Clear Sky Science · ja
個別化されたスポーツトレーニング計画生成のための知識に基づく大規模言語モデル
日常の人々のためのより賢いワークアウトプラン
ほとんどのフィットネスアプリは個別化をうたいますが、多くは実際の身体状態を無視した汎用テンプレートに頼っています。本論文はLLM-SPTRecと呼ばれる新しいシステムを紹介します。これは現代のチャットボットに使われる大規模言語モデルと、検証されたスポーツ科学知識およびウェアラブルデータを組み合わせて、より安全で効果的なワークアウト計画を作成します。アプリがなぜ間違った運動を提案し続けるのか不思議に思ったことがある人や、AIによる健康アドバイスが本当に安全か懸念している人にとって、この研究はデジタルコーチングをよりパーソナルかつ科学的にする方法を示しています。
従来のフィットネスアプリが不足する理由
映画や商品を推薦する従来のレコメンデーションエンジンは、運動へ適用すると限界があります。多くは標準テンプレートを使い回し、新規ユーザーの限られたデータを扱うのが苦手で、日々の身体変化にほとんど対応していません。さらに、安全性が重要な意思決定向けに設計されていない点が問題です。汎用の言語モデルはワークアウトについて話すのは得意ですが、広範なインターネットテキストで学習しているため、危険な助言を“幻覚”したり、重要な休息日を見落としたりすることがあります。著者らは、運動計画—誤った指導がケガや過剰トレーニングを招きうる領域—では、AIが検証されたスポーツ科学に基づき、かつ個人の時間的変化を追跡する必要があると主張します。
個人の詳細な像を構築する
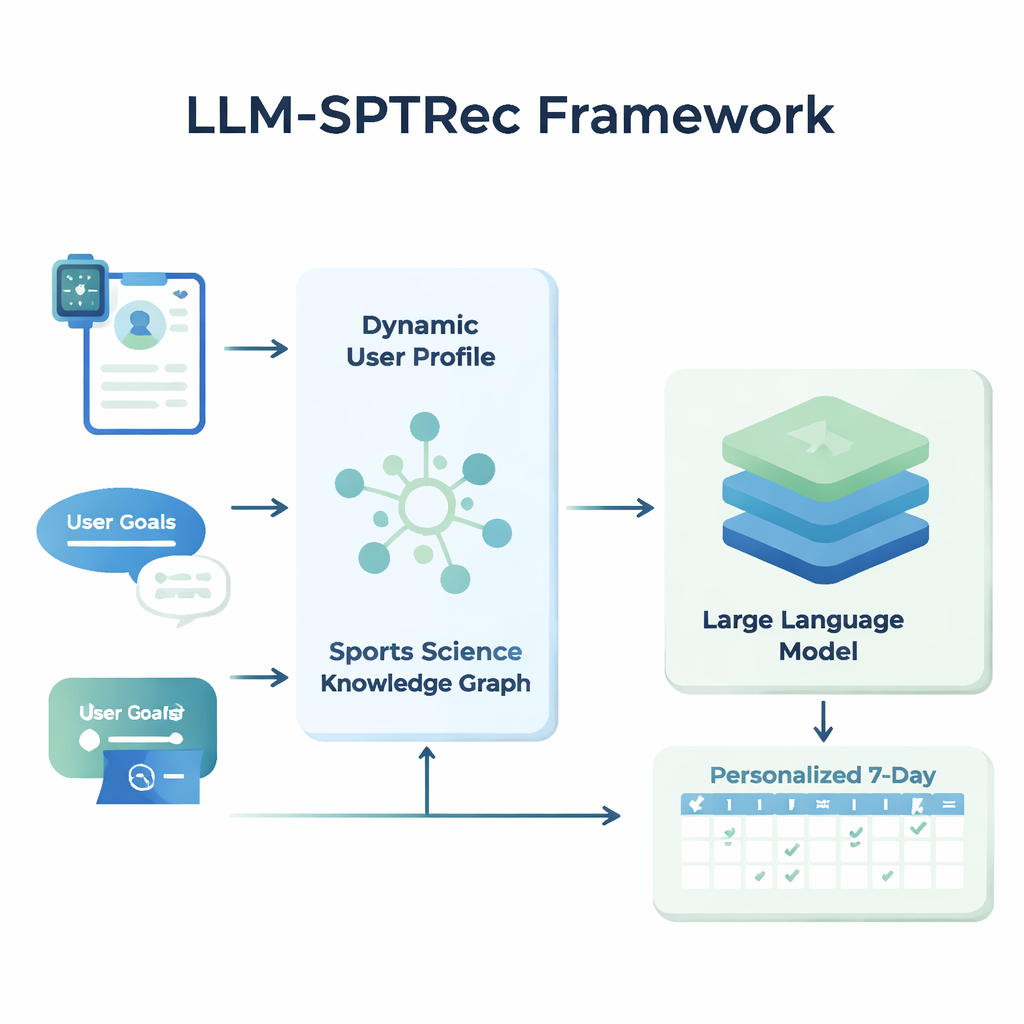
LLM-SPTRecの核は、各ユーザーの詳細なスナップショットを作成するモジュールです。年齢や性別、経験レベルだけを保存するのではなく、システムは三種類の情報を融合します:静的特徴(トレーニング履歴など)、動的シグナル(心拍数、心拍変動、睡眠スコア、ウェアラブルやログからの過去のワークアウトなど)、そしてユーザーが自由記述した目標です。