Clear Sky Science · ja
カーネル平均整合は空間的分布シフト下でのリスク推定を改善する
地図が変わるときのモデルリスクを考える意義
機械学習モデルは、種の生息地予測や組織内での腫瘍の配置、汚染の拡散予測などにますます使われています。ところが、これらモデルの学習に使われるデータは都市や病院、アクセスしやすいフィールドサイトの近傍など、ごく特定の場所で密に採取されることが多く、モデルはより広範で異なる領域に適用されます。データの収集場所と予測が行われる場所の不一致は、モデルを実際より安全で高精度に見せてしまうことがあります。論文「Kernel mean matching enhances risk estimation under spatial distribution shifts」は、一見単純な問いを投げかけます:世界が学習データと違って見えるとき、モデルはどれだけ誤る可能性があり、その誤差をどうやって見抜けるか?
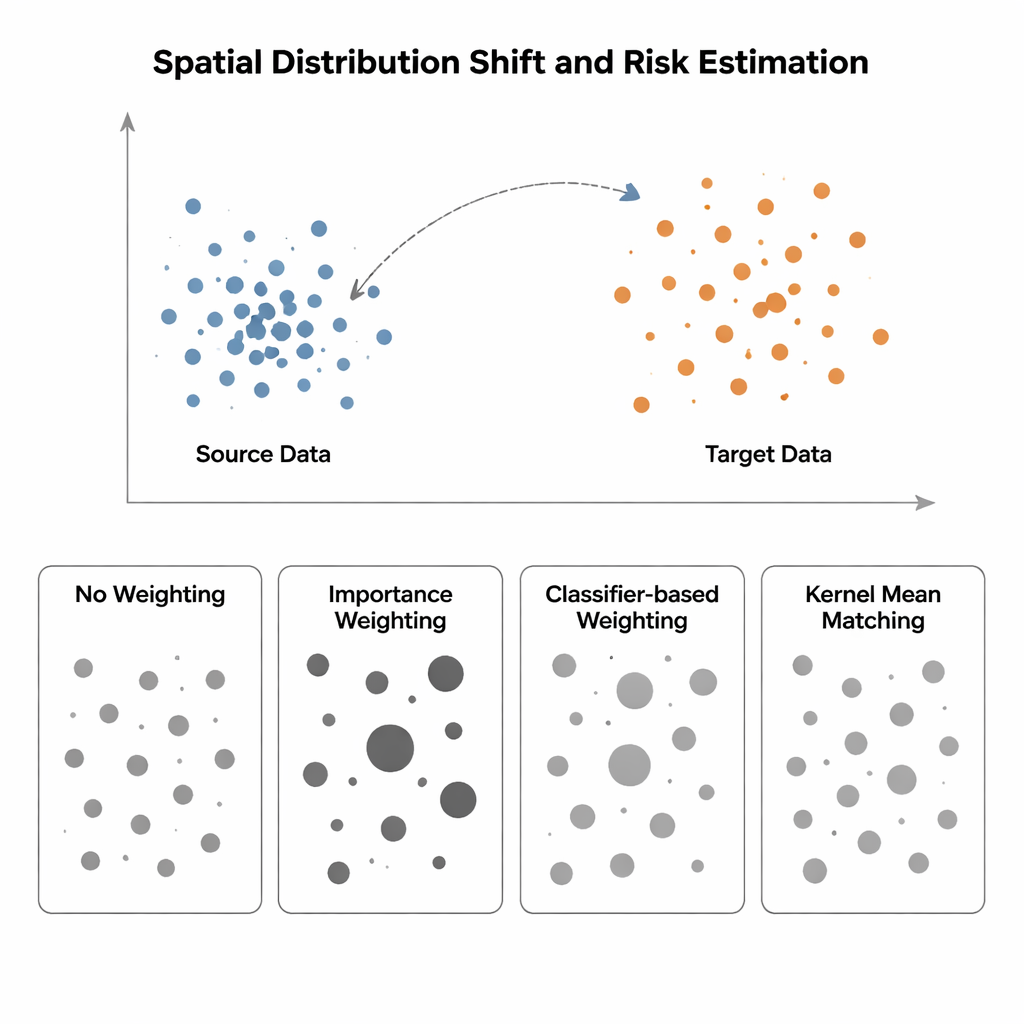
訓練とテストが異なる世界にあるとき
統計学でいうモデルの「リスク」は、新しい未観測データに対する期待誤差です。クロスバリデーションやランダムに分けたテストセットといった標準的な評価手法は、訓練データとテストデータが同じ分布から引かれていると暗黙に仮定しています。空間データはこの仮定を壊します。環境の勾配、クラスタ化されたサンプリング、変化する気候などにより、モデルを訓練した条件と展開先の条件が大きく異なることがあります。たとえば、種の観測は道路付近に集中しがちである一方、保全判断は人里離れた地域に関するものですし、腫瘍のサンプルは組織のある一部から採取されるが、予測は別の場所で必要になることがあります。こうした場合、従来のリスク推定は楽観的すぎる傾向があり、新しい場所でモデルがどれほど失敗するかを過小評価してしまいます。
従来の手法は空間バイアスに弱い
本研究は、入力分布が「ソース」領域(ラベルが既知)から「ターゲット」領域(ラベルが乏しいまたは欠如)へと変化する場合に、モデルリスクを推定する4つの方法を比較します。最も単純な方法であるNo Weightingは、利用可能なデータ上の平均誤差をそのまま測り、ソースとターゲットが類似していると仮定しますが、空間的バイアスがあるとこの仮定は崩れます。