Clear Sky Science · ja
高次元かつ高度に不均衡な二値クラス生物情報学マイクロアレイデータのための適応型ファジークラスタ誘導シンプルで高速かつ効率的な特徴選択
遺伝子研究にとっての重要性
現代の遺伝子発現検査は、単一の患者サンプルで数万の遺伝子を測定できます。この膨大なデータは早期のがん診断やより適切な治療選択を可能にする一方で問題も生みます。多くの遺伝子はノイズが多いか冗長であり、珍しいが重要な症例ではなく一般的なケースに関連していることが多いのです。本論文は、大規模な遺伝子発現データセットからコンピュータが小さく検出が困難な少数派の患者群を、慎重に選んだ極めて少数の遺伝子のみで確実に検出できるようにする新しい方法を示します。
過剰かつ類似した遺伝子の課題
マイクロアレイ実験では、数千の遺伝子発現量を追跡する一方で患者数は数百にとどまることが多いです。通常、あるクラス(たとえば一般的ながんサブタイプ)が他より圧倒的に多数を占め、高度に不均衡なデータが生じます。このような状況では、多くの遺伝子が非常に似た振る舞いを示し、多数派と少数派のパターンが重なり合います。標準的な学習手法は多数派に引きずられやすく、冗長な遺伝子に惑わされるため過学習や稀なサブタイプの検出性能低下を招きます。従来の次元削減法は、新たに混成された特徴を作ることで解釈性を失わせるか、分類器が少数派を認識する助けになるかどうかを十分に考慮せずに遺伝子を選択してしまいます。
より賢い遺伝子選択の新しい設計図
著者らはAFCG‑SFEという、高次元かつ不均衡な遺伝子発現データに特化した適応型特徴選択モデルを導入します。本手法は、遺伝子をオン/オフ切り替えして分類性能を評価するシンプルな「単一エージェント」探索から出発しますが、そこにいくつかのデータ駆動型ステップを加えて強化します。まず、遺伝子を振る舞いの類似性に基づいてグループ化し、遺伝子が複数のグループに属することを許すことで、遺伝子が複数の経路に関与するという生物学的現実を反映します。