トランスフォーマーベースのモデルは、これらの時系列データにおけるパターン、たとえば「昨日の激しい運動が今日の準備度にどう影響するか」を学習します。アテンション機構がその時点で重要な信号に重みを付け、それらを組み合わせてユーザーの現在の状態を表す単一の数値表現を作ります。
AIに実際のスポーツ科学を教える
安全性に欠ける、あるいは非科学的な推奨を防ぐために、研究者らはスポーツサイエンス・ナレッジグラフを構築しました。これは専門家が承認した事実を構造化した地図のようなもので、数千のエントリが運動と筋肉、動作種類、機器、一般的な怪我、漸進的過負荷や特異性といったトレーニング原則に結び付けられています。各ユーザーについて、システムはこのグラフの中から最も関連する部分—たとえばベンチプレスがどの筋肉を狙うか、どの動作が肩の問題に悪いか—を取り出し、読みやすいテキストに変換してユーザープロファイルとともに言語モデルへ供給します。言語モデルには注意深く設計されたプロンプトを与え、筋群を日ごとにローテーションする、既知の禁忌を避けるといったルールに従った構造化された複数日トレーニング計画を生成するよう求めます。
計画を構造化し、安全に保ち、時間とともに改善する
LLM-SPTRecは単にテキストを生成するだけではありません。バリデーションモジュールが各プランを硬いルールに照らして検査し、連続する日に同じ主要筋群を過負荷にしないなどの条件を確認し、ナレッジグラフに保存された怪我のリスクとの矛盾をフラグ化します。プランがこれらのチェックに落ちた場合、システムはモデルに再度プロンプトを送り、何が問題だったかを明示的に指摘して安全なプランが生成されるまで繰り返します。システムの学習は二段階で行われます。まず多数の専門家設計プランから学習し、次にフィードバックを用いてさらに洗練します。ここでは、シミュレートまたは実際のユーザー評価が一貫性、目標への整合性、実行満足度の高いプランに報酬を与え、危険な提案には大きなペナルティを与えます。このフィードバックループにより、実践的に機能する推奨へモデルが押しやられます。
