Clear Sky Science · ja
CNNからトランスフォーマー、マルチモーダル融合へ──物体検出の進化
コンピュータに日常の物体を見せることを教える
あなたのスマートフォンが写真で友人にタグを付けたり、自動車が歩行者を検知したり、医師のツールがスキャン画像上で腫瘍を強調したりするたびに、静かだが強力な技術が働いています:物体検出です。本総説は、初期の画像処理の工夫から今日のトランスフォーマー志向や複数センサーを用いるシステムに至るまで、過去十年で物体検出が如何に急速に進化してきたかを解説し、これらの進歩がより安全な街路、賢いロボット、より正確な医療診断にとってなぜ重要かを示します。
ピクセルから認識可能なモノへ
物体検出は、画像や映像の中で特定の対象──自動車、サイクリスト、動物、医療構造物など──を見つけてラベル付けするタスクです。記事はまず、この能力が自動運転、監視、医用画像、ロボティクスなどでどれほど広く使われているかを概観します。初期のシステムは形状や質感を識別するための手作りのルールに頼っていましたが、現代の手法はデータから直接学習する深層学習が中心です。現在は大きく二つの系統が支配的です:エッジや角などの局所パターンの検出に優れる畳み込みニューラルネットワーク(CNN)と、シーン全体や遠く離れた物体間の関係を理解するのが得意なトランスフォーマーです。これらが組み合わさって、現在の機械が世界を「見る」仕方を定義しています。
従来のビジョンエンジンの仕組み
CNNベースの手法はいまも多くのリアルタイムアプリケーションを支えています。これらは小さなフィルタで画像を走査し、段階的により豊かな特徴マップを構築し、それを検出ヘッドに渡してバウンディングボックスを描きラベルを割り当てます。本総説は二つの主要な戦略を説明します。Faster R-CNNのような二段階システムはまず物体のありそうな領域を提案し、その後それらを精緻化します。高い精度を達成しやすい反面計算コストがかかります。YOLOファミリーのような一段階システムは提案段階を省き、一度の処理でボックスとラベルを予測し、速度を優先して若干の精度を犠牲にします。