Clear Sky Science · ja
連結されたBERTとGloVe埋め込みを用いたディープラーニングによるウルドゥー語ニュースの信憑性検証
ウルドゥー語のフェイクニュースを見抜くことがなぜ重要か
パキスタンや世界中で、新聞やテレビよりもウェブサイトやソーシャルメディアからニュースを得る人が増えています。この変化により、とくにデジタルツールが限られる国語であるウルドゥー語では、誤った記事が急速に拡散しやすくなりました。本研究は単純だが緊急性の高い問いに取り組みます:現代の人工知能は、普通の読者、ジャーナリスト、プラットフォームが誤情報から身を守るのを助けるために、ウルドゥー語の実際のニュースと偽のニュースを自動で識別できるか?
オンライン上の誤情報という増大する課題
著者らはまず、捏造された見出しや歪められた記事が世論を形成し、政治的緊張を煽り、人々の健康や財政に害を及ぼす可能性があることを説明します。多くのファクトチェックサイトや研究は英語に集中している一方で、ウルドゥー語などの地域言語はしばしば取り残されます。既存のウルドゥー語資源は数千件程度のニュースしか含まず、多くが英語から翻訳されたもので、政治のような限定的なトピックに偏っていることが多い。これでは、パキスタンの多くの人々が実際に読む言語で疑わしいコンテンツを識別する信頼できるコンピュータシステムを学習させるのは難しいのです。
大規模なウルドゥー語ニュースコレクションの構築
このギャップを埋めるため、研究者らは2017年から2023年にかけて、信頼できるパキスタンのニュースサイトやオンラインプラットフォームから収集した14,178本のニュース記事を含む、これまでで最も広範なウルドゥー語フェイクニュースデータセットを構築したと述べています。