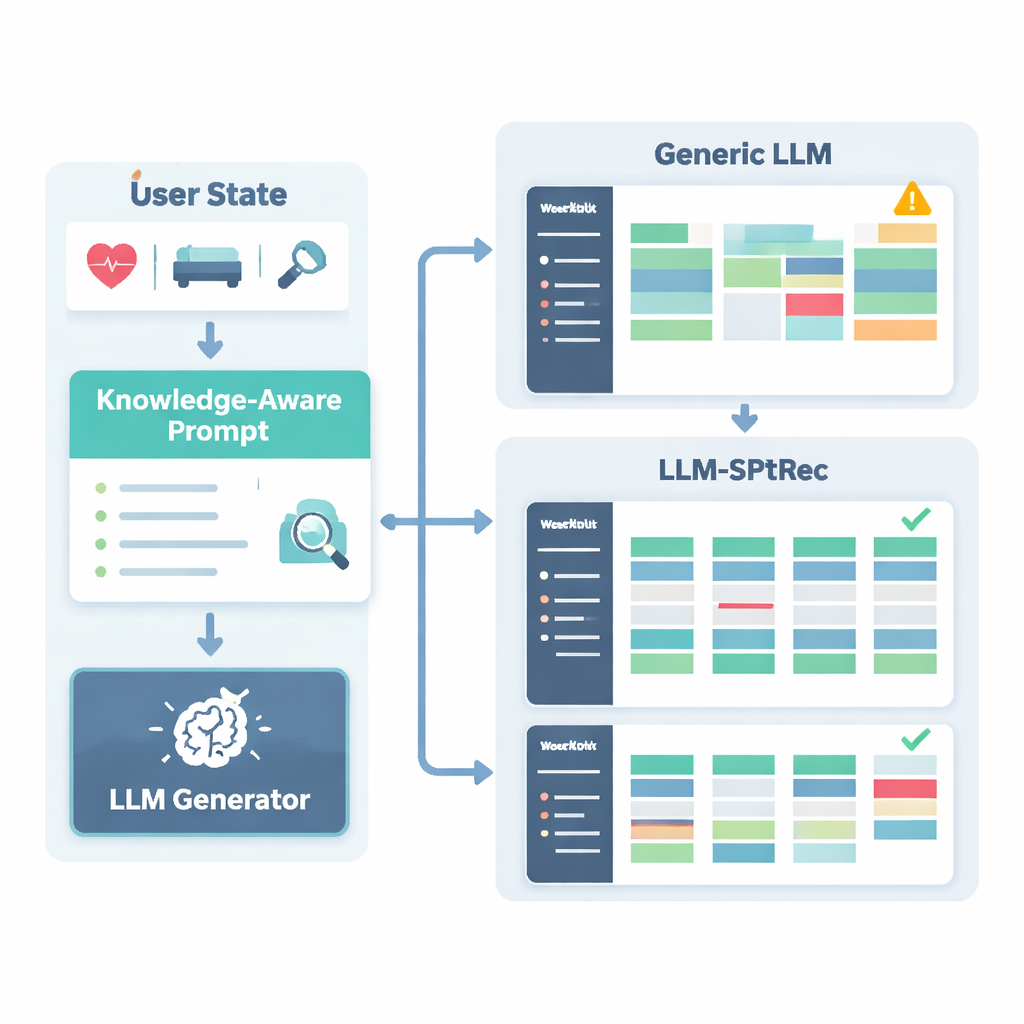
システムの実際の性能
著者らはLLM-SPTRecをSportFit-1Mと呼ばれる大規模な実世界データセットで評価しました。これはフィットネスアプリとウェアラブル機器からの匿名化データを組み合わせ、数万人のユーザーと数百万件のトレーニングログや生理記録を含みます。彼らはシステムを強力なベースラインと比較しました:従来の協調フィルタリング、過去の選択のみを見るシーケンスモデル、最先端のナレッジグラフ型レコメンダー、そして汎用の言語モデルベースのフレームワークです。LLM-SPTRecは適切な運動の選定だけでなく、専門家がより一貫性がありユーザー目標に密接に整合していると評価した完全なプランの生成においても全てを上回りました。予測されるユーザー満足度スコアも高く、認定トレーナーによる小規模な人間評価では、スポーツ特化の根拠を欠く一般的な言語モデルより安全性がはるかに高いと評価されました。
将来のデジタルコーチングが意味するもの
一般向けに言えば、重要な教訓は次の三要素がそろうとより賢く安全なAIコーチングが可能になるということです:デバイスから得られる豊富なデータ、構造化された専門家のスポーツ科学知識、そしてその創造性が慎重に誘導・検査される強力な言語モデル。LLM-SPTRecは、こうした組み合わせが身体の状態変化と個人の目標を尊重する日ごとの適応的トレーニング計画を生成し、有害または不条理な助言のリスクを低減できることを示しています。将来に目を向ければ、同じ手法はワークアウト以外にも栄養、怪我のリハビリ、さらにはメンタルヘルスへと拡張でき、AIアシスタントが汎用的なチャットボットではなく、知識豊富で安全志向のデジタルコーチとして機能する未来を指し示します。
引用: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
キーワード: パーソナライズトレーニング, スポーツサイエンスAI, フィットネス推奨, ウェアラブルデータ, ナレッジグラフ