最近のYOLOv5やYOLOv8は大幅にチューニングされ、小さい物体のための改良された特徴ピラミッド、エッジ機器向けの軽量構成要素、改善された損失関数などを導入し、厳しいベンチマークでも競争力を保ちながら数百フレーム毎秒を達成しています。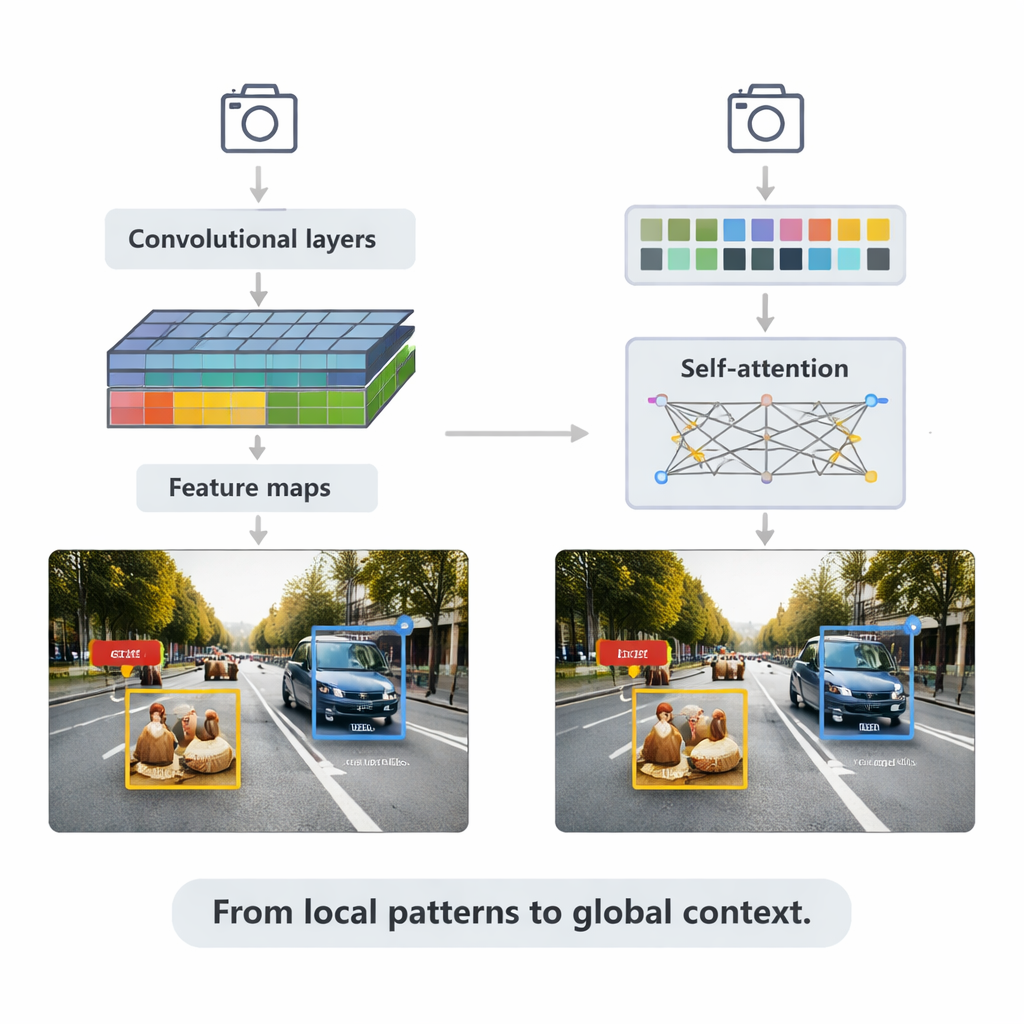
トランスフォーマーと文脈の力
記事は次に、言語モデルから借用された新しいアーキテクチャであるトランスフォーマーに焦点を当てます。局所的な近傍にだけ注目する代わりに、トランスフォーマーは「セルフアテンション」を使って画像のあらゆるパッチ同士を比較し、各判断に最も関連する領域を学習します。Detection Transformer(DETR)やその後継は多くの手作りの工夫を排し、よりクリーンなエンドツーエンドのパイプラインを目指します。Deformable DETRやRT-DETRのような派生は計算量を減らし学習速度を向上させ、トランスフォーマーをリアルタイムで動作させつつ、広く使われるCOCOベンチマークで高い精度を達成できるようにしています。これらのモデルは重なり合う物体や紛らわしい背景がある複雑なシーンで特に優れており、例えば自動車の後ろに部分的に隠れた歩行者を文脈によって識別するのに役立ちます。
カメラ、レーザー、言語の融合
現実世界の条件──霧、暗闇、逆光、乱雑さ──は単一センサーのシステムを挫くことがよくあります。本総説の重要な焦点はマルチモーダル融合です:通常のカメラ(RGB)、LiDARのような深度センサー、サーマルカメラ、さらにはテキスト記述までのデータを組み合わせます。著者らはこの融合がどのように行われるかについて明快な分類を示します:初期融合は生データを前段で混ぜ、ミドル融合はネットワーク内部で学習された特徴を統合し、後期融合は最後に個別の検出器の出力を組み合わせます。最新の“融合トランスフォーマー”はアテンション機構を使ってこれらのストリームを整合させ、LiDARからの精度の高い距離測定、RGB画像からの豊かな見た目情報、言語からの意味的ヒントが互いに補強し合うようにします。このアプローチは自動運転、医用画像、映像理解、テキストの多いシーンで検出性能を向上させます。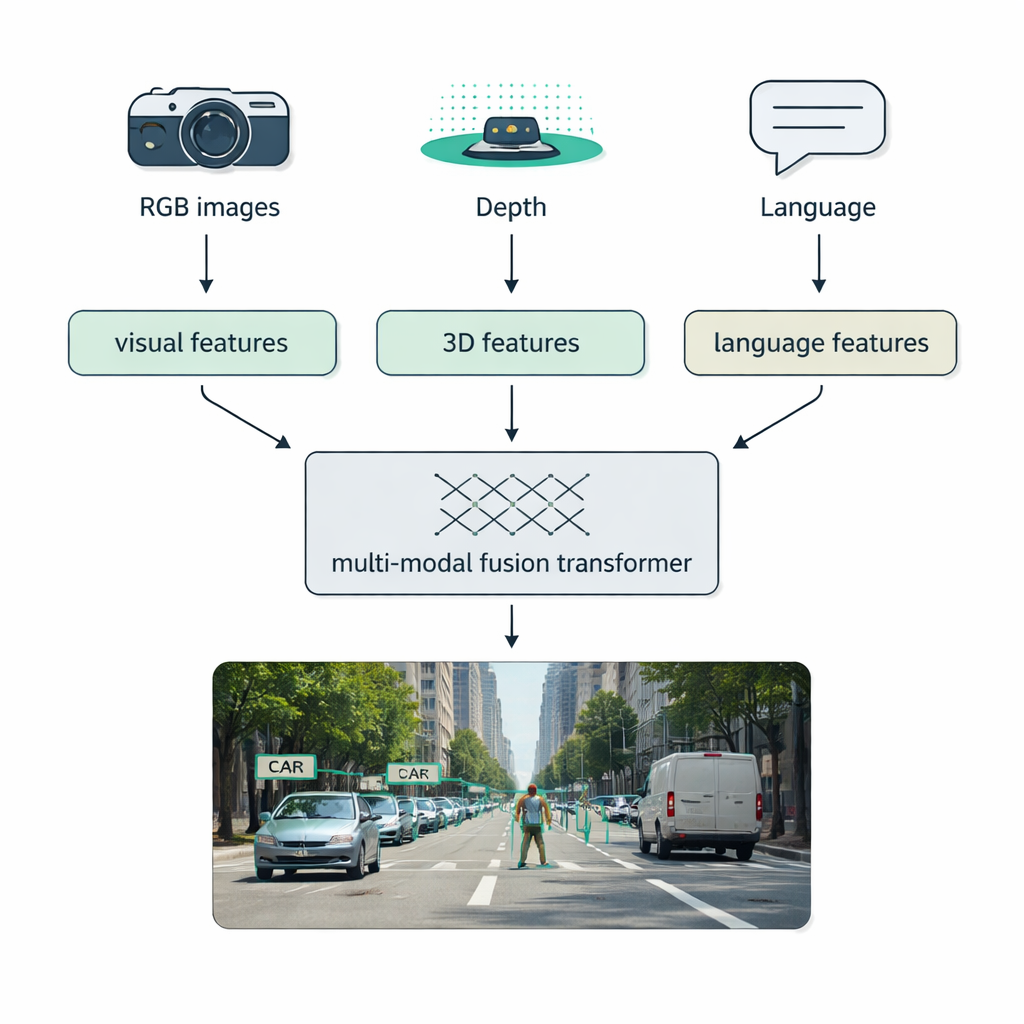
