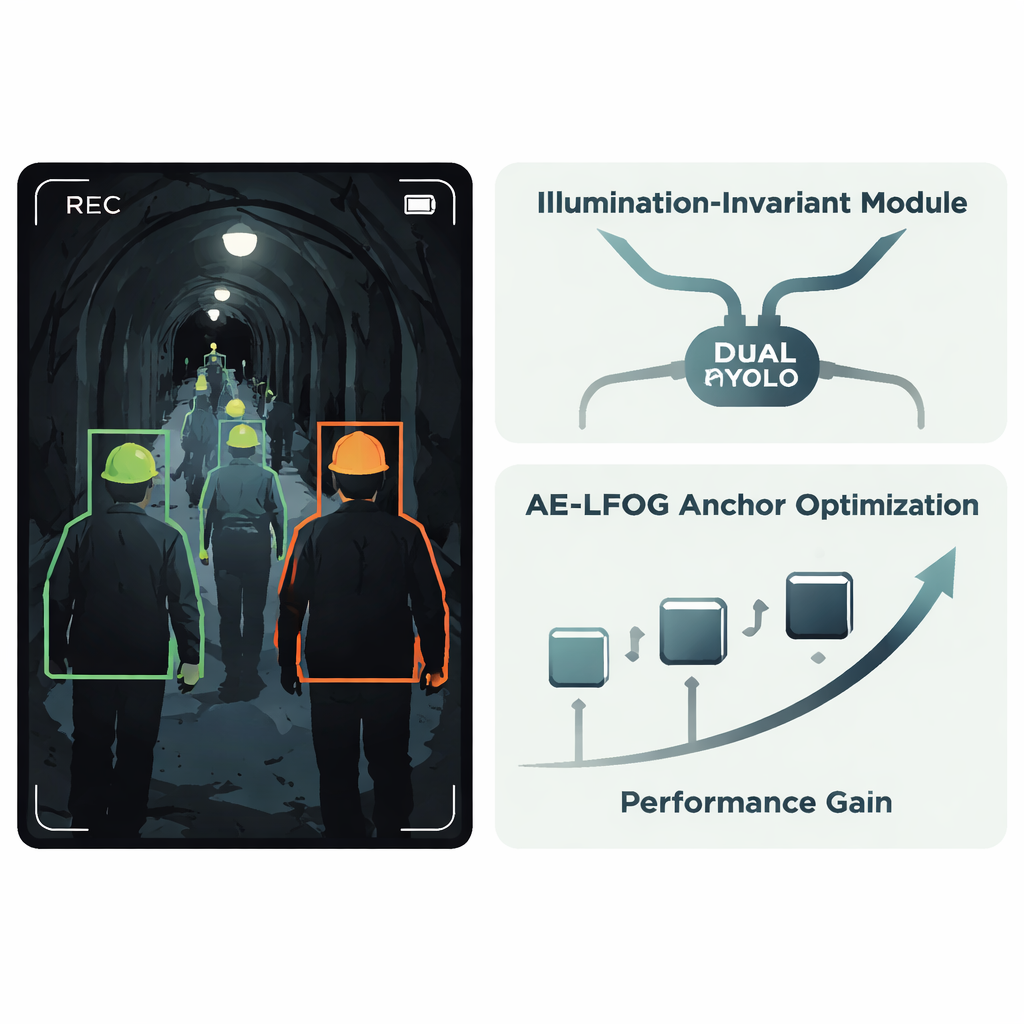
著者らは、広く使われるYOLOv8検出器を基盤にしたAE-LFOG-YOLOという改良システムを提案します。第一の主要アイデアは「照明不変モジュール」です。これはネットワーク内部に追加される小さなユニットで、「光がどう振る舞っているか」と「物体が実際にどう見えるか」を分離することを学習します。入力特徴マップを、主に照明パターンを反映する部分と、ヘルメットの曲線端など安定した形状やテクスチャを捉える部分に分割します。特殊なゲーティング操作とエッジやコーナーに注力するブランチを用いることで、明るさの変動を抑え、安定した幾何学的特徴を強調します。これは前処理として画像を修正するのではなく検出器内部で行われるため、システム全体をエンドツーエンドで訓練し、ぎらつきや暗部に惑わされずヘルメット自体に集中できるようになります。
モデル自身に視点を進化させる
第二の主要アイデアは、検出器が物体の出現しそうな場所を推測する方法に関するものです。多くの検出器は、固定された一連の「アンカーボックス」から始めます。これらは一般に訓練データから一度選ばれて以降更新されません。しかしトンネルでは、カメラ距離や視角によってヘルメットの見かけの大きさが大きく変わります。AE-LFOG-YOLOは静的なアンカーを、Adaptive Evolutionary – Light Field Optimized Generation(適応進化的・光場最適化生成)と呼ばれる動的プロセスに置き換えます。各訓練ラウンドの終わりにシステムはアンカーボックスをわずかに摂動し、実際のあらゆるサイズのヘルメットにどれだけ適合するかを評価し、さらにカメラ光学に基づく基本的な観点からその寸法が妥当かも確認します—典型的な作業距離でセンサ上に現れる実際のヘルメットの大きさです。より良く得点したアンカーセットが次ラウンドへ生き残ります。時間とともに、検出器はデータに合致しつつカメラが世界をどのように映すかを尊重するアンカーを“進化”させます。
実画像品質に合わせた学習の適応
モデルが何を探すかを変えるだけでなく、著者らは学習の仕方自体も改めます。彼らは、画像品質が低いときにはヘルメットの位置を正確に特定することにより重点を置き、条件が良いときにはヘルメットか未着用かの分類を正しく行うことにより重点を置く訓練戦略を導入します。ここでもカメラ撮像原理に基づく物理的スコアが、各段階で画像の信頼度を示します。照明や焦点が悪ければ、訓練プロセスは自動的にバウンディングボックスの精度の重要性を高め、条件が改善すれば分類の比重へとシフトします。これにより、モデルは実際に直面する物理環境に合わせて優先事項を継続的に調整するフィードバックループを持つようになります。
実験で示された効果
研究者らは実際のトンネル安全ヘルメットデータセットで手法を評価し、いくつかの先進的なYOLOベース手法と比較しました。AE-LFOG-YOLOは非常に高い精度でヘルメットを検出し、標準的な重なり閾値で約95%のヘルメットを正しく特定し、素のYOLOv8ベースラインよりも適合率と再現率の両面で上回りました。リアルタイム使用に十分な速度で動作し、特に極端な暗さや露出オーバーを模した照明操作下で強さを発揮します。こうした厳しい条件下でも、新しいモデルは信頼度を高く保ち、小さく遠い作業者をより多く検出し、明るさの許容範囲がベースラインよりも3分の1以上広く、より多くの実世界シーンで信頼して使えることを示しました。
労働者の安全確保にどう役立つか
専門外の読者にとって要点は明快です:ピクセルだけでなくカメラが困難な環境でどのように見ているかという物理性も理解するようAIを教えることで、本研究はより賢く信頼できる「壁の監視者」を提供します。AE-LFOG-YOLOは誤誘導する照明を無視し、変化する視点に適応する能力が高く、見落としや誤警報を減らします。運用中の鉄道系現場に数か月配備された実例でも、作業者がヘルメットを着用しているかどうかを安全チームの支援に役立てられることが示されており、より安全で密に監視された建設現場に向けた実用的な一歩を提供します。
引用: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
キーワード: 安全ヘルメット検出, トンネル工事, コンピュータビジョン, 低照度撮影, YOLOv8