Clear Sky Science · ja
宇宙機器の障害報告における分類モデル化と分類法
宇宙飛行の不具合に潜むパターンを探る
宇宙へ出るあらゆるミッションは、ボルトやケーブルから生命維持装置に至るまで無数の機器が確実に動作することに依存しています。何かがうまくいかないと、エンジニアは詳細な不一致報告を書きますが、NASAには現在5万4千件以上の記録があり、人が一件ずつ読むにはあまりに多すぎます。本研究は、最新の言語処理と機械学習の手法が、その膨大なテキストの山を整理された知識に変え、エンジニアが故障のパターンを見つけ、設計を改善し、宇宙飛行士の安全を高めるのにどう役立つかを示します。
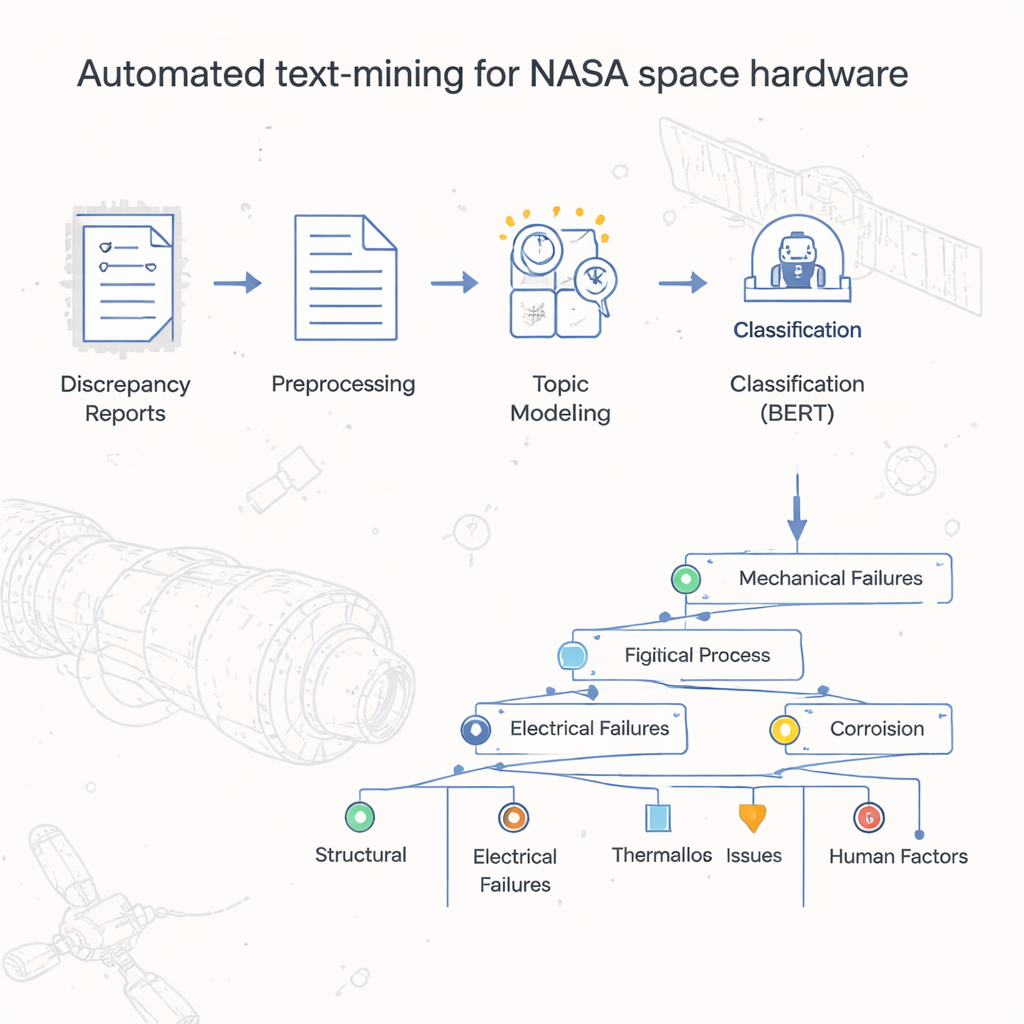
報告の山から得られる整理された洞察へ
数十年にわたり、NASAのジョンソン宇宙センターは機器の故障や不一致の報告を、古い紙の様式をスキャンしたようなデジタル文書として保存してきました。基本的な表計算による集計では公式の欠陥コードの出現頻度は分かりますが、実際の原因や手順、問題が発生した状況といった本当の情報は自由記述欄に埋もれていました。5万4千件以上を手作業で読んで分類するのは現実的ではありません。著者らはこれらの報告を自動で分類・群分けする方法を構築し、現場で実際に機器がどのように故障するかを捉える一種の「地図」やタクソノミーを作ることを目指しました。
エンジニアリング言語をコンピュータに教える
研究チームはまず、各報告のテキストをコンピュータが扱いやすい形にきれいにしました。ノイズとなる記号や数字を取り除き、文を単語単位に分割して、語形変化を基本形に戻す(例えば「leaked」や「leaking」を「leak」にする)などの処理を行いました。「the」や「and」のような意味の薄い一般的語は除去されました。標準化が済むと、研究者らは文書を機械学習アルゴリズムが扱える数値に変換しました。これは単語の出現頻度や、その単語が文書をどれだけ特徴づけるかを捉える既存の手法を用いて行われました。この基礎作業により、一般的な言語処理向けに開発された強力なツールを、宇宙機器の専門的な報告の世界に応用できるようになりました。
故障タイプのツリーを構築する
プロジェクトの中心には、著者らがLDA-BERTと呼ぶ二段階モデルがあります。第一段階のLatent Dirichlet Allocation(LDA)は、何千件もの報告にまたがって一緒に現れがちな単語のパターンを探し、トピック(テーマ)を自動的に発見します。一つの報告は複数のトピックを含み得るため、現実の複合的な故障を反映します。第二段階では、現代的な言語モデルであるBERTを用いて、これらのトピックが報告をどれだけ分離できているかを検証・精練します。LDAのトピックを仮のラベルとして扱い、BERTにそれらを予測させることで、安定して精度の高い分類を与えるトピックの数と組み合わせを特定しました。さらに各トピックをクラスタリングや統計的検査で細分化し、広い欠陥コードから詳細なプロセスレベルのラベルへと分岐するタクソノミーを構築しました。
