Clear Sky Science · ja
ゼロショット標的認識のための物体誘導型対照言語–画像事前学習
混雑する空と海に向けたより賢い眼
現代の警備や災害対応システムは、空や海のカメラに依存して航空機や船舶、その他重要な物体を検出しています。しかし、シーンが乱雑でデータが乏しく、機体の新しい型が次々と登場する状況では、戦闘機と旅客機、戦艦と貨物船をコンピュータに見分けさせるのは意外に難しいものです。本論文はOG‑CLIPという新しいAIシステムを紹介します。これは大規模な事前知識を取り入れ、重要な物体に視覚的に鋭く焦点を当てることで、明示的に学習していない軍用・民間の標的を認識できるように設計されています。
従来のAIが的を外す理由
多くの画像認識システムは、ラベル付き画像の大規模コレクションから学習します。各画像は「猫」や「車」といった固定カテゴリに紐づけられます。しかし、防衛やリモートセンシングのような専門分野では、この手法は通用しません。データが機密でラベリングに専門家が必要であり、機器の種類が膨大だからです。CLIPのような最近の視覚–言語モデルは、ウェブから集めた短いキャプションと画像を組にすることで、言葉で説明された新しい概念を認識できるようになりました。それでも軍事画像では苦戦します:キャプションはしばしば曖昧で、雲や波といった背景がピクセルを支配し、内部表現は小型ドローンから高性能サーバまで効率的に動くほど柔軟ではありません。OG‑CLIPはこれら三つの問題に正面から取り組みます。
