Clear Sky Science · ja
医療・教育分野データを用いた二段階抽出下での機械学習ベースの分散推定
現実の意思決定で「より賢い平均値」が重要な理由
医師が血圧を調べたり教育者が成績を追跡したりするとき、平均値だけで満足するわけではありません。平均を中心にどれだけ個人差があるかを知る必要があります。この広がり、すなわち変動性は、治験に何人の被験者を募集するか、指導プログラムの規模、あるいは政策判断の信頼度を左右します。本要約の元論文は、古典的な抽出理論と現代の機械学習を組み合わせることで、この変動性をより精密に測る統計的に根拠のある新しい方法を提示し、医療と教育のデータで検証しています。
情報が不完全なときの分散の測り方
理想的には、調査を始める前に母集団の全員について年齢や学習習慣、既往歴などの詳細が分かっていれば便利です。しかし現実には、そのような情報は欠けがちで、集めるのに費用がかかります。著者らはこれに対処するため二段階抽出(two-phase sampling)という設計を用いています。第一段階では大きく比較的安価な標本を取り、年齢やインターネット利用の有無など簡便な背景情報を記録します。第二段階では小さいサブサンプルを抽出して、収縮性の高い結果(収縮力の大きい結果)、たとえば収縮期血圧や期末試験の成績など、コストや時間のかかる測定を行います。課題は、これら二層の情報を使って、母集団全体の結果がどれだけ変動しているかを推定することです。
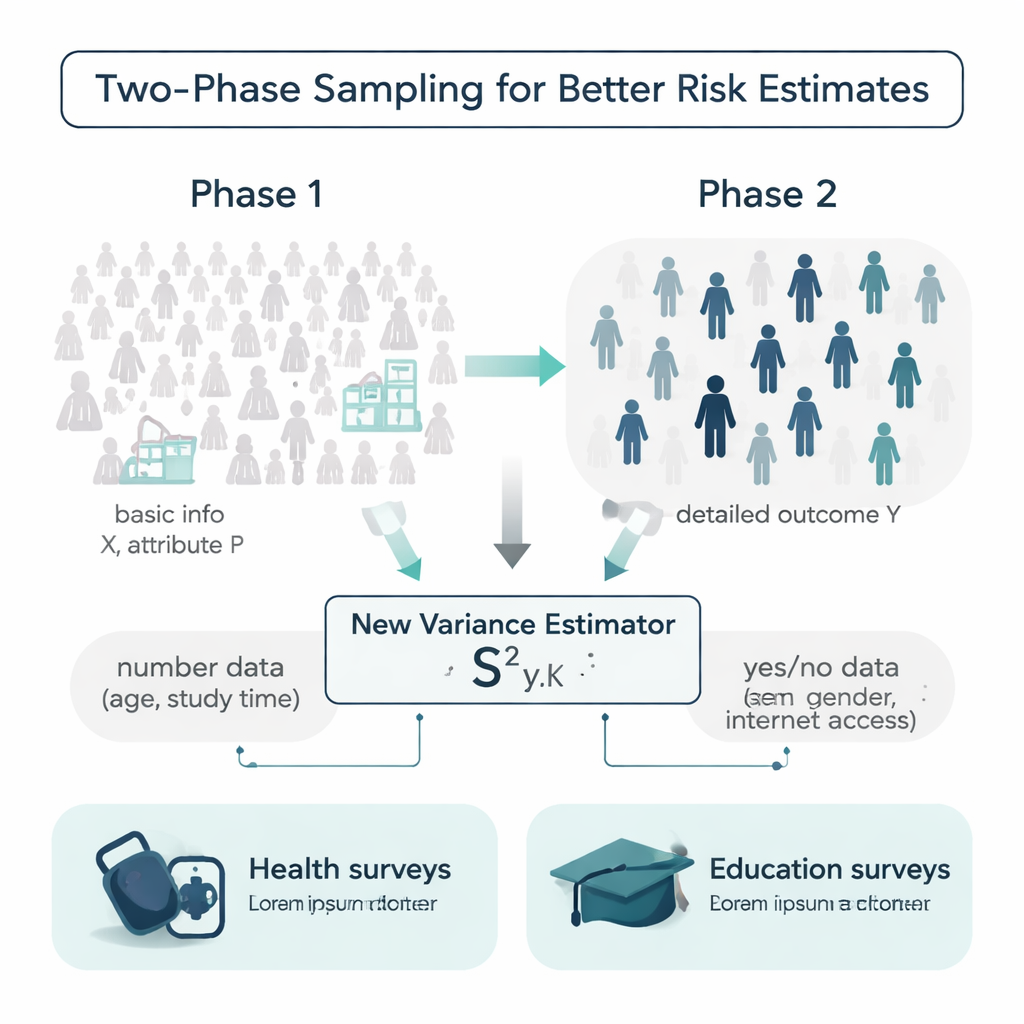
数値と二値属性の両方を使う新しい推定量
