Clear Sky Science · ja
大規模言語モデルを用いた中国語およびロシア語の外交談話における含示認知
行間を読む
外交官が公の場で語るとき、言葉にされない部分は選ばれた言葉と同じくらい重要になり得ます。本研究は、現代の人工知能が中国とロシアの外務省記者会見に含まれる微妙な示唆や婉曲なメッセージを検出できるかを検証します。これらの信号は人間の聴衆が見落としがちですが、国際関係に影響を与えることがあります。
世界情勢で示唆が重要な理由
外交的言語は慎重で礼儀正しく設計されています。各政府は利害を守りつつ、対立をあからさまに煽ったり国民を不安にさせたりしない必要があります。その結果、担当者は表面上は中立に聞こえるがひそかに批判、警告、あるいは政治的立場を示すフレーズ――いわゆるヒント――に依存することが多いです。こうしたヒントを誤解することは過去に危機や不信の原因になってきました。共通の背景知識を当然視できない異なる言語や文化の間では、これらの間接的なメッセージを理解することは特に難しくなります。
古典理論からスマートマシンへ
数十年にわたり、言語学者や哲学者は話者が文字通り述べる以上のことをどのように含示するかを研究してきました。初期の理論は主に話者の意図に焦点を当て、合理的な聞き手が隠された意味を再構築できると仮定しました。のちの「認知語用論」の研究は、ヒントの理解が聞き手の心的過程、文化的背景、周囲の文脈にも依存することを強調しました。これらの考えを踏まえ、著者らはヒントを多層的に定義します:表面の言い回し(語彙・意味レベル)、それを形作る文化的思考様式(言語的・認知的レベル)、そして批判や警告、体面保持などの話者の動機や戦略(動機的・語用論的レベル)です。
AIシステムの構築方法
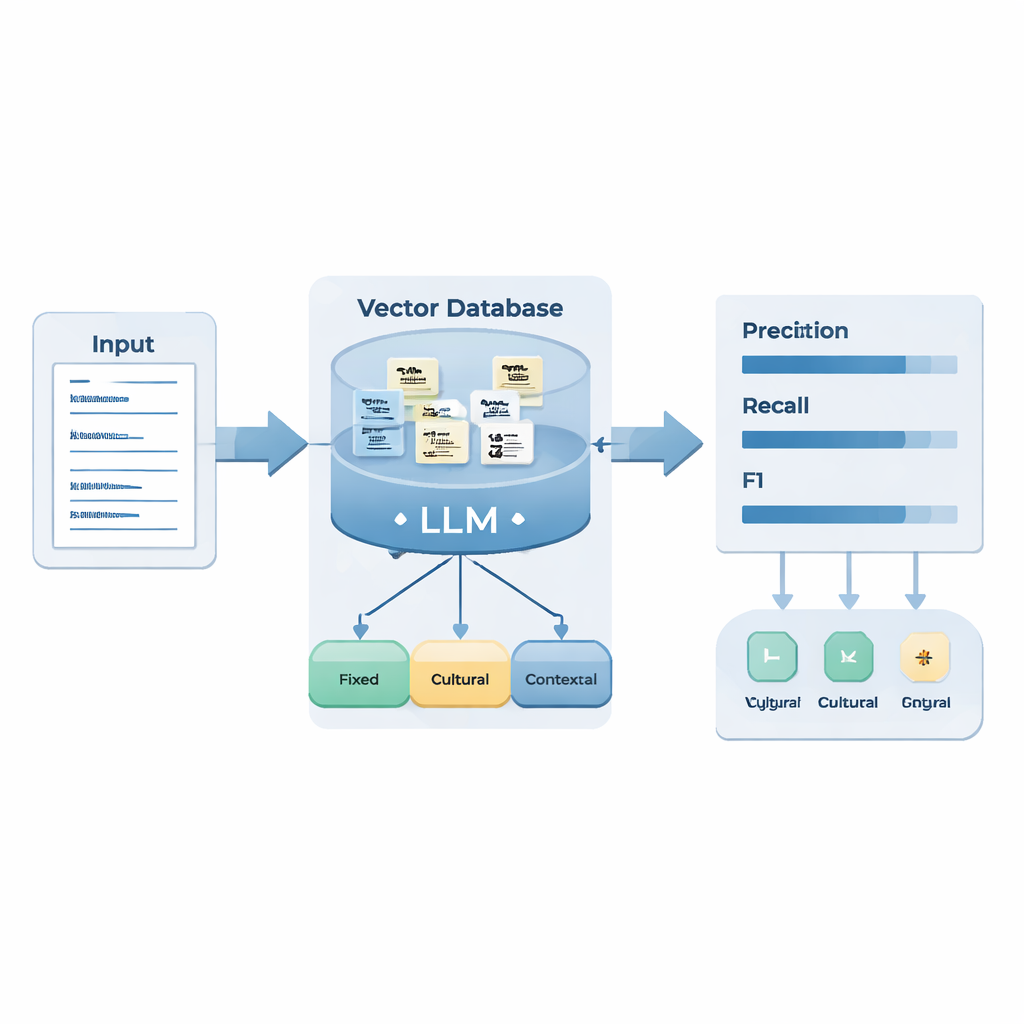
研究者らは、2024年に行われた中国およびロシア外務省の公式記者会見から約1,400件の質疑応答セグメントを収集しました。専門の言語学者が手作業で498件の「平明に述べられていない」発言を注釈しました。これらは三種類に分類されました:「定型的ヒント」――安定して反復される表現(典型的な外交定型句など)、「文化的ヒント」――共有された文化知識や比喩に依存するもの、そして「文脈的ヒント」――直近の状況や動機を精査することでのみ認識可能なもの。これらの例は外部知識ベースの構築と、大規模言語モデルのための推論ルール設計に用いられました。
モデルに段階的思考を教える
チームは二つのAI手法を組み合わせました。Retrieval-Augmented Generation(RAG)は、モデルが新しい記者会見の回答を処理するときにカスタムのヒントデータベースから関連例を引き出すことを可能にします。Chain-of-Thought(CoT)プロンプティングはモデルに段階的に推論させます:言語を識別し、回答を文に分割し、既知のヒントパターンを照合し、特定の動機(批判や警告など)を認識された戦略(事実の提示、対比、皮肉など)を通じて表現しているかを判断し、最後にそれを定型、文化、文脈のいずれか、あるいは「ヒントなし」とラベリングします。システムはまた、含示された意味が文字どおりの表現と本当に異なるかどうかを自己検査する処理も行います。
