Clear Sky Science · ja
教師あり学習モデルにおけるk分割交差検証のk選択がバイアスと分散に与える影響
モデルを二度チェックすることが本当に重要な理由
医療診断から与信審査まで、多くの意思決定が過去のデータで学習した機械学習モデルに依存するようになりました。しかし、画面上で良さそうに見えるモデルが未知の新しいケースでもうまく動作するかはどうやって確かめればよいでしょうか。モデルを「テスト」する一般的な方法の一つがk分割交差検証で、データを繰り返し訓練用と検証用に分割します。本研究は一見単純だが重要な問いを投げかけます:分割数、すなわちkはどれくらいにすべきか、その選択は報告されるモデル性能の信頼性にどのように影響するのか?
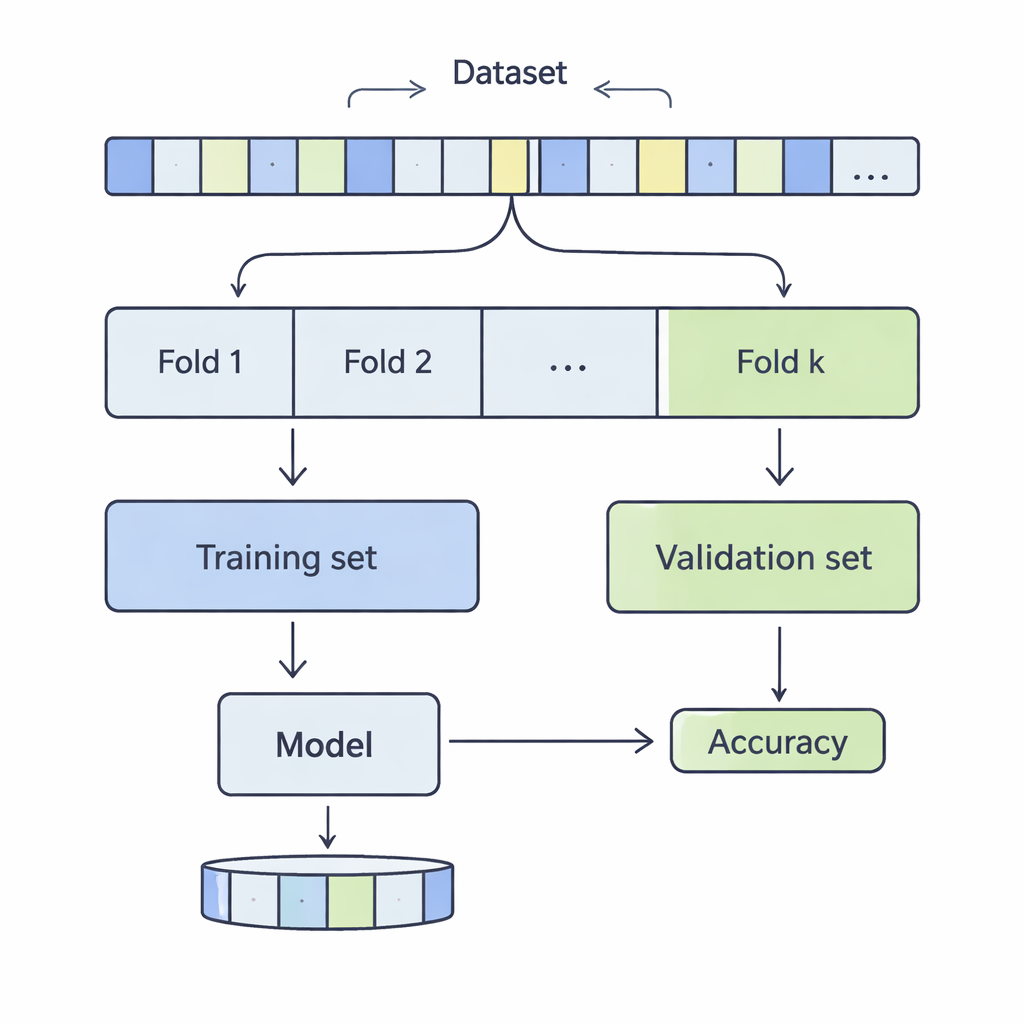
現実検査のためにデータはどう切り分けられるか
k分割交差検証では、データセットをシャッフルしてk個の等しい部分(フォールド)に分けます。モデルはそのうちのk-1フォールドで訓練され、残り1つで評価されます。この手順をすべてのフォールドが検証役を務めるまで繰り返します。著者らはkを3から20まで変化させ、数千から50万件を超えるレコードを含む12の実世界データセットを対象に調査しました。対象は収入予測、医療アウトカム、サイバー攻撃、ゲーム、ワイン品質など多岐にわたります。彼らはサポートベクターマシン、決定木、ロジスティック回帰、k近傍法という4つの一般的な分類手法を適用し、kの選択が性能の2つの主要な側面、すなわちバイアスと分散にどのように影響するかを慎重に測定しました。
日常的な言葉でのバイアスと分散の意味
