Clear Sky Science · ja
マリー・スクウォドフスカ=キュリー行動のための自然言語処理に基づく専門家割り当てシステム
適切な専門家選びが本当に重要な理由
限られた資金をめぐって何千もの研究提案が競う場では、すべては誰がそれらを評価するかにかかっています。割り当てられた専門家が提案の主題を真に理解していなければ、有望なアイデアが誤解されたり見落とされたりします。この記事は、人工知能、特に現代の言語処理システムが、今日のキーワードベースのツールよりも正確かつ公平に提案と最適な専門家を結びつけるのにどのように役立つかを探ります。
キーワード・チェックリストの問題点
これまで、マリー・スクウォドフスカ=キュリー博士研究員フェローシップのような欧州の主要な資金制度における専門家割り当ては、キーワードに大きく依存してきました。現行プラットフォームは提案の説明と査読者のプロフィールをスキャンして一致する用語を見つけ、3名の専門家と代替候補を提案します。しかし副議長(プロセスを監督する上級科学者)はこれらの割り当ての約40%を変更しており、その人手による修正の多さが、システムを手間がかかり遅く、かつやや不透明にしています。毎年最大1万件の提案が寄せられ、しかも固定のキーワードリストが機能しにくい新興分野が増えていることが背景にあります。
人間のように研究を読み取る — スケールで実現する方法
著者らは、専門家が行うように「読む」ことを目指す新しい割り当てシステムを開発しました。ラベルに依存する代わりに、各専門家の公開業績をグローバル研究者IDであるORCIDから収集し、2,800本以上の論文要約のデータベースを構築します。提案の要旨と論文の要旨は、科学文献に特化して訓練された大規模言語モデルGALACTICAによって処理されます。GALACTICAは各要旨をその意味を捉えた数値的な指紋に変換し、単なる言葉遣いではなく内容の類似性を表現します。これらの指紋を比較することで、提案の内容が各専門家の過去の研究とどの程度一致するかを推定できます。
専門性を合算する3つの方法
課題の一つは、専門家が多数の論文を持つことがある点です。システムは専門家と提案ごとに単一のスコアを出す必要があり、著者らは類似度を統合する3つの単純な方法を試しました。Sum(和)戦略はすべての類似度スコアを合計し、広範で繰り返しの関連性を評価します。Product(積)戦略はスコアを掛け合わせ、多数の論文で一貫した類似性を強調しますが、弱い一致があると大きく減点されます。Maximum(最大)戦略は最も強い一致のみを残し、非常に密接に関連する単一の論文が割り当てを正当化するのに十分であると仮定します。これらのスコアは181件の提案ごとに48名の候補専門家をランク付けするために使われ、その順位は副議長が最終的に選んだ専門家と比較されます。
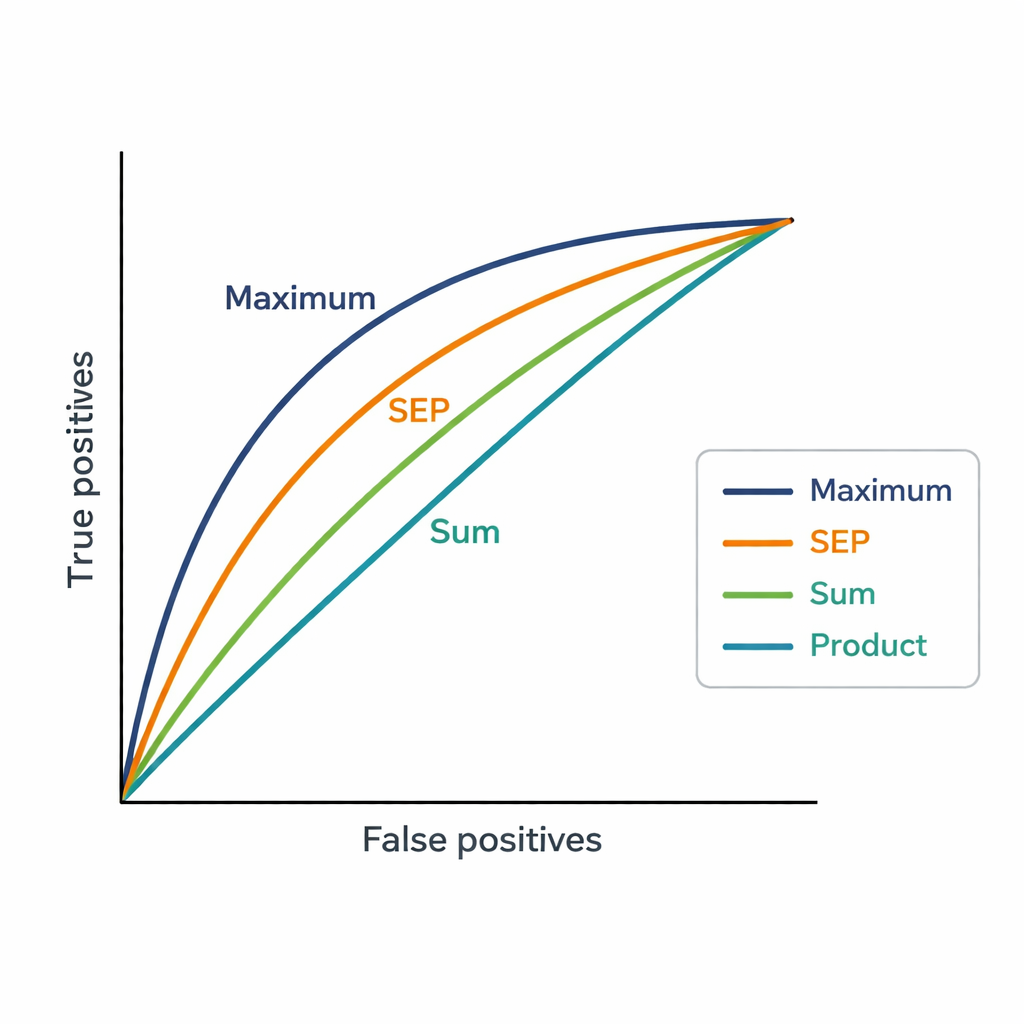
数字が示す人間の選択の特徴
Maximum戦略は副議長の決定と最も高い一致を示し、AUCは0.82に達しました。これは既存のキーワードベースのシステム(AUC 0.75)や他の統合手法を上回ります。実務上、副議長が選んだ専門家は通常、Maximumが提示した上位4件の中に含まれていました。これは査読者を割り当てる際、人々は専門家のすべての論文が一致することを要求するよりも、少なくとも1つの非常に強い関連があるかどうかに注目する傾向があることを示唆しています。また、新しい方法はプラットフォームの粗い「親和性」レベルよりもはるかに細かなスコアを生成し、順位の近い専門家間の区別が明確になります。
将来の助成金審査にとっての意味
一般読者にとっての要点は明快です。科学的言語を理解するAIを用いることで、資金提供機関は提案を適切な専門家とより良く結びつけ、人手による修正を減らし、プロセスをより一貫性のある透明なものにできる可能性があります。論文からの証拠を組み合わせる異なる方法は専門性の異なる側面を強調しますが、単純な「最良の単一一致」ルールは人間が実際にどのように判断しているかを反映しているようです。こうしたシステムがより広く、かつ新しい言語モデルで試されるにつれて、公平で効率的な研究評価の重要な要素になる可能性があります。
引用: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
キーワード: ピアレビュー, 専門家マッチング, 研究資金, 自然言語処理, 大規模言語モデル