Clear Sky Science · ja
マルチアームドバンディット手法を用いたコンピュータ適応試験のための強化学習フレームワーク
デジタル教室のためのより賢いテスト
長くて一律の試験を受けたことがある人なら、その退屈さや不公平さを感じたことがあるでしょう。ある問題は簡単すぎ、別の問題は極めて難しく、最終的な得点が本当にあなたの理解を反映しているとは限りません。本論文は、各受験者の解答に応じてリアルタイムに適応する新しいコンピュータベースの試験構築法を示します。現代の人工知能の考え方を取り入れることで、試験を短く、より正確に、受験者一人ひとりの真の能力に合ったものにすることを目指しています。
固定試験が不足する理由
従来の試験はすべての受験者に同じ問題セットを与えます。これにより試験作成は単純になりますが、多くの情報を無駄にします:優秀な受験者は多くの易しい問題をこなさねばならず、一方でつまずいている受験者はすぐに圧倒されます。コンピュータ適応試験は前の解答に基づいて次の問題を選ぶことでこれを改善しようとしますが、現在の多くのシステムは数十年前の統計モデルや手作りの規則に依存しています。これらの古い手法は複雑な解答パターンを捉えるのが苦手で、現代の大規模なオンライン環境における学習者間の広い差を十分に説明できないことがしばしばあります。
テストに現代的なAIを導入する
著者らは、適応試験を開始から終了まで案内するためにディープラーニングと強化学習を組み合わせた新しいフレームワークを提案します。システムは繰り返しのサイクルで動作します。まず、一次元畳み込みニューラルネットワーク(1D‑CNN)が受験者の最近の解答、問題の難易度、その他の要約統計を解析します。