従来の多くの分散推定法は、結果変数そのものか単一の補助変数だけに依存し、しばしば正規分布のような都合のよい形を仮定します。著者らは、数値の補助変数(例:年齢や週あたりの学習時間)と二値の属性(例:性別やインターネットの有無)という二種類の補助情報を同時に用いる新しい分散推定量を提案します。数学的にこの「混合」推定量の振る舞いを示し、バイアスと平均二乗誤差という精度の主要指標についての式を導出しています。妥当な条件下では、この推定量は実質的に無バイアスであり、期待誤差が従来の広く用いられる式より小さいため、同じデータ量からより鋭い不確かさの推定が得られることを示しています。
多様なデータ世界で性能を検証
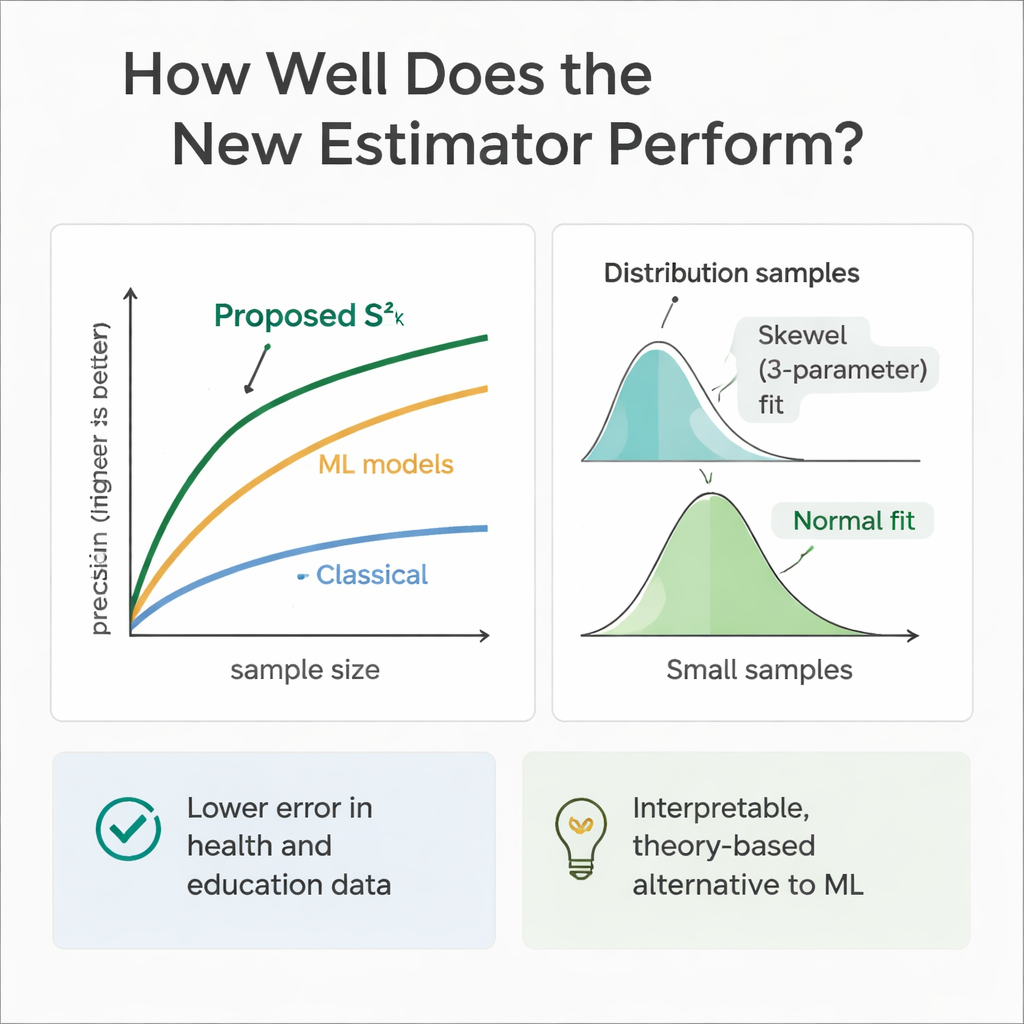
理論が実務に合うか確かめるため、研究チームは大規模な数値実験を行いました。補助変数と結果が従う分布として、対称的な正規分布や一様分布から歪んだガンマ分布やワイブル分布まで幅広くシミュレーションした母集団を用いました。反復抽出を通じて、新しい推定量の誤差を複数の既存手法と比較し、様々な標本サイズで検討しました。ほぼすべての設定で、特に標本サイズが大きくなるにつれて、新手法は相対効率がかなり高くなり、古典的な分散推定量と比べて誤差を30〜70パーセント削減することが多く見られました。さらに、推定量自身の抽出分布の振る舞いも調べ、控えめな標本サイズでは三パラメータ・ワイブル分布が良く当てはまり、標本サイズが大きくなると正規分布に近づく傾向があることを確認しました。
診療所と教室からの実データ
次に、この手法を二つの実データ事例に適用しました。医療データでは結果変数を収縮期血圧とし、数値補助変数を年齢、二値属性を性別としました。教育データでは結果を期末成績、補助は週当たり学習時間、属性はインターネット利用の有無としました。いずれの事例でも、提案した推定量は検討した統計的競合手法の中で最も小さい平均二乗誤差を示し、平均血圧や平均的な学生の成績周りの分散推定を大幅に絞り込みました。これは、より精密な信頼区間や群間/介入効果のより信頼できる比較につながります。