収集された記事は政治、健康、教育、ビジネス、犯罪、スポーツ、環境など日常生活の15分野にわたります。PolitiFactやFactCheck、専門のニュースAPIなどのファクトチェック情報を用いて、各記事に真偽ラベルを付与し、一部真実を含む記事はより微妙な報道を反映するため実際のニュースと同じグループにまとめられました。さらに、重複、ウェブアドレス、不必要な句読点を削除し、文を単語に分割し、頻出するフィラー語を取り除くなどの前処理でテキストをクリーン化しました。
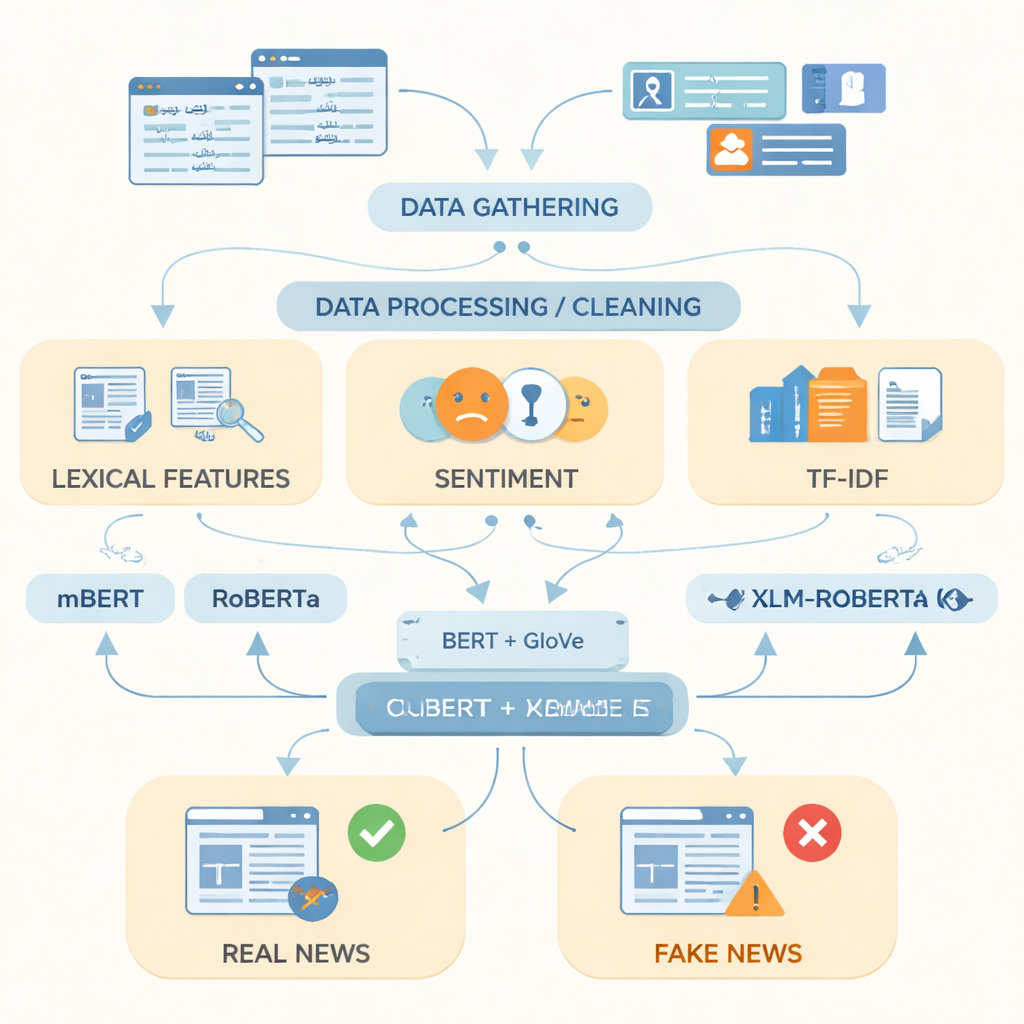
コンピュータにフェイクニュースの特徴を学習させる
データ準備の後、著者らはウルドゥー語テキストをコンピュータがどう表現するかに注力しました。頻出語や言語の感情的トーン、用語頻度スコアのような単純な指標に加え、二つの強力な単語表現手法を組み合わせました。一つはGloVeで、これは各単語をコレクション全体で他の単語と同時に出現する頻度に基づく固定数値ベクトルとして扱います。もう一方はBERTスタイルのモデルに基づき、各単語を文脈の中で見て文脈対応の意味を割り当てます。これら二つの言語の見方を結合することで、全体的なパターンと、偽と真の記事を区別する微妙な語法の変化の両方を捉えられるより豊かな表現が得られます。
先進的な言語モデルの実証試験
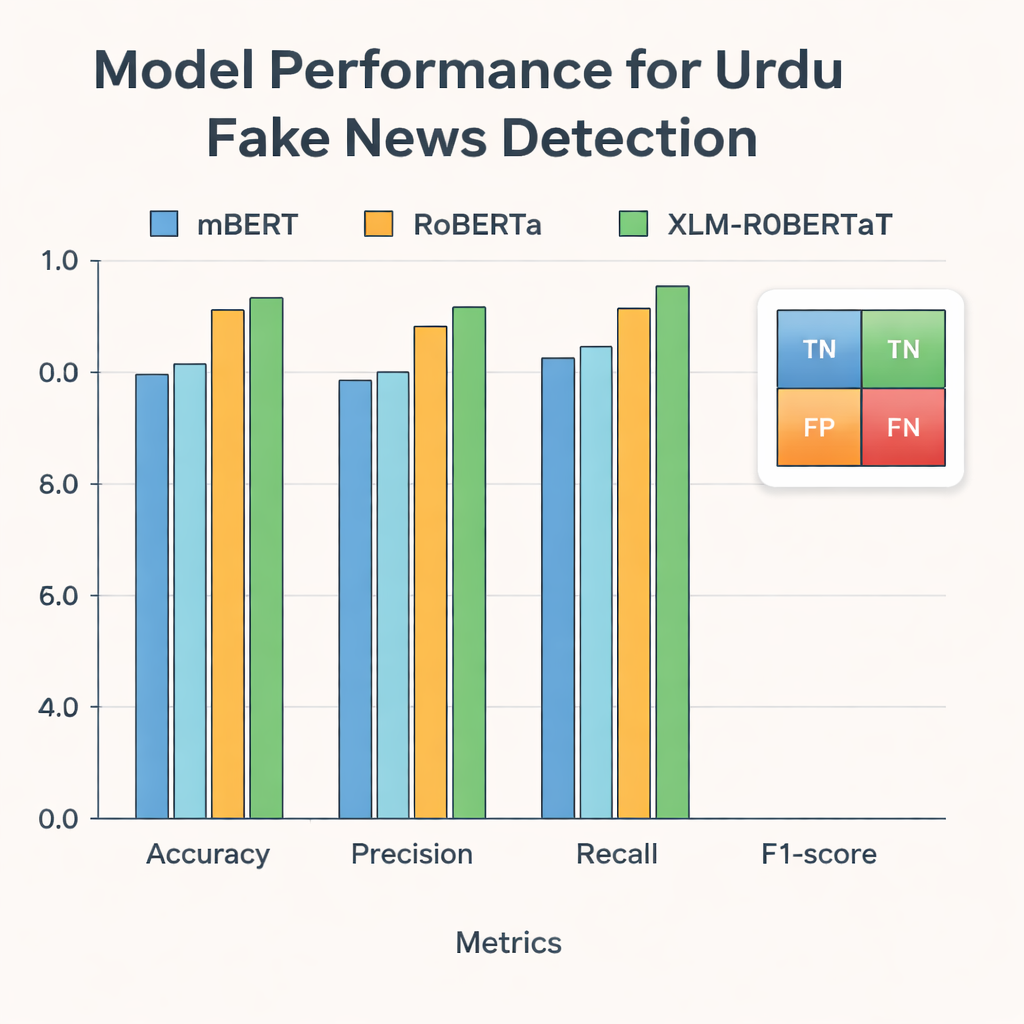
研究者らはこれらの表現を多言語のテキストで事前学習された三つの最新のディープラーニングモデル—mBERT、RoBERTa、XLM-RoBERTa—に入力し、ウルドゥー語データセットでファインチューニングして各記事が真か偽かを予測させました。