Importance Weightingは、ソースの各サンプルに対してその種類の点がターゲットでどれだけ一般的かをソースと比較して重みを付与することで補正しようとします。理論上は正しいリスクを回復できますが、実際には高次元の確率密度を推定する必要があり、ソースデータが強くクラスタ化されターゲットがより散在しているといった典型的状況では、これらの密度推定は不安定になり、一部のサンプルに非常に大きな重みがついてリスク推定が極端に不安定になります。ソースとターゲットの点を区別する分類器を訓練し、その確率を重みに変換する分類器ベースの手法は、明示的な密度推定を回避しますが、分布整合ではなく分類精度を最適化するため、しばしばリスクを誤って較正してしまいます。
別の道:分布を直接整合させる
著者らは、密度推定を回避するアプローチであるカーネル平均整合(Kernel Mean Matching, KMM)を推奨します。各点がソースとターゲットの下でどれだけありうるかを計算しようとする代わりに、KMMはソースサンプルに重みを付けて、それらの平均的な「署名」を柔軟なカーネル定義された特徴空間でターゲットサンプルのものと一致させる重みを探索します。直感的には、それぞれのソース点の影響力を伸縮させ、重み付きのソース点群がターゲットの点群と似た見た目になるようにするわけです。こうして得られた重みを用いて、リスクはソース誤差の重み付き平均として推定されます。補助的なツールであるローカル相関関数(Local Correlation Function)はデータが空間的にどれだけクラスタ化されているかを定量化し、いつ再重み付けが有効になりそうかを診断する役割を果たします。
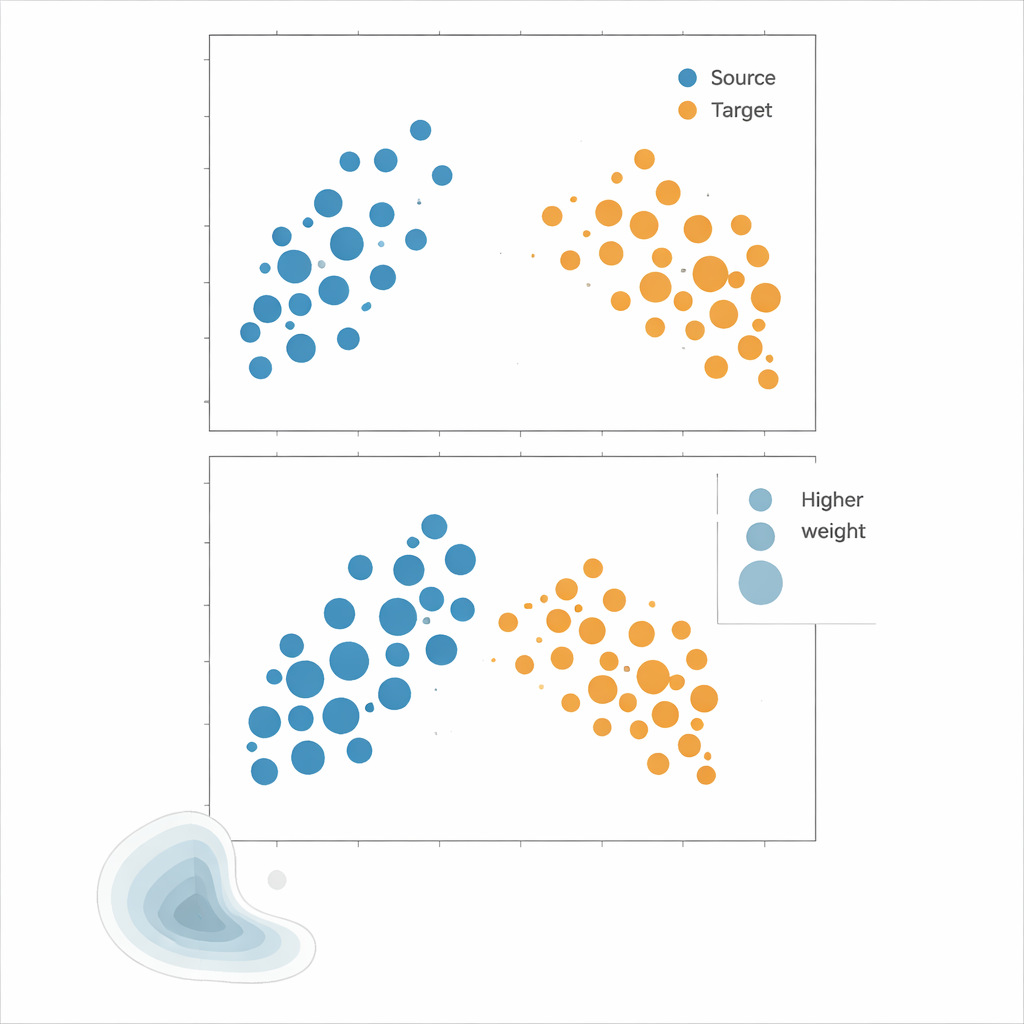
手法を実地で試す
どの戦略が最も有効かを検証するために、著者らは合成データと実データの両方で大規模な実験を行います。合成の「ランドスケープ」は、分布の広がり、形状、領域被覆を精密に制御できるガウス混合クラスタから構成され、領域の一部を切り取る、特徴間の相関パターンを変更する、強くクラスタ化された点パターンとほぼ一様な点パターンを切り替えるといった構造化されたテストが可能です。