Clear Sky Science · ja
MQADet:マルチモーダル質問応答によってオープンボキャブラリ物体検出を強化するプラグアンドプレイ・パラダイム
なぜより賢い物体検出が重要なのか
スマートフォン、車、家庭用ロボット、検索エンジンはますます、画像内の物体を特定するソフトウェアに依存しています:横断する子ども、テーブルの上の失くした鍵、棚の中の特定の商品など。しかし今日の多くのシステムは「犬」や「車」のような短く単純なラベルしか理解しません。「ソファのクッションの後ろに横たわる赤い首輪をした小さな犬」といった要求をすると、混乱することがよくあります。本論文はMQADetを紹介します。既存の物体検出システムを、基盤モデルを再訓練せずにそのような豊かで詳細な記述を理解できるように強化する方法です。
固定リストから開かれた理解へ
従来の物体検出器は、人気のあるCOCOデータセットにある80種類のような固定のカテゴリリストで訓練されます。対象がそのカテゴリのいずれかに属し、要求が短く明確であればよく機能します。しかし現実世界は雑多です。人は長いフレーズや微妙な属性、関係(例:「トラックの後ろに立っている黄色いベストを着た男性」)を使って物を指します。新しい「オープンボキャブラリ」検出器は画像と言語を結びつけて固定リストの制約を破ろうとしますが、複雑な語句や訓練データに希に現れる長尾カテゴリには依然として苦戦します。また性能向上には大量の計算資源とデータが必要です。
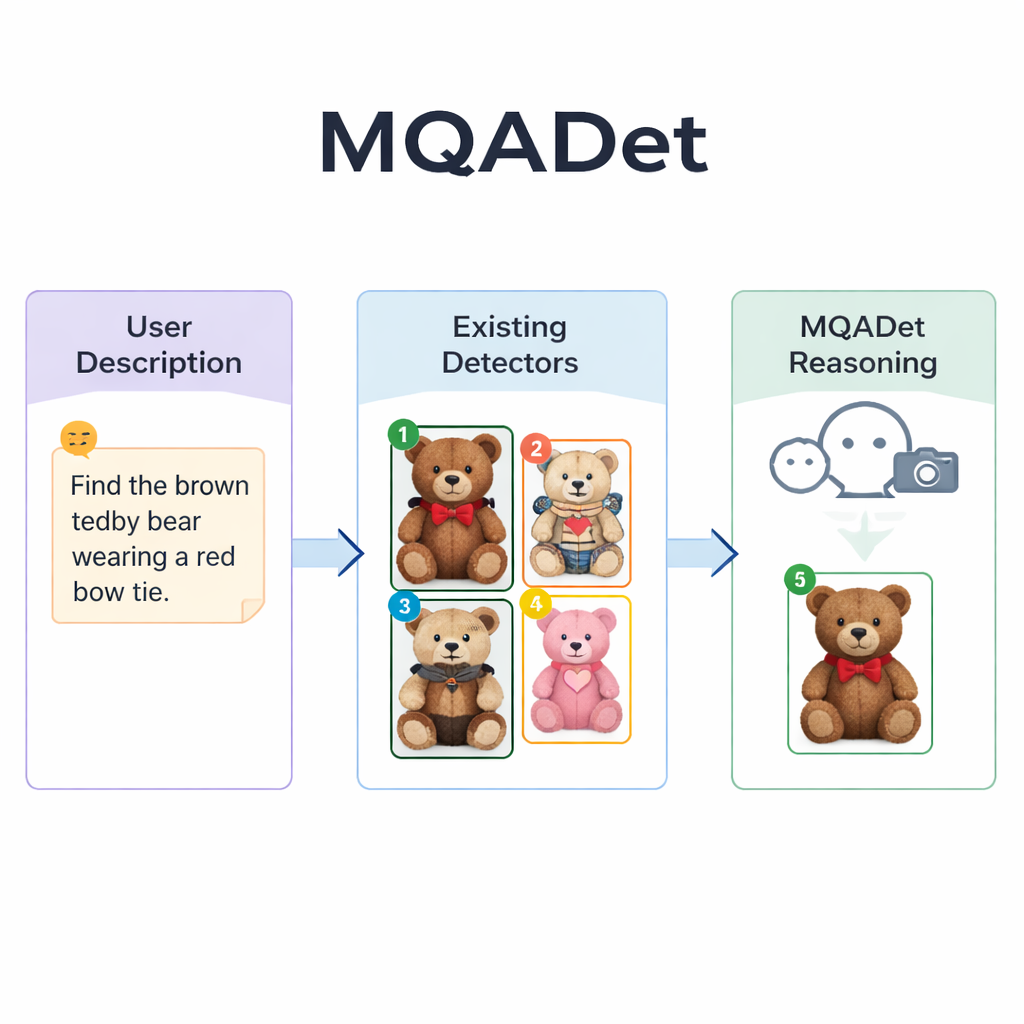
言語モデルに探索を導かせる
MQADetは、既存の検出器の上に画像を見てテキストを読むことができるマルチモーダル大規模言語モデルを置き、三段階の質問応答プロセスでこれらの問題に取り組みます。まず「テキスト認識型対象抽出(Text‑Aware Subject Extraction)」と呼ばれる段階がユーザーの全文を読み、長い記述の中から「傘」や「歩行者」のような真の対象を引き出します。これは、人が場面をスキャンする前に文中の主要な名詞を素早く特定するのに似ています。重要なのは、この段階が言語モデルの自然言語に対する高い理解力を活用するため、単語単位ではなく長い記述的なフレーズを扱える点です。
画像内で候補物体をマーキングする