性能は標準的な指標で評価しました:正解率(どれだけ正しく分類したか)、適合率(偽と判定した中で実際に偽であった割合)、再現率(全ての偽記事のうちどれだけ検出したか)、そして適合率と再現率のバランスをとるF1スコアです。全モデルが高い性能を示したものの、連結されたBERTとGloVe表現を用いたXLM-RoBERTaが最良の結果を示し、テスト記事の約96%を正しく分類し、F1スコアは0.956に達しました。これは、より小さなデータセットや単純な手法を用いた従来のウルドゥー語フェイクニュースシステムを上回る成果です。
一般の読者にとっての意味
非専門家向けの結論は明快です:十分な高品質なウルドゥー語ニュースデータと適切なAIを組み合わせれば、偽である可能性の高い記事を高い信頼性で自動的に検出するツールを構築することが可能になりました。本研究は、より豊かな言語表現と多言語モデルが、地域やトピックごとに実際のウルドゥー語の書き方をコンピュータがよりよく理解するうえで有効であることを示しています。現在の研究はテキストのみに焦点を当て、画像やソーシャルメディア上の振る舞いはまだ解析していませんが、言語やメディア種を越えて応用できる将来のシステムのための強固な基盤を築いています。実用面では、本研究はブラウザプラグイン、ニュースルームのダッシュボード、ソーシャルメディアのフィルタなど、日常的に使う言語で事実と虚構を分ける手助けをするツールに向けてパキスタンを一歩前進させます。
引用: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
キーワード: フェイクニュースの検出, ウルドゥー語, ディープラーニング, BERTとGloVe, オンラインの誤情報