このデータ列からネットワークは正規化された尺度で受験者の現在の技能を表す単一の数値を出力します。これは従来の能力理論が表す能力像によく似ていますが、データから直接学習されます。このネットワークは、難しい問題で一貫して成功しているパターンや簡単な問題での予期せぬミスなど、微妙なパターンを認識するよう訓練されます。 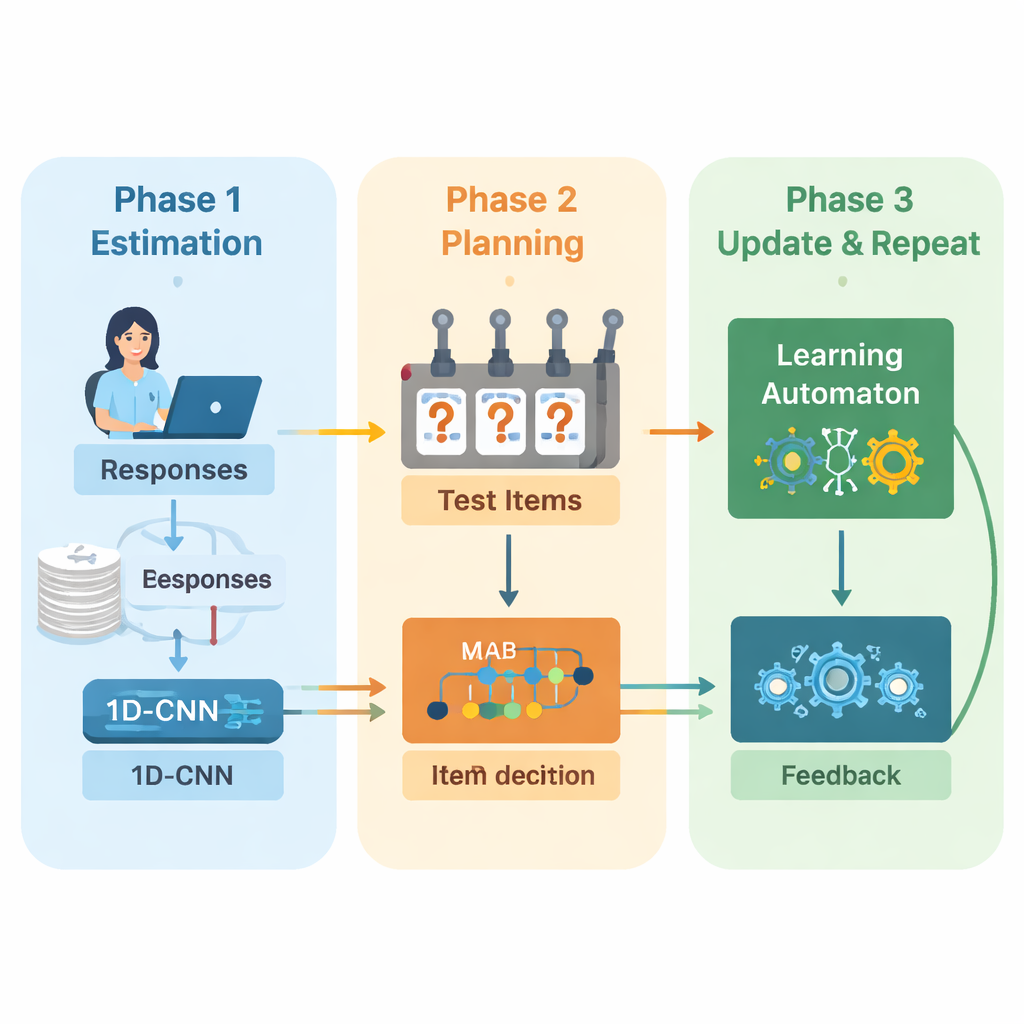
次に出すべき問題を選ぶ
システムが更新された能力推定を持つと、次に何を出題するかを決めなければなりません。ここで著者らは「マルチアームドバンディット」戦略を用いています。これは意思決定理論の古典的手法で、各行動をスロットマシンのレバー(腕)を引くことになぞらえます。本文脈では、アイテムバンク内の各問題が一つの腕です。アルゴリズムは現在の技能推定に概ね合致する難易度の問題を検討し、最も情報量が多いと期待されるものを選びます。ここでは二つの目的をバランスさせます:解答が簡単すぎたり難しすぎたりしないように難易度のマッチングを良くすること、そして重要なトピックを見落とさないようにできるだけ多様な内容分野をカバーすることです。これら二つの目的を混合した報酬スコアが選択過程を導きます。
自らの判断から学ぶ
試験が進むにつれて改善を続けるために、システムは学習オートマトンと呼ばれる別の学習要素を追加します。このモジュールは推定能力がラウンド間でどのように変化するか、受験者の正答率が改善しているか低下しているかを監視します。そして、能力が上がる、変わらない、下がるというモデルの期待を要約する小さな確率集合を調整します。これらの確率は次ラウンドでニューラルネットワークへの追加入力として戻されます。こうして試験エンジンは受験者について学ぶだけでなく、自身の過去の判断についても学びます——正確な推定につながった傾向を報酬し、そうでなかった傾向を罰するのです。 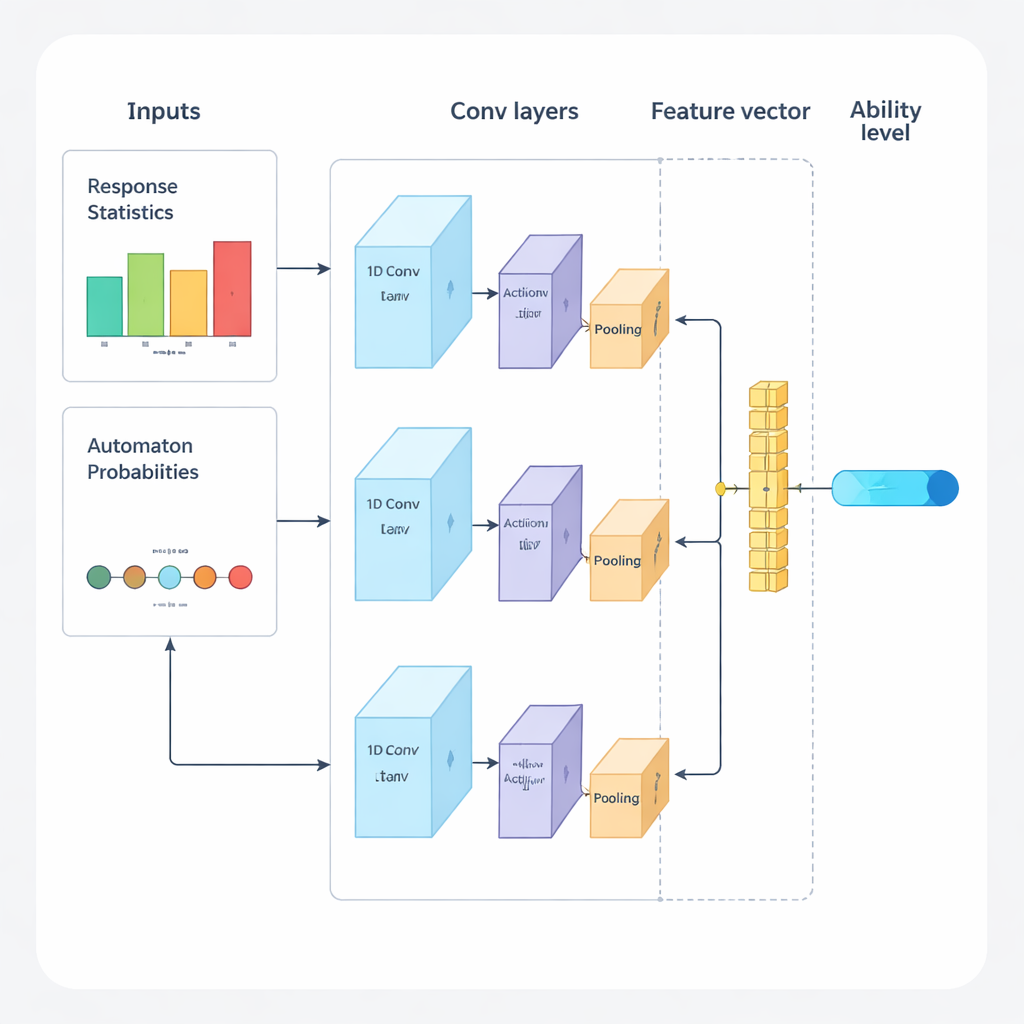
