Clear Sky Science · ja
非パラメトリック認知診断モデリングを用いた医学における大規模言語モデルの微粒度評価
将来の診察にとってなぜ重要か
会話や文章生成ができる人工知能システム、いわゆる大規模言語モデルは研究室から病院へ急速に移行しつつあります。これらは既に医師が複雑な検査結果を読み解いたり、治療案を提案したり、医学的な質問に答えたりするのを助けられます。しかし、これらのシステムの多くの評価は最終試験の成績のような単一の総合スコアしか示さず、危険な盲点を覆い隠してしまうことがあります。本研究は、そのスコアの内側を新たな方法で精査し、モデルが実際に理解している医学領域と、患者にとって依然として危険となり得る領域を明らかにします。
単一スコアを超えて見る
現在、医療用AIの評価の多くは医師免許試験を模した問題で何問正答したかで判断されています。この方法は単純ですが粗雑です。モデルが総合点で高得点を取っていても、心電図解析や肝疾患のような重要分野で弱点を抱えている可能性があります。臨床現場では、そのようなギャップが生死を分けることがあります。著者らは、医療でAIを安全に使うには、単に誤解を招くかもしれない一つの成績を与えるのではなく、より深く、より微細な評価—詳細なスキルプロファイルを描ける評価—が必要だと主張します。

医療知識を試すより賢い方法
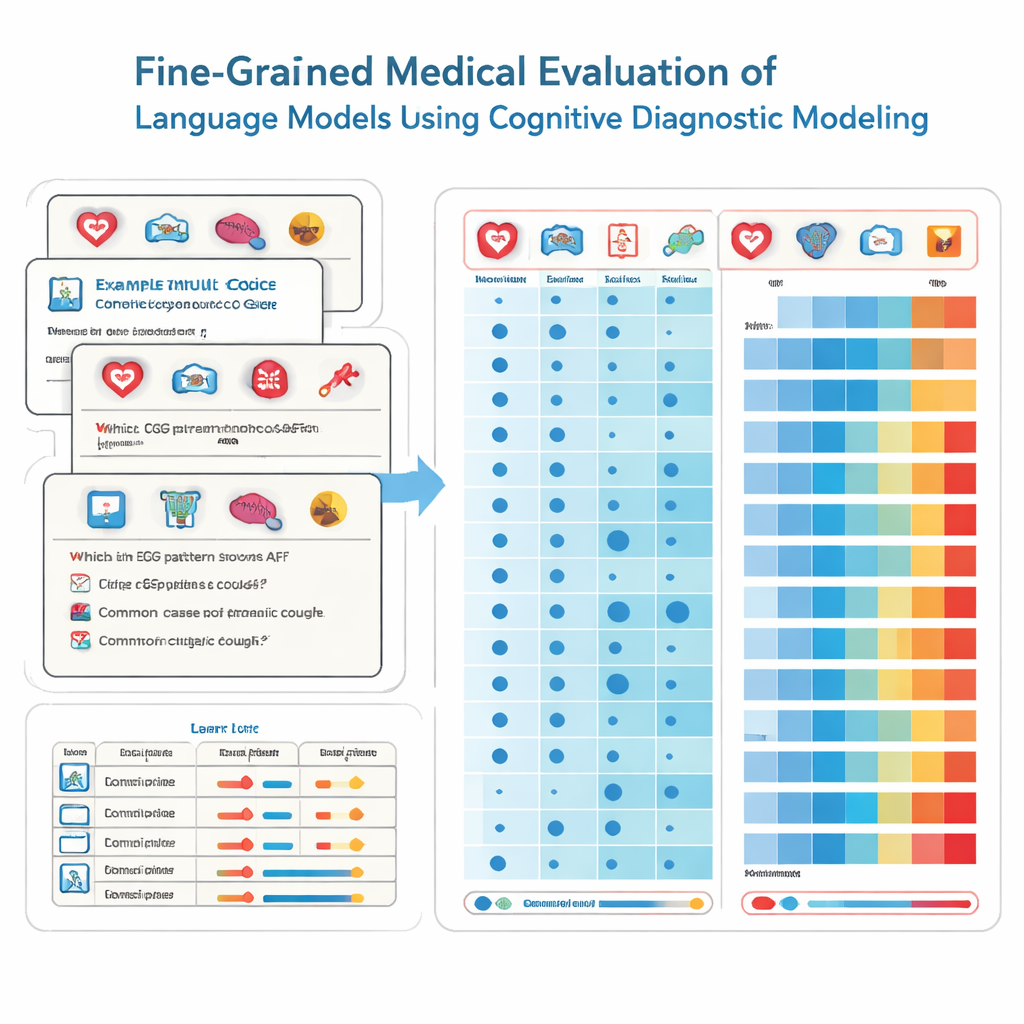
これを実現するために、研究者たちは認知診断評価と呼ばれる教育心理学の手法を取り入れます。各試験問題が同じ漠然とした能力を測るものとして扱うのではなく、この方法では医学知識を循環器学、放射線学、救急医療のような具体的な構成要素に分解します。各選択式問題には必要とされるスキルの正確な組み合わせがタグ付けされます。非パラメトリックな統計手法を用いて、チームはモデルが何千問もの問題に対して示す応答パターンを理想的な反応パターンと比較します。そこから、詳細な成績表が学校の教科ごとの長所と短所を示すように、モデルが各基礎的スキルを「習得」しているかどうかを推定します。
41のAIモデルを医学試験にかける
チームは商用システムとオープンソースモデルを含む41の広く使われる言語モデルを、精査された2,809問の質問でテストしました。これらの問題は中国の国家医療試験バンクから抽出され、22の医学サブドメインにまたがり、医師免許試験を受ける学生を想定して設計されています。各問題は正解が一つで、どの専門分野に関係するかを専門家がラベル付けしています。診断手法を用いて、研究者たちはモデルごとにこれら22の医学的属性のうち何を実質的に習得しているかを、単に何問正解したかではなく推定しました。