各グループ内では疾患ラベルに対する情報量で遺伝子をランク付けし、主要な代表遺伝子のみを残すことで、主要な探索が始まる前に冗長性を大幅に削減します。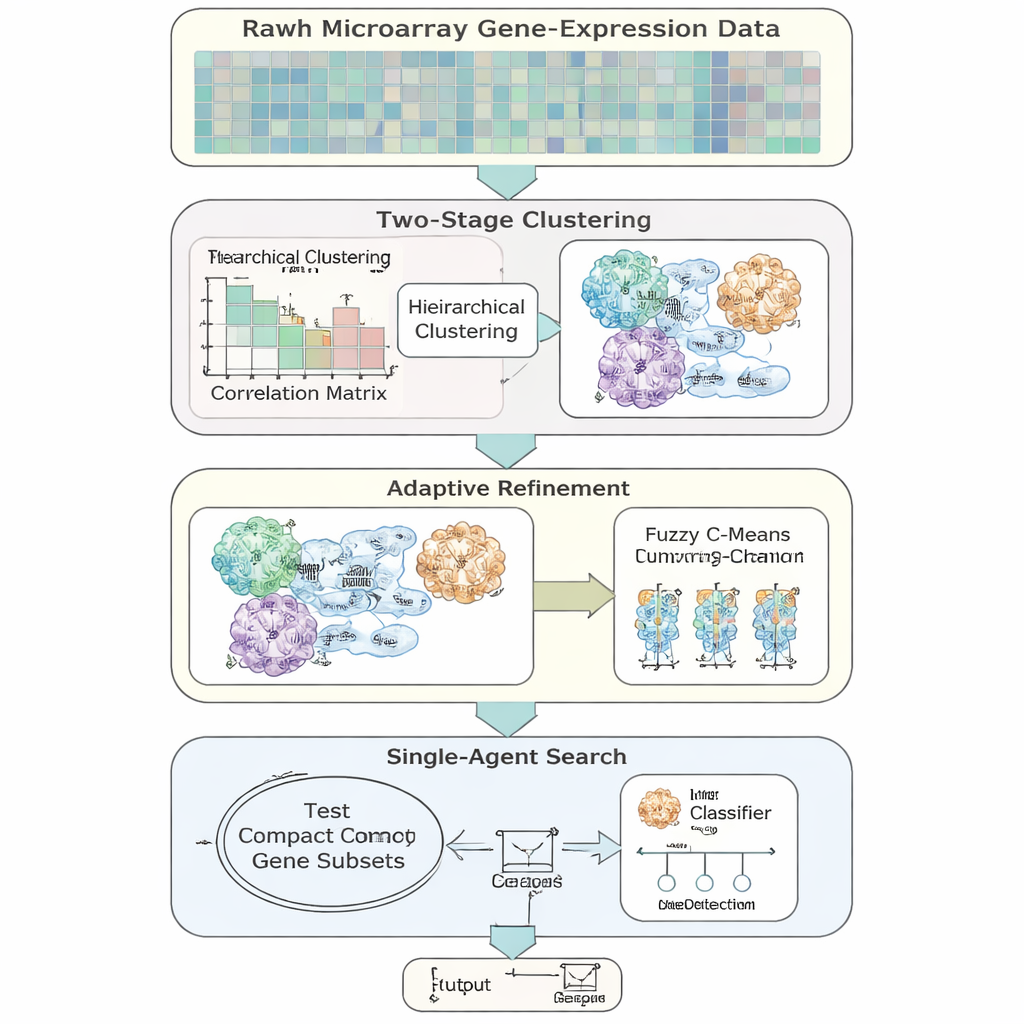
希少な患者に関心を持たせる設計
AFCG‑SFEは単純な正解率に注目する代わりに、不均衡データに適した指標を強調する適合度スコアを用います。これには少数派と多数派の両方を正しく識別するバランスや、あらゆる判定閾値での性能が含まれます。適合度関数にはまた、選択する遺伝子数が多すぎる場合や同一クラスタから多くを選ぶ場合のペナルティ、疾患ラベルと強く依存する遺伝子への報酬も組み込まれます。重要なのは、これらのペナルティや報酬の強さが手動で調整されるのではなく、患者あたりの遺伝子数やクラスの重なり具合といったデータセットの性質から自動的に設定される点です。これにより手法はより堅牢になり、研究間での移植性も高まります。
問題の難易度に適応する
重要な考え方は、アルゴリズムが常に最小の遺伝子セットを目指すべきではないという点です。二つのクラスが分離困難で重なりが大きい場合には、重要な信号が捨てられないように自動的に保持すべき遺伝子数の下限を引き上げます。探索が進むにつれて、AFCG‑SFEは各クラスタから残す遺伝子数の上限を段階的に厳しくしますが、この最小限は尊重されます。その結果、単一の冗長なパターンに支配されない、データ構造を反映したコンパクトで多様な遺伝子パネルが得られます。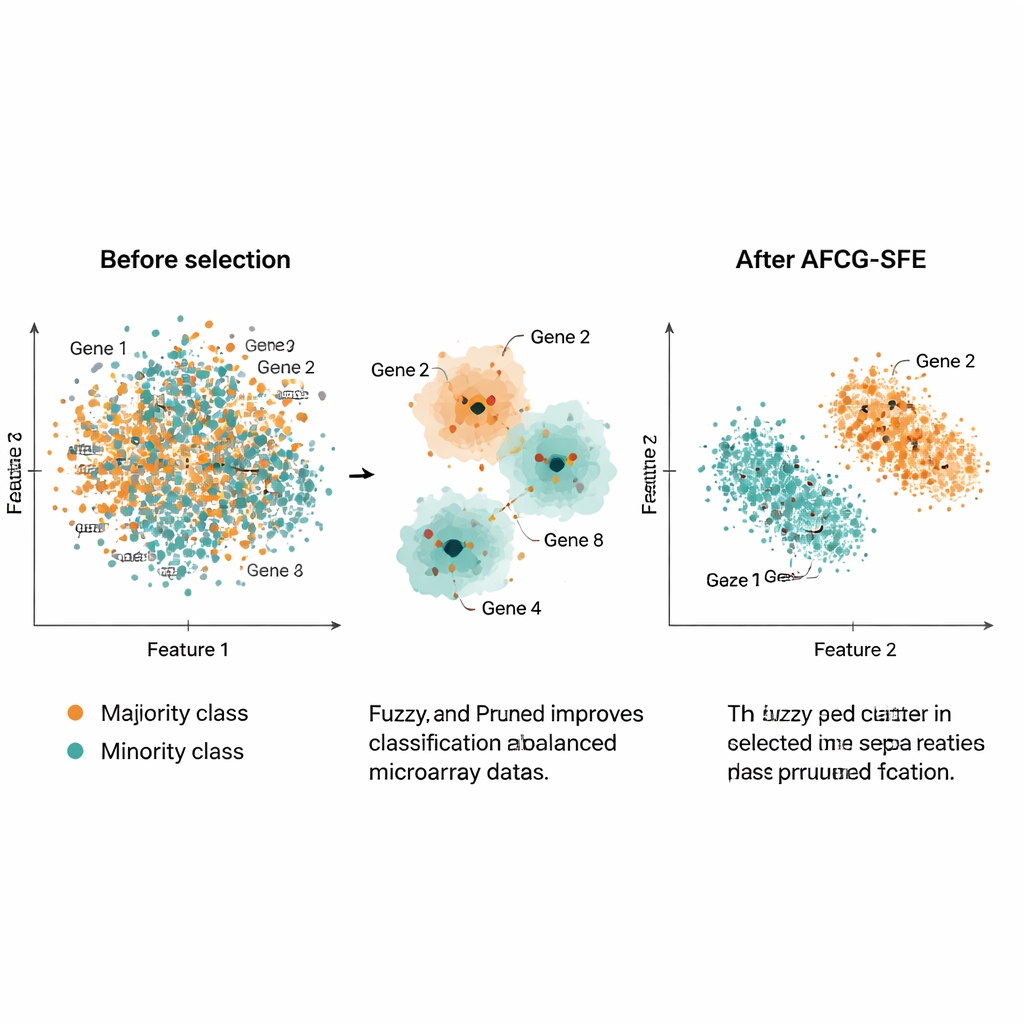
実験結果の要旨
