Clear Sky Science · ja
BERTモデルと最短経路アルゴリズムに基づく短文エンティティ曖昧性解消手法
紛らわしい名前を整理する意義
私たちは日々、ツイートや検索クエリ、チャットといった短く雑多な断片のテキストを検索・閲覧・やり取りしています。これらには人名、地名、企業名、物の名前などが含まれ、例えば「Apple」が果物を指すのか企業を指すのかのように複数の意味を持つ場合があります。コンピュータは我々の意図する意味を推測しなければならず、誤推定が起きると検索結果や推奨、オンラインサービスの有用性は大きく損なわれます。本稿は、現代の言語モデルと巧妙なグラフアルゴリズムを組み合わせることで、特に中国語のソーシャルメディアや検索における短文の曖昧な名前を正しく解釈するための新しい手法を提示します。
雑多な短文から明確な対象へ
短文はコンピュータにとって意外に手強いものです。長文とは異なり文脈が非常に少なく、スラングや略語、不完全な文が詰まっています。従来手法はテキスト内の名前を知識ベースの項目に照合したり、手作りのルールや単純な機械学習モデルを用いたりしてきました。こうしたアプローチはしばしば各語を固定的な単一の意味として扱うため、同じ語が職名、会社名、曲名など文脈に応じて異なる意味を持つ場合に大きく失敗します。その結果、ツイートやクエリ内の語が実世界のどの実体を指すかについての混乱が頻発します。
曖昧な名前を見抜く仕組みを教える
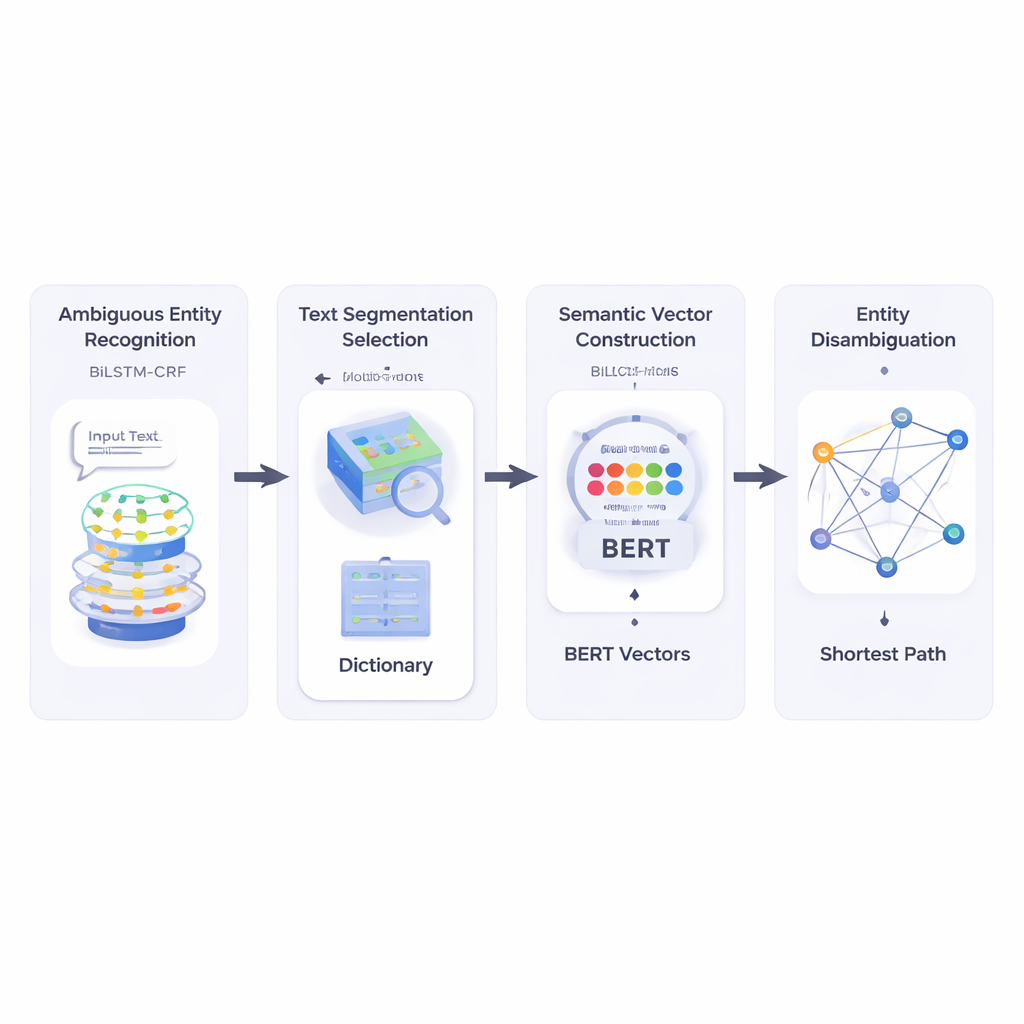