この文脈でのバイアスは、交差検証中にモデルが示す性能が、未使用の別のテストセット上での実際の性能よりどれだけ良く見えるかを示します。大きな正のバイアスは、交差検証でモデルが過度に楽観的に見えることを意味します—模擬試験では完璧でも本番の試験でつまずく学生に似ています。分散はフォールドごとにモデルの性能がどれだけ変動するかを反映します:分散が低ければ異なるデータ分割間でスコアが安定していることを意味し、分散が高ければスコアが上下に大きく揺れます。理想的には、報告される精度が現実的で安定しているように、バイアスと分散の両方が低いことが望まれます。
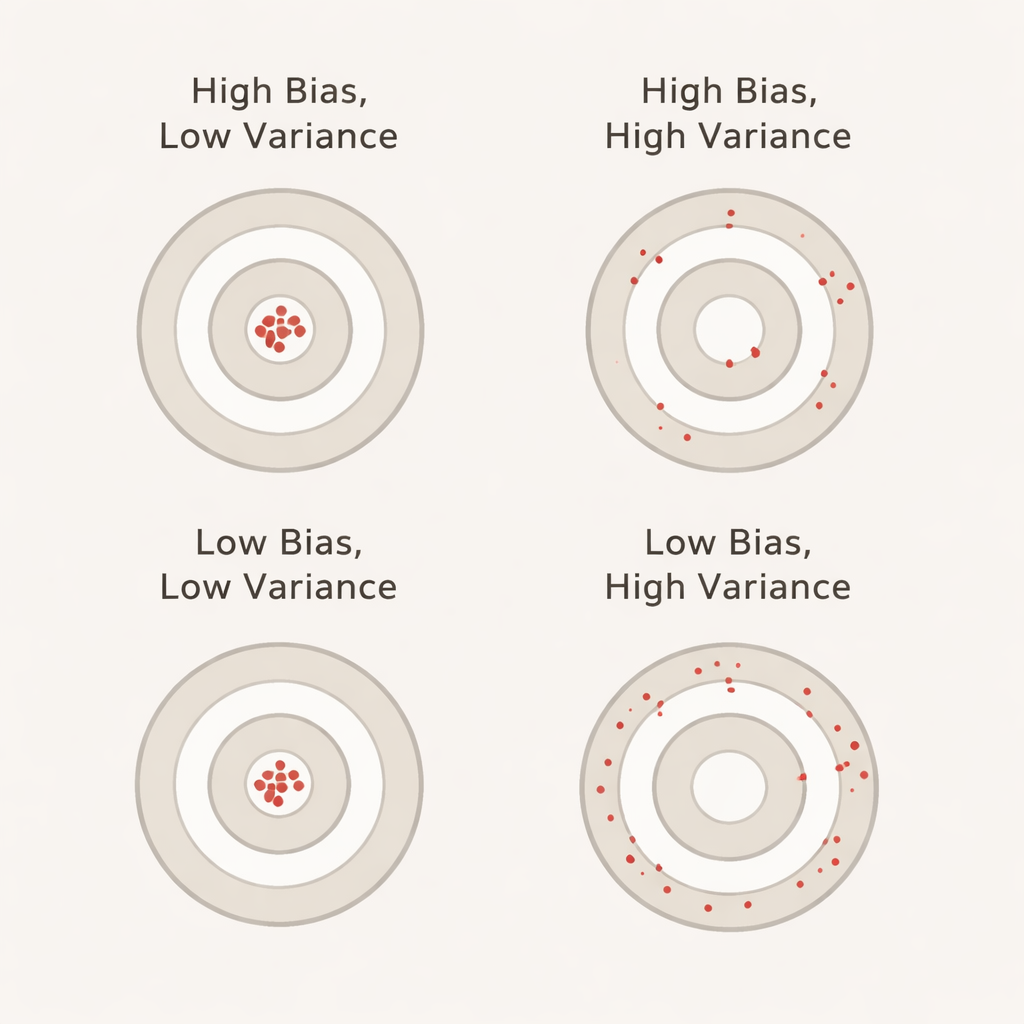
フォールド数を増やすと何が起きるか
12のデータセットと4つのアルゴリズム全体にわたって、明確に見られた一つの傾向は、kを増やすと分散がほとんどの場合増加するということでした。つまり、フォールド数を増やすと報告される精度がフォールド間で不安定になりやすいのです。これは「フォールド数を増やせばより良く、より信頼できる推定が得られる」という一般的な信念に反します。その理由は、kが大きいと各検証用スライスが非常に小さく代表性を欠き、データの特異性に結果が敏感になるためです。一方でバイアスの振る舞いは一様ではありませんでした。k近傍法とサポートベクターマシンでは、kが増えるにつれてバイアスが上昇する傾向があり、これらのモデルは交差検証ではしばしば保持したテストセット上よりも正確に見えることが分かりました。決定木は概ねバランスの取れたパターンを示し、ロジスティック回帰はその中間に位置し、バイアス変化は混在しつつもより穏やかでした。
「標準設定」が誤解を招く理由