ベンチマーク、限界、そして次に来るもの
MS COCOのような標準テストを通じて、本総説はCNNとトランスフォーマーベースの検出器を精度と速度の両面で比較します。古典的な二段階CNNは依然として強力ですが遅く、YOLOスタイルのモデルは軽量ハードウェアで優位を保ち、トランスフォーマーベースのシステムは精度で先行しつつ速度の差を縮めています。特殊な赤外線手法は視界不良条件で非常に高いスコアを達成します。それでも困難な問題は残っています:極めて小さいまたは非常に大きい物体、強い遮蔽、変わる天候や照明、小型デバイス上での安定動作の必要性などです。将来を見据えて、著者らは検出、セグメンテーション、キャプション生成を一体的に扱う統合的な知覚モデルや、視覚と言語を融合して訓練データにラベルがなくても平易なテキストで記述された物体を認識できる“ファウンデーションモデル”への傾向を強調しています。
日常生活にとってなぜ重要か
専門外の読者に向けた要点は、物体検出が狭く手作りで調整されたシステムから、新しいタスクや環境、センサーに適応できる柔軟で汎用的な視覚エンジンへと移行していることです。CNNは高速で効率的なパターン認識を提供し、トランスフォーマーはよりグローバルで文脈を意識した理解を加え、マルチモーダル融合は深度、温度、言語などの追加手がかりを結び付けます。これらの進歩により、危険をよりよく予測する車、より確信を持って医師を支援するツール、家庭内でより安全かつ賢く周囲とやり取りする機器が期待され、機械の知覚は人間の視覚の豊かさに一歩近づきます。
引用: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
キーワード: 物体検出, コンピュータビジョン, 深層学習, トランスフォーマーモデル, マルチモーダル融合