著者らはAFCG‑SFEを、いずれも数千の遺伝子だがサンプル数は約100~200で強いクラス不均衡を持つ20の公開がんマイクロアレイデータセットで評価しました。進化的探索のベースライン、単純なフィルタ法、分類器に組み込まれた埋め込み型手法と比較したところ、F値、バランス精度、ROC曲線下面積、過学習の指標など多数の評価尺度でAFCG‑SFEはすべてのデータセットにおいて最良または同率最良でした。通常は25未満(多くは6~8程度)という非常に少数の遺伝子を選択し、元の特徴の99%以上を除去しつつ分類性能を維持または向上させました。また、特徴空間でのクラス重なりの度合いを表す複雑性指標も低下し、選択後のクラス分離が明瞭になっていることを示しました。
非専門家向けの結論
実務的には、本研究は巨大でノイズの多い遺伝子発現プロファイルを、希少な患者サブグループを正確に識別できる非常に小さな情報量の多い遺伝子セットへと縮小する方法を提供します。類似遺伝子を賢くグループ化し、疾患を真に追跡する遺伝子に報酬を与え、多数派へ偏ることに対して明示的に防御することで、AFCG‑SFEはより良い予測とはるかに単純な遺伝子パネルの両立を実現します。この組み合わせは、研究者が潜在的なバイオマーカーを特定しやすくし、解釈しやすい診断検査の設計を助け、最終的には現実の不完全な生物学的データでの精密医療ツールの有用性を高める可能性があります。
引用: Tye, Y.W., Chew, X., Yusof, U.K. et al. Adaptive fuzzy cluster-guided simple, fast, and efficient feature selection for high-dimensional and highly imbalanced binary-class bioinformatics microarray data. Sci Rep 16, 6650 (2026). https://doi.org/10.1038/s41598-026-37086-w
キーワード: 遺伝子発現, 特徴選択, 不均衡データ, マイクロアレイ, がんサブタイプ