著者らはまず、短文を読み取りどの部分がエンティティ名で、どれが曖昧になり得るかを識別するシステムを構築します。BiLSTM‑CRFという双方向の文脈を参照して系列ラベル付けに強いニューラルネットワークの組み合わせを用いてエンティティをタグ付けします。潜在的なエンティティがマークされたら、HowNetという大規模な語彙資源を参照します。HowNetがある語について複数の意味を挙げていればその語は曖昧とフラグされ、意味が一つだけであれば既に明確と扱われます。この段階により、真に曖昧性解消を要する名前の絞り込みが行われます。
意味を空間の点に変換する
次に手法は短文を候補となる語分割に分割し、文中の明確に理解できる参照語との意味的整合性を確かめることで最適な分割を選びます。この測定には、文脈依存の意味を数値ベクトルとして出力する強力な事前学習済み言語モデルBERTを利用します。各語用法に対して得られる「意味ベクトル」間のコサイン類似度を計算することで、参照語と意味的に最も適合する分割を見つけます。これにより各語の可能な意味を多次元空間上の点として表現できます。
正しい意味への最短経路を探す
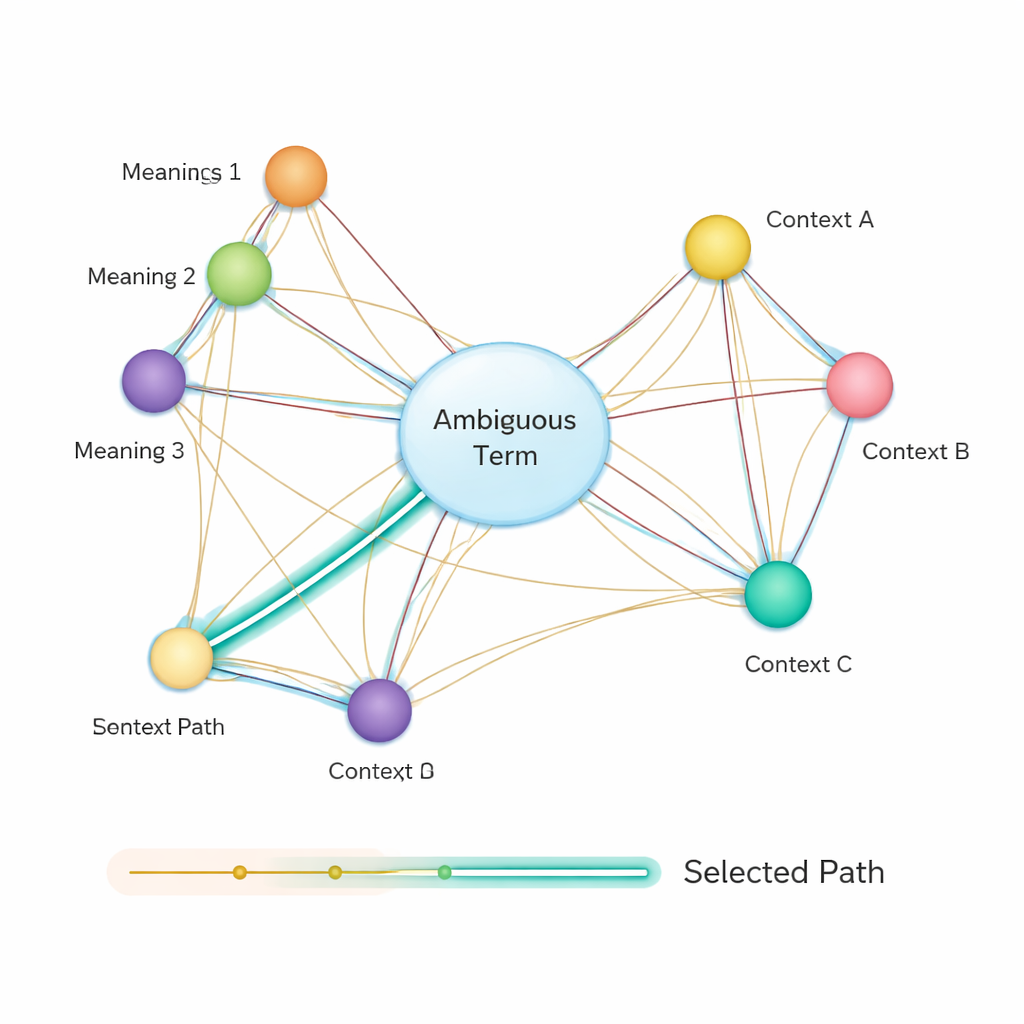
その後、手法は意味ネットワークを構築します。ここでは各語の各意味がノードとなり、同一文で共起し得る意味同士がエッジで結ばれます。各エッジの強さは、やはりBERTに基づくベクトルを用いて意味の類似度により決定されます。曖昧語のどの意味が文に最も適合するかを決めるために、著者らは古典的なダイクストラの最短経路アルゴリズムを適用します。直感的には、システムはこの意味グラフを通る全体の意味的「距離」を最小にする経路を探します。選ばれた経路は用語群の一貫した解釈を表し、その経路上にある曖昧エンティティの意味が最終的な答えとして採択されます。
