Clear Sky Science · ja
注意機構を備えたハイブリッドResNet50–ビジョントランスフォーマーモデルによる空中画像分類
上空のより賢い「目」が重要な理由
ドローンや衛星からの空中写真は、災害対応、都市計画、農業、さらには交通管理にまで利用されています。しかし、上空からの複雑で雑然とした景観をコンピュータに理解させるのは依然として難しい課題です。本研究は、異なる「見方」を組み合わせてドローン写真中の建物、車、樹木、道路など10種類の物体を従来より高い精度で識別する、2つの新しい人工知能モデルを示します。このアプローチは、空中からの自動監視をより高速に、信頼性高く、実運用へ展開しやすくする可能性があります。
上空から世界を見下ろすことの課題
空中画像は、私たちがスマートフォンで撮る日常的な写真とは異なります。対象は小さく見え、奇妙な角度で写ることがあり、互いに密集していることが多い。木の影に半分隠れた車、狭い歩道、土砂崩れ後のがれきの山は、人間でも素早く見つけるのが難しい場合があります。それでも、政府や救援チーム、環境機関は洪水、山火事、都市の拡大、インフラ被害の追跡にドローンや衛星の画像をますます頼っています。多数の衛星が軌道上にあり、空中撮影市場が急成長するなか、データ量は人手で点検するには増えすぎており、より高精度で効率的な自動分類の必要性が高まっています。
機械の「見る」方法を二つ融合する
今日の多くの成功した画像認識システムは深層学習に依拠しています。一つの系統である畳み込みニューラルネットワーク(CNN)は、エッジ、テクスチャ、小さな形状といった局所的なパターンの抽出に優れます。もう一つの新しい系統であるビジョントランスフォーマーは、画像をパッチの列として扱い、道路と屋根群、近くの開けた地面の関係などシーン内の長距離の関係性を捉えるのが得意です。本研究では、よく知られた畳み込みモデルResNet-50とビジョントランスフォーマーを組み合わせます。それぞれが同じ空中画像を処理して独自の数値特徴を抽出し、ネットワークが学習したシーンの要約を生成します。これら二つの情報流は結合され、「注意」モジュールに渡され、どの特徴が10クラスの判定に最も重要かを学習します。
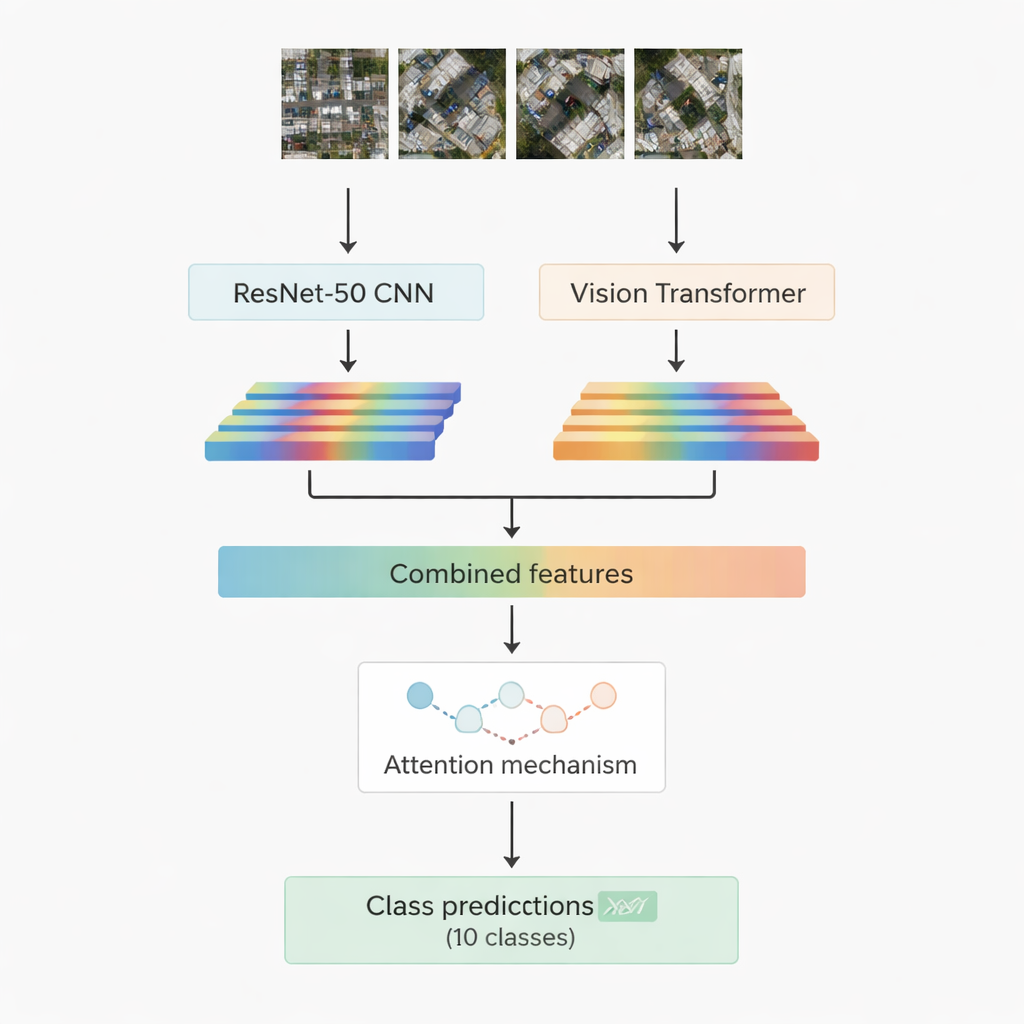
重要箇所に焦点を当てる二つの注意戦略
