Clear Sky Science · ja
性能差を埋める:日本語の医療PHI抽出におけるローカルLLMの体系的最適化
なぜ患者のプライバシーに関わるのか
病院には診療記録という膨大なテキスト資産があり、これを活用すれば診療や研究の質を高められますが、記録には氏名、住所、日付などの機微な情報が多く含まれます。強力なクラウドベースのAIはこうした情報の隠蔽に長けていますが、多くの病院では生の患者データを外部サーバーに送信することが許されていません。本研究は、注意深い調整を行えば、院内で完結して動作する小規模なAIモデルでもクラウド上の最先端システムに驚くほど近い性能を出せることを示しており、患者データを院内に保持しつつAIを活用する現実的な道筋を示しています。
プライバシーと進歩のジレンマ
現代の大規模言語モデルは医療文書から保護対象情報(PHI)を高い精度で検出・除去できますが、その多くは90%を超える精度を示します。一方で未加工の患者メモをクラウドサービスに送ることは、HIPAA、GDPR、そして日本の個人情報保護法(APPI)といった規制の下で法的・倫理的な懸念を生じさせます。多くの機関は「データ主権」を重視し、情報が院外に出ないことを求めます。これまで、院内ハードウェア上で動作するローカルモデルは識別子の取りこぼしが多く、病院は高精度な分析を求めてクラウドを使うか、より厳格なプライバシーを取って性能の劣るツールに甘んじるかを選ばざるを得ませんでした。著者らは、このギャップが臨床現場で受け入れられるレベルまで埋められるかを検証しました。
段階的に進めるローカルAI最適化計画