どれほど改善するか
研究者らは本手法をCLUEベンチマークの公開中国語データセットで評価しました。このデータセットはソーシャルメディア投稿や検索クエリのような実際の短文シナリオを模擬しています。彼らは従来のWord2Vec埋め込みを用いる手法、ELMo言語モデル、最短経路ステップを含まないBERTベースのシステム、そしてBiLSTM‑CRF‑BERT‑SPAの完全パイプラインの4手法を比較しました。数千件のテキストにわたり、完全な手法は他手法と比べて平均して精度、再現率、F1スコアをおおむね4分の1ほど向上させました。実務的には、本システムは正しいエンティティを見つける能力と、多様なデータ量にわたって一貫してそれを行う能力の両方で優れていました。
日常技術への意味
専門外の人にとっての要点は明快です。強力な言語理解モデル(BERT)とグラフベースの最短経路探索を組み合わせることで、短く雑然としたテキストにおいて曖昧な名前が何を指すかをコンピュータがより確実に判断できるようになる、ということです。これにより検索エンジンの精度向上、SNS投稿の理解向上、推薦システムや知識グラフなど下流ツールの品質向上が期待できます。本手法は現時点で中国語向けに設計されており効率面の改良余地は残りますが、最新のAIと古典的アルゴリズムの融合が、機械による日常言語解釈の混乱を大きく低減できることを示しています。
引用: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
キーワード: エンティティ曖昧性解消, 短文, BERT, 知識グラフ, 自然言語処理