幅広い一般知識、しかし鋭い盲点も
結果は印象的であると同時に憂慮すべきものです。最も成績の良いモデル、例えば幾つかの主要な商用システムは大部分の問題で正答し、22分野のうち20分野で習得を示しました。すべてのモデルを通して、多くの一般的な専門分野では優れた性能を示し、循環器学、皮膚科、内分泌学を含む15分野で完全な習得が見られました。しかし、微粒度の分析は他の分野における顕著なギャップを浮かび上がらせました。放射線学は習得率がはるかに低く、ECG・高血圧・脂質と肝疾患という二つのサブドメインはどのモデルも習得していませんでした。重要な点として、より小規模なモデルの中には大規模モデルと同じ習得スキルを持つものもあり、単にモデルが大きいからといって広範で信頼できる医療知識を保証するわけではないことが示されました。
目的に合った道具を選ぶ
これらの詳細なプロファイルは重要です。というのも、総合点が非常に似ているモデル同士でも、強みと弱みのパターンは大きく異なり得るからです。あるシステムは神経学に強く薬理学に弱いかもしれないが、別のシステムはその逆かもしれません。病院の責任者にとっては、見出しとなる試験スコアやパラメータ数だけでAIアシスタントを安全に選ぶことはできません。代わりに、本研究のような診断結果を用いて、各モデルを特定の臨床業務に合わせ、モデルが弱い高リスク領域では人間の専門家がAIの出力を二重チェックするワークフローを設計する必要があります。
患者と臨床医にとって何を意味するか
平易に言えば、本研究は医療試験での高い「成績」がAIシステムが医療のすべての分野で安全に使えることを保証するわけではないと結論付けます。新しいアプローチは、AI自身に対する詳細な健康診断のように働き、どの「臓器」――ここでは医療専門領域――が健全でどこが注意を要するかを明らかにします。心電図解釈や肝疾患のような重要領域における隠れたギャップをあぶり出すことで、この手法は病院、規制当局、開発者に実用的なロードマップを提供します。すなわち、モデルは強みが証明された領域でのみ使い、弱点が残る領域では人間を確実に介在させ、将来の学習は最もリスクの高い盲点に焦点を当てるべきだということです。著者らは、この種の微粒度評価が有益であるだけでなく、患者ケアにAIを信頼する前に不可欠であると主張します。
引用: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
キーワード: 医療AI, 大規模言語モデル, 臨床安全性, モデル評価, 診断テスト