研究チームは、日本語の放射線レポートにおけるPHI除去性能を着実に向上させるため、5段階の最適化フレームワークを設計しました。院内のセキュリティを模したインターネット接続のない孤立したコンピュータ上で実行できる、サイズの異なる14種類のモデルから出発しました。実在感はあるが完全に架空の160件の合成レポートを用い、氏名やID番号、日付、診療科など8種類の識別子を各モデルがどれだけ検出・分離できるかを測定しました。初期のベースライン評価の後、汎用プロンプトを改善し、各モデルの特性に合わせた指示を作成し、自動化された「自己チェック&修正」ループを導入、最後に最良候補を予約しておいたレポート群で評価しました。 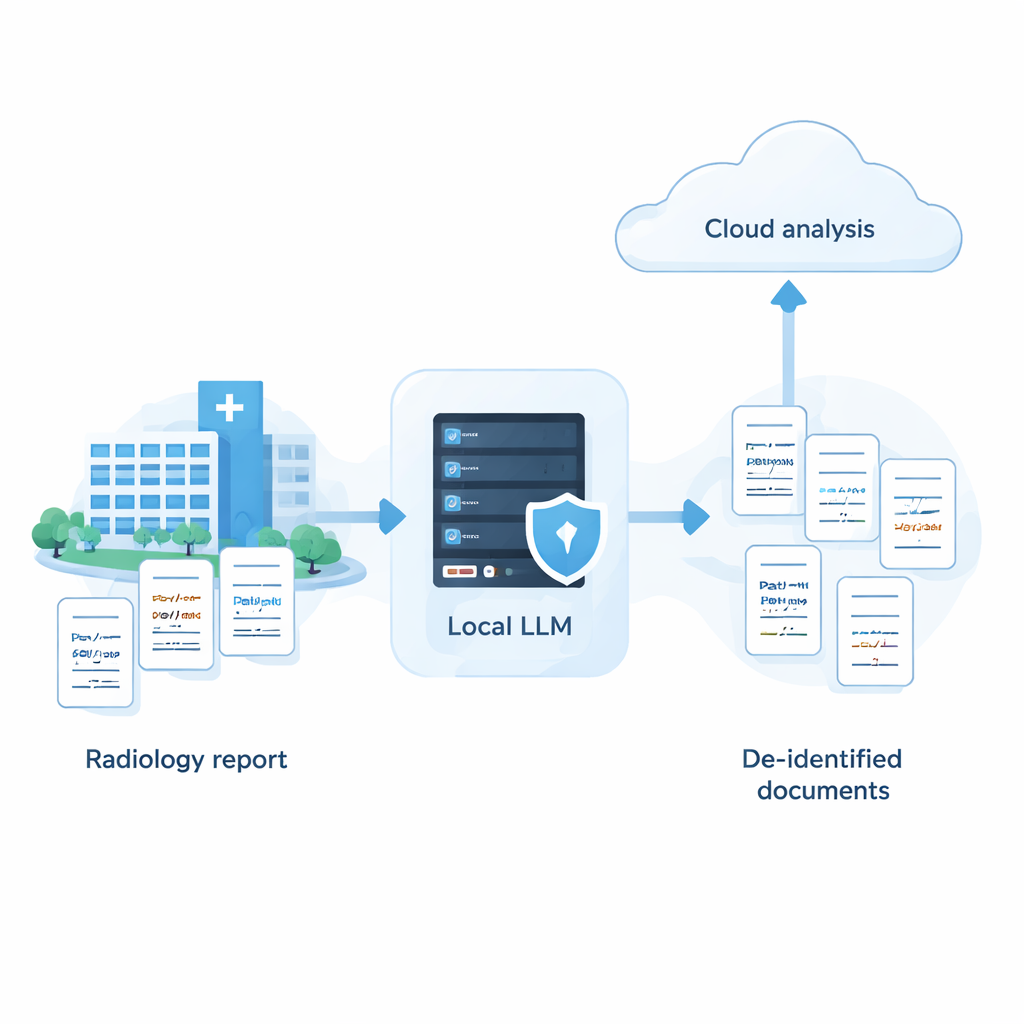
クラウド級の性能に迫る
この段階的プロセスを通じて、著者らは単純なモデルサイズが成功の鍵ではないことを明らかにしました。非常に大きなシステムでも性能が低いものがありました。むしろ、注意深い指示設計とエラー解析に良く反応するモデルが有望でした。中規模の一モデル、Mistral-Small-3.2は、カスタムプロンプトと自己精練ステップ(モデルが自身の出力を検討し、選択的に修正する工程)を経て明確な勝者となりました。最終的な60ケースのテストでは、この最適化されたローカル構成が100点満点中91.54点を獲得し、主要クラウドモデルの93.56点の約97.8%に相当しました。書式ルールの遵守は完全でした。実務上の差は臨床的には小さいと判断されました。主な代償は処理速度で、典型的なレポート1件あたりローカルでは約25秒かかるのに対し、クラウドでは2秒未満でしたが、これは緊急を要さないバッチ処理には許容されると見なされました。 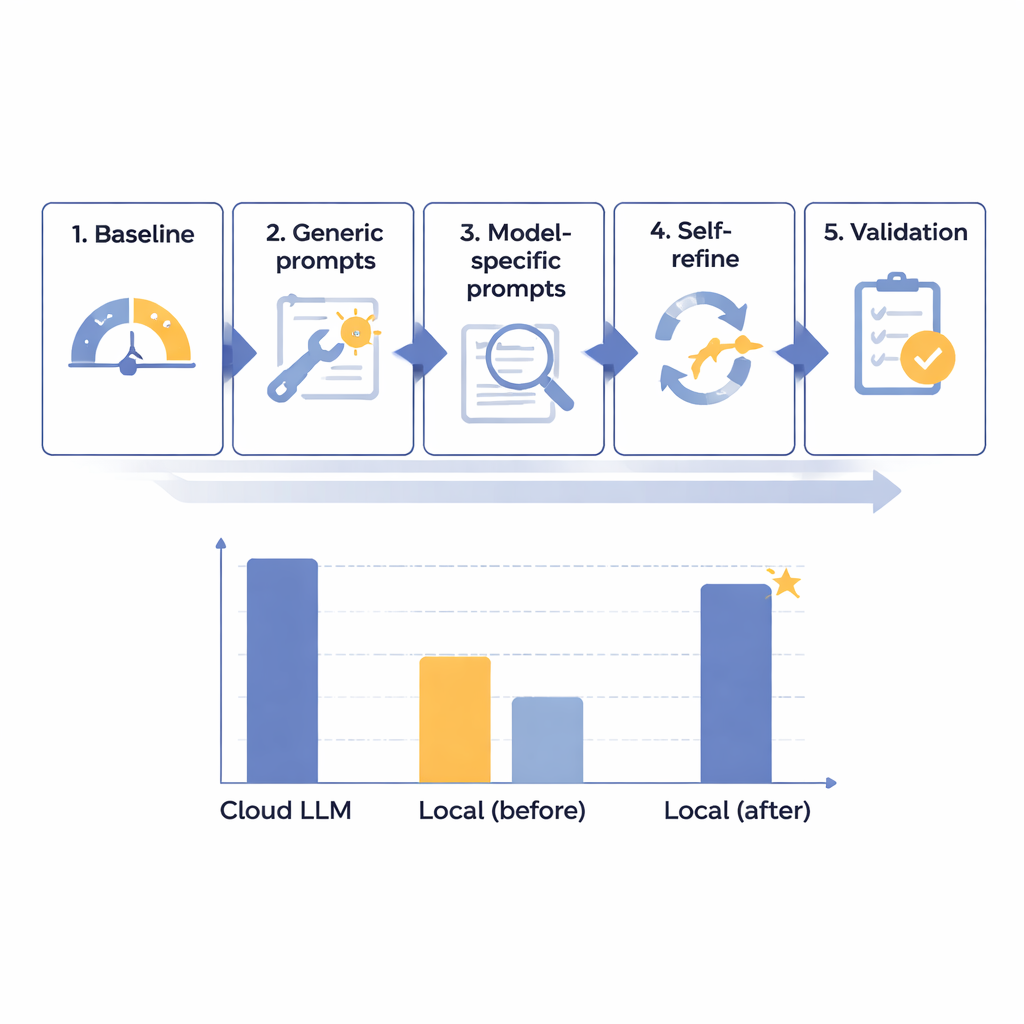
自己修正に関する驚きのしきい値