研究者らはハイブリッドシステムの2つのバージョンを設計して検証しています。第一のバージョンでは、ResNet-50とトランスフォーマーからの特徴を単純に結合し、マルチヘッド注意モジュールに与えます。この仕組みは、それぞれ異なる角度から特徴を観察する多数の小さなスポットライトがあり、それらの結果を結合するように考えられます。第二のバージョンではクロスアテンションを用います:畳み込みネットワークからの特徴がクエリとして機能し、トランスフォーマーの特徴にどこを注目すべきかを尋ねることで、一方の流れが他方を導きます。いずれの場合も、注意の出力は標準的な層を通じて最終的に10クラス(建物、車、がれき、歩道、金属製道路、開けた地、影、タンク、樹木、屋根)のいずれかに割り当てられます。
実際のドローン画像での評価
モデルの有効性を評価するために、著者らはインド・シッキム州でドローンが地上60〜120メートルの高度から収集した公開データセットを使用します。データは河川、森林、丘陵、開発地域を含み、小さなパッチに分割されて各画像が10カテゴリのいずれかに分類されています。データセットはクラスごとに訓練用とテスト用の枚数が均等で、公平な検証基盤を提供します。研究者は両ハイブリッドモデルを同一条件で学習させ、精度、適合率、再現率、F1スコア、混同行列、ROC曲線といった広く使われる指標で性能を比較します。さらに、既存のよく知られたネットワークや近年のトランスフォーマー系手法と結果をベンチマークしています。

より鋭い分類と実世界での可能性
両ハイブリッドモデルはこのデータセット上で従来の手法を上回り、全体精度はそれぞれ95.52%と95.80%に達し、マルチヘッド注意版がやや優位でした。10の物体種類すべてにわたって性能は高く安定しており、詳細な解析でも弱いクラスであっても高い認識率を維持していることが示されています。これは、畳み込みネットワーク、ビジョントランスフォーマー、注意機構を組み合わせることが複雑な空中シーンを理解する上で有効な手法であることを示唆します。一般読者にとっての結論は、コンピュータは「道路はどこか?」や「どの領域ががれきや建物か?」といった問いに対して大量のドローン画像からより正確に答えられるようになってきている、ということです。こうしたモデルが改良され他のデータセットへ拡張されれば、災害対応、環境モニタリング、スマートシティ向けの迅速で信頼できる上空画像解析を支える基盤となる可能性があります。
引用: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
キーワード: 空中画像分類, ドローン画像, 深層学習, ビジョントランスフォーマー, リモートセンシング