実際の効果はどれほどか
研究者らは大規模で多言語の試験データセットと、真の技能レベルが既知の何千ものシミュレートされた受験者を用いてフレームワークを評価しました。彼らは提案手法を複数の主要な適応試験手法と比較しました。誤差や相関の各種指標にわたって、新しいシステムはより少ない問題数でより正確な能力推定を生成しました。共通の統計量(平方根平均二乗誤差や平均絶対誤差など)で測った誤差は、競合手法より明らかに低かったのです。同時に、アイテムバンク内での問題利用がより均等に分散され、特定の問題が過剰に出題されて流出するリスクが減少しました。
将来の試験にとっての意味
日常的な言い方をすれば、この研究は将来のコンピュータベースの試験が硬直した試験というよりも個別指導のように感じられる可能性を示唆します。問題はすばやく各人に適した難易度に絞られ、重要なトピックの全域を探り、システムがそのレベルに確信を持てれば終了します—多くの場合、今日の試験よりも少ない問題数で済みます。方法は依然として良好な訓練データと計算資源に依存しており、これまでに単一のデータセットで試されたに過ぎませんが、個々の学習者に自然に適応する、より賢く公平で効率的な評価の新世代を示すものです。
引用: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
キーワード: コンピュータ適応試験, 教育評価, ディープラーニング, 強化学習, マルチアームドバンディット