Clear Sky Science · ja
患者との会話における診断質問の効率を評価するためのベンチマーク
より賢い医療的質問が重要な理由
医師を受診したとき、最初に聞く診断はたいていあなたが挙げた単一の症状からすぐに導かれるものではありません。むしろ、医師は時間経過、強さ、関連する問題など一連の追跡質問を投げかけ、何が問題かを徐々に絞り込みます。今日のAIシステムがどれほど強力であっても、多くはまるで選択式の試験を受けているかのように評価され、実際の人々と話す状況での挙動は十分に検証されていません。本論文はQ4Dxを提案します。これは、適切な診断に効率よく到達するために、適切な質問を適切な順序で選べるかどうか、つまり“好奇心ある医師”としてのLLMの能力を評価する新しい方法です。
試験問題から実際の会話へ
既存の多くの医療AIテストは、教科書の問題のように整った、完全に指定されたケースをモデルに与え、診断を選ばせます。それはシステムが「何を知っているか」を示しますが、患者が詳細を忘れたり日常語で症状を説明したりするような混沌とした実世界の対話でどのように振る舞うかは示しません。著者らはこれを重大な見落としと位置づけます。臨床現場では情報はゆっくり、しかも不正確に出てくることが多く、優れた臨床医の腕は既知の知識だけでなく何を質問するかにも依存します。Q4Dxは静的な質問応答から、時間をかけた質問の戦略へと焦点を移すことで、このギャップを埋めるように設計されています。
実際らしい患者ストーリーの構築
この新しいテストベッドを作るにあたり、研究者たちはまず特定の疾患と代表的な症状群を結びつけた精選された医療リソースを出発点とします。そこから100件の疾患―症状ペアをランダムに選び、AIモデルを用いて無味乾燥な症状リストを診療室で実際に語られるような自然な患者の自己記述に変換します。各完全ケースからは、重要な症状の約80%または50%だけが言及される短縮版を生成します。このように情報を制御して“隠す”ことで、重要な手がかりが欠けている、あるいはほのめかされている場合に各モデルがどれだけ適応できるかを評価できます。症状の重複に関する確認により、短縮版が単に語数が少ないだけでなく、実際に利用可能な情報が少ないことが検証されています。
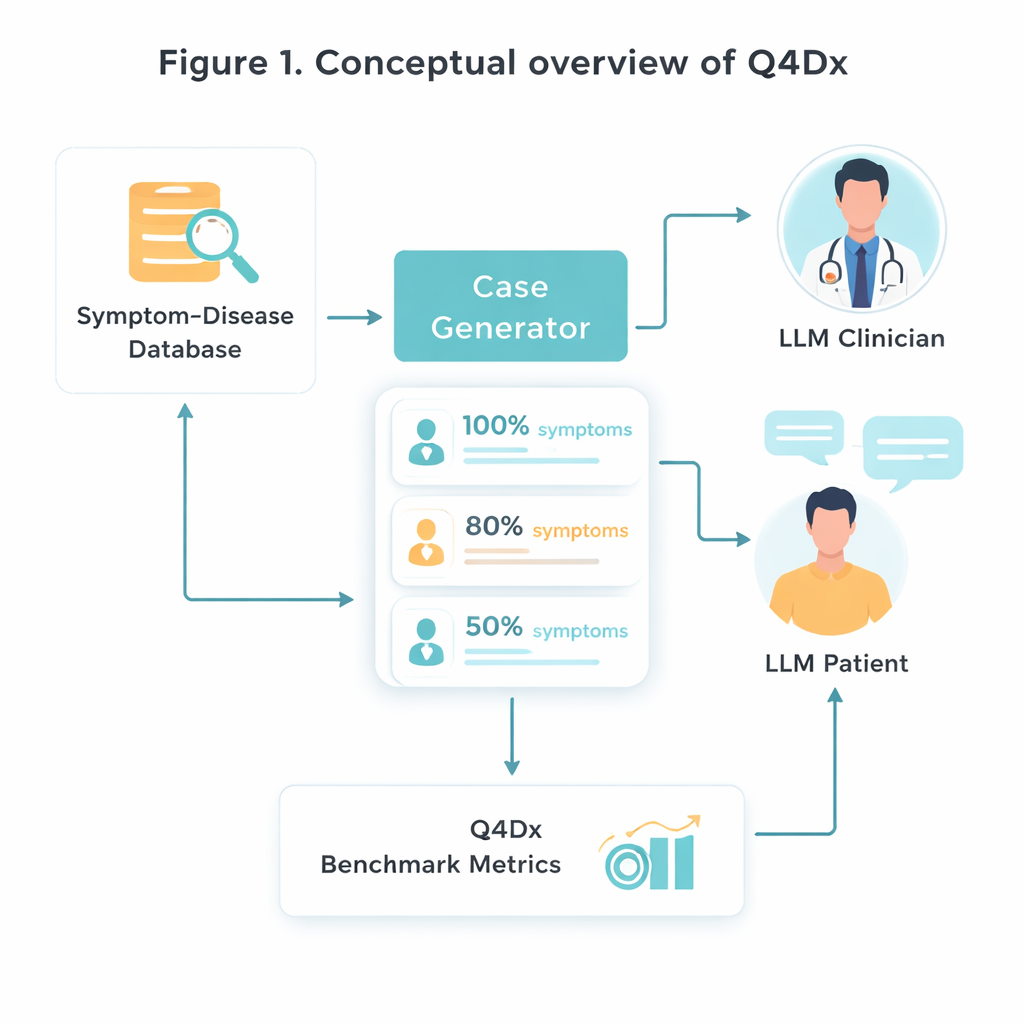
模擬医師―患者対話