どれほどうまく働いたか?
システムの評価には、著者らが2025年の新しい記者会見データ(両言語)を用いました。全体として、強化されたモデルは隠れたメッセージの検出に信頼できる成果を示しました:真のヒントの多くを捉える(高いリコール)とともに、検出と誤検出のバランスも良好で(ロシア語F1=0.83、 中国語F1=0.76)、特に両言語における定型的ヒントに強みを示しました。これは、安定したパターンは機械が学習しやすいという考えを支持します。一方で、中国語の文化的・文脈的ヒントの検出はロシア語よりも困難でした。著者らはこの差を様式の違いに結びつけています:ロシアの外交的発話は批判や警告を明確に示す生き生きとした比喩や鋭い対比を用いることが多いのに対し、中国の談話は中立的な定型句、成句、文脈依存の礼節に依拠することが多く、文字どおりの表現と区別しにくいのです。
誤りが示すもの—改良の方向性
誤りを詳しく検討すると、三つの繰り返し現れる問題が見つかりました。時にモデルは文を「読みすぎ」て、存在しない隠れた意味をでっち上げることがあります。時にヒントを検出しても誤ったタイプを割り当て、定型と文脈の境界を曖昧にすることがあります。そして時に単純な表現を、敏感な語や馴染みあるパターンの存在からヒントと扱ってしまうことがあります。これらの弱点に対して、論文は多数の明確な「ヒントなし」外交フレーズを負例として追加すること、推論をより質問と周囲の文脈に厳密に紐づけること、文を書き換えて知識ベースと複数回照合すること、そして事前フィルタと自己評価ステップを挿入して「これは既に明示的か、それとも本当に含示か?」と問い直すことを提案しています。
一般向けに重要な理由
専門外の読者にとっての要点は、大規模言語モデルが既に大量の公式声明を精査し、政府が行間で語っている可能性のある箇所をフラグ化するのに役立つということです。一方で、本研究は外交が文化、歴史、様式に深く依存することを強調しており、これらの要素は高度なAIにとってもなお難題であることを示しています。言語理論と現代のAIツールを融合させることで、世界政治の微妙な信号を追跡するより信頼できるシステムへの道が示される一方で、何が言外に残されているかを解釈するには人間の判断と異文化理解が依然として不可欠であることも明らかにしています。
引用: Guo, Y., Wang, X. Hint recognition in Chinese and Russian diplomatic discourse using large language models. Sci Rep 16, 5751 (2026). https://doi.org/10.1038/s41598-026-36338-z
キーワード: 外交言語, 暗示的意味, 大規模言語モデル, クロスリンガル分析, 検索強化生成