タクソノミーを実用的なトレンドに変える
タクソノミーが整うと、チームはそれをダッシュボードや対話的ツールで可視化しました。ツリーの各枝や小枝は、報告内の他の情報(問題が最初に記録された時期、解決に要した時間、責任組織、最終決定など)に結び付けられます。時系列プロットにより、検査の見落としや公差データの問題といった特定の種類の問題が年ごとに増えているか減っているかを示せます。ワードマップは各クラスタで使われる言葉の雰囲気を、すべての報告を読むことなく素早く提示します。これらの可視化は、管理者がトレンド上昇かつ影響の大きいプロセスの失敗に注力し、訓練、手順改訂、設計改善などを効果的に進めるのに役立ちます。
自動化された原因探索の限界
研究者らは、ラベル付けやトレンド検出を超えてテキストから直接的な因果関係を推測しようとするツールも検討しました。INDRA-Eidosのようなシステムや、spaCy言語ライブラリで構築したカスタムルールセットを試しました。これらのツールは一部の因果ペアを抽出して対話型ネットワークとして可視化することはできましたが、多くの提案されたリンクは曖昧で実用性に乏しいものがありました。実際には、元の報告書が根本原因を明確に記述していないことが多く、エンジニアがそれを暗示したり後日の調査に委ねたりしているため、モデルは苦戦しました。本研究は、信頼できる自動根本原因発見を実現するには、可能性のある原因を明示する入力欄のようなより豊かなデータ入力と、この単発の分析のためにはコストがかかりすぎる、より入念で個別調整されたモデル訓練が必要だと結論づけています。
将来のミッションにとっての意義
大量で非構造化な故障報告アーカイブを、明確で階層化されたタクソノミーに変えることで、本研究はNASAに対して機器の問題が時間とともにどのように発生し、なぜ生じるのかを監視する実用的な手段を提供します。方法論はまだ深い根本原因分析において人間の判断を置き換えるまでには至りませんが、膨大なテキストをスキャンして問題が集中している領域や関与しやすいプロセスの種類を浮き彫りにする点で優れています。こうした早期警戒と構造化された洞察は、エンジニアリングチームが注力すべき点を絞り、手順を洗練し、より堅牢なシステムを設計するのに役立ちます。これらは月や火星、さらにその先へのより安全で信頼性の高いミッションに向けた具体的な一歩です。
引用: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
キーワード: 宇宙機器の故障, 自然言語処理, トピックモデリング, エンジニアリングのリスク解析, NASAの不一致報告書