興味深い発見の一つは、著者らの100点スケールでおよそ87〜88点付近に一種の転換点が存在することでした。ベースラインでこの水準を下回っていたモデル(Mistral-Small-3.2のような)は、自己精練ループによって大きな恩恵を受け、ほんの一部の誤りを修正するだけで約7点改善しました。一方でこのしきい値を既に超えていたモデルはほとんど改善せず、場合によっては正答を「修正」しようとして労力を無駄にしました。これは、高度な最適化ツールを導入するならば「良いがまだ優れていない」モデルに絞るべきであり、計算資源と担当者の工数を最も効果的に配分できることを示唆します。著者らは、このしきい値がわずか二つのモデルに基づく暫定的なものであり、検証が必要だと注意していますが、配備計画の初期目安として有用だと述べています。
病院と患者にとっての意味
本研究は、病院が強いプライバシーと強力なAIのどちらか一方を選ぶ必要はないと主張します。多くのモデルをスクリーニングし、それぞれの長所と短所に合わせてプロンプトを調整し、知的な自己レビューの一歩を加える体系的なアプローチによって、完全にローカルなシステムが医療文書から機微情報を除去する点でクラウドの上位サービスに近づける可能性があることを示しました。実務上はハイブリッド戦略の道が開けます:まず院内所有の機器でPHIを安全に除去し、氏名などの識別子を除いた匿名化済みのレポートのみをクラウドに送ってより高度な解析を行う、という運用です。本研究は合成の日本語放射線レポートに基づくものであり、実データや他言語での検証が必要ですが、患者の信頼とプライバシーを守りつつAIを活用したい機関にとって実行可能なロードマップを提供します。
引用: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
キーワード: 医療の匿名化, 患者のプライバシー, ローカル言語モデル, ヘルスケアAI, 放射線レポート