実データには気候と位置で記述された北欧の植物種の出現データや、腫瘍内の免疫細胞の空間配置が含まれます。これらのシナリオ全体で、モデルはクラスタ化されたソースデータで訓練され、より散在したターゲットデータで評価され、一般的なサンプリングバイアスを模倣します。性能は複数の誤差指標で評価され、各手法の推定リスクがターゲット上の真の誤差をどれだけ追跡するかに着目します。
乱れた高次元空間でもより信頼できるリスク
ほとんどすべての合成設定と実データにおいて、KMMは最も正確で安定したリスク推定をもたらしました。平均絶対パーセント誤差を代替手法と比べておおむね12〜87パーセント削減し、特に高次元でImportance Weightingに生じる「重みの爆発」を回避する点が重要です。例えば、困難な腫瘍細胞配置のケースでは、Importance Weightingが数千パーセントを超える誤差を生むことがある一方で、KMMは管理可能な範囲にとどまります。分類器ベースの再重み付けは、素朴な方法より改善することが多いものの、分布の忠実な整合ではなく識別に重きを置くため、依然としてKMMに及ばないことが多いです。これらの結果は、データがクラスタ化されバイアスを伴い高次元である空間的応用において、KMMがモデル予測にどれだけの信頼を置けるかを推定するための理にかなった手段を提供することを示唆しています。
現実の意思決定への含意
生態学、環境科学、あるいは生物医学で機械学習を使う非専門家に向けたメッセージは明快です:展開先の領域がデータの取得場所と異なる場合、標準的なテストスコアは危険なほど誤解を招く可能性があります。カーネル平均整合は、訓練サンプルの影響力を再バランスして、統計的に関心のある場所や組織に似せることでこの問題を是正する方法を提供します。本研究は、このアプローチが厳しい空間バイアスや多くの入力変数がある場合でも一貫してより正直なモデル誤差推定をもたらすことを示しています。実務上は、モデル選択の際により信頼できる指針を与え、予測が信頼できる領域と注意が必要な領域をより明確にすることを意味します。
引用: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
キーワード: 分布シフト, 空間モデリング, カーネル平均整合, モデルリスク推定, 生態学および生物医学データ