機械学習と比べると
機械学習モデルは予測に優れるため、著者らは同じシミュレーションの医療・教育シナリオで回帰木、ランダムフォレスト、サポートベクター回帰を訓練しました。これらのモデルは同じ補助変数を与えられると、純粋な予測精度の面でしばしば新推定量に匹敵するかやや上回ることがありました。しかし、これらはブラックボックス的に振る舞い、情報をどう組み合わせているかを追跡するのが難しく、従来の調査推論に必要な明確な数式を欠きます。一方、提案推定量は透明性が高く抽出理論に根ざしているため、説明可能性が重要な規制・臨床・政策の場面で正当化しやすい利点があります。
実務の調査にとっての意義
端的に言えば、本研究は研究者が著しく標本サイズを増やさなくても、すでに収集している最小限の追加情報を規律立てて活用することで、より信頼できる変動性の測定が可能になることを示しています。年齢や学習時間のような数値因子と、性別やインターネット利用のような単純な二値属性を二段階抽出計画の下で組み合わせることで、新しい推定量は長年使われてきた方法よりもより鋭く安定した分散推定を提供します。高度な機械学習手法は比較対象として有用ですが、本手法は実用的で解釈可能な中間解を提示し、医療・教育の分析者が限られたデータからより強い結論を引き出すのに役立ちます。
引用: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
キーワード: 調査抽出, 分散推定, 機械学習, 医療データ, 教育研究