Q4Dxの核心は、二つのAIエージェント間の大量の模擬会話コレクションです。一方は患者役を担い、基礎となる疾患とその完全な症状セットに完全にアクセスします。他方は医師役で、開始時には不完全であいまいなケース記述しか見えず、次に何を質問するかを決めなければなりません。患者の応答ごとに、医師エージェントは暫定診断を行い、思考がどのように進化するかの段階的な軌跡を作ります。すべての質問、答え、中間推測を記録することで、このベンチマークはモデルが正しいかどうかだけでなく、そこに至る過程も捉えます。これらのAI生成質問列は参照戦略として用いられます—完全な医療の真理ではなく、将来のモデルや人間の訓練者と比較するための一貫した尺度です。
正解だけでなく良い質問を測る
パフォーマンスを評価するために、著者らは三つの単純だが相補的な指標を設計しました。Zero‑Shot Diagnostic Accuracy(ZDA)は、もしモデルに完全なケースを最初から与えたら、直ちに正しい疾患名を挙げられるかを問います。Mean Questions to Correct Diagnosis(MQD)は効率を反映します:平均して、モデルが最初に正しい診断に到達するまでに何回の患者への質問を要するか(上限は5回)。最後にInterrogation Sequence Efficiency(ISE)は、質問経路そのものの質を見ます—モデルが選んだ質問が参照シーケンスと意味的にどれだけ類似しているかです。これらの指標を用いて、研究チームは汎用の強力なモデル(GPT‑4.1)が完全な情報下で約半分の確率で正しく診断する一方、症状が隠されるとその精度が落ちることを示しました。同時に、その対話的セッションは通常いくつかの適切な質問の後に成功し、ターンが進むごとに専門家に近い戦略とより整合する傾向が見られました。

将来の医療AIにとっての意義
非専門家に向けたこの研究のメッセージは明快です:医療においては、賢い質問をすることは正しい答えを知っていることと同じくらい重要であり、AIはその両方で評価されるべきだということです。Q4Dxはまさにそれを行うための再利用可能で公開された枠組みを提供します。情報が欠けた現実的な患者ストーリー、詳細な会話トレース、正確さと効率の両方を測る明確な指標を備えることで、このベンチマークは研究者が異なるAIシステムを比較し、管理された条件下で人間の臨床医と対決させることを可能にします。時間が経つにつれて、Q4Dxのようなツールはより安全で信頼できる臨床アシスタントの訓練や、医師や学生の診断面接の学習改善に役立ち、最終的には実際の患者に対するより良いケアを支援するでしょう。
引用: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
キーワード: 医療AI, 診断推論, 臨床対話, 大規模言語モデル, 問診戦略