実務的なガイドの多くは、データセットや学習アルゴリズムに関わらず5または10フォールドを使うことを単純に勧めます。著者らの分析は、そのような一律の助言が誤解を招く可能性があることを示しています。あるデータセットやあるモデルでは、kを大きくすると性能に対する過度に楽観的な印象が増幅されることがあり、全てのケースでフォールド数が増えると推定のばらつきが増加しました。これは医療、金融、インフラなどの高リスク分野では特に憂慮すべき点で、モデルの精度に対する誤った自信が現実世界に影響を及ぼす可能性があります。研究は、kの影響がデータの性質(小規模か大規模か、ノイズが多いか比較的きれいか)およびほぼ同一の訓練セットが繰り返されることに対する各アルゴリズムの学習のされ方によって左右されると論じています。
機械学習を使う人への持ち帰りメッセージ
中心的な教訓は、交差検証におけるフォールド数は無害な技術的詳細ではなく、精度の数値がどれだけ信頼できるかを直接形作るということです。本実験では、フォールド数を増やすと結果が一貫して不安定になり、しばしばいくつかのモデルが実際よりも良く見えてしまいました。単にk=5やk=10を盲目的に選ぶのではなく、kを調整可能なつまみとして扱い、いくつかのk値の範囲で結果の変化を確認し、可能なら複数の性能指標を見ることを著者らは勧めています。実務者にも興味を持つ読者にも明確なメッセージがあります:機械学習モデルを評価する際、データの切り方はモデル自体とほぼ同じくらい重要になり得ます。
引用: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
キーワード: k分割交差検証, バイアス・分散トレードオフ, モデル評価, 機械学習の検証, 教師あり分類