第二段階「テキスト誘導型マルチモーダル物体位置決め(Text‑Guided Multimodal Object Positioning)」では、抽出された対象と画像を既存のオープンボキャブラリ検出器(例:Grounding DINO、YOLO‑World、OmDet‑Turboなど)に渡します。検出器は各対象について画像内のいくつかの候補位置を提案し、各候補をボックスで囲んでボックス内に簡単な番号を付します。結果として得られるのは、あり得るすべての選択肢を示した「マーキング済み画像」です。重要な点は、MQADetはこれらの検出器を再訓練しないことです。ありのままの検出器を使うだけなので、プラグアンドプレイであり、より優れた検出器が出てきたら追加データやチューニングなしで置き換えられます。

推論で最適な一致を選ぶ
第三段階「MLLMs駆動の最適物体選択(MLLMs‑Driven Optimal Object Selection)」は、最終的な選択を言語モデルへの選択問題に変換します:元の記述と番号付きボックスのあるマーキング済み画像が与えられたとき、どの番号が記述に最も合致するか?モデルは詳細な文言と視覚的配置の両方を参照できるため、模様、色、「左側にある」といった空間関係、物体間の相互作用などの微細な手がかりを総合して判断できます。著者らは、この推論ステップを取り除くと精度が大きく低下することを示しており、その重要性を裏付けています。この三段階設計により、MQADetは長く自然な文を用いる4つの厳しいベンチマークで精度を向上させ、既存検出器の性能を内部の重みを変えずにしばしば10〜40ポイントも改善しました。
日常技術にとっての意義
専門外の人に対する重要なメッセージは、物体検出器を一から作り直さなくても賢くできるという点です。MQADetは既存システムの上に座る知的なアシスタントのように機能し、人の詳細で微妙な記述を解釈して複雑な場面で正しい物体を選ぶのを助けます。これにより、視覚検索、支援ツール、自律機械が、人々が自然に話す詳細や文脈に富んだ表現に対応できるようになり、視覚世界との言語駆動の直感的な相互作用への道を開く可能性があります。
引用: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
キーワード: オープンボキャブラリ物体検出, マルチモーダル大規模言語モデル, 視覚的質問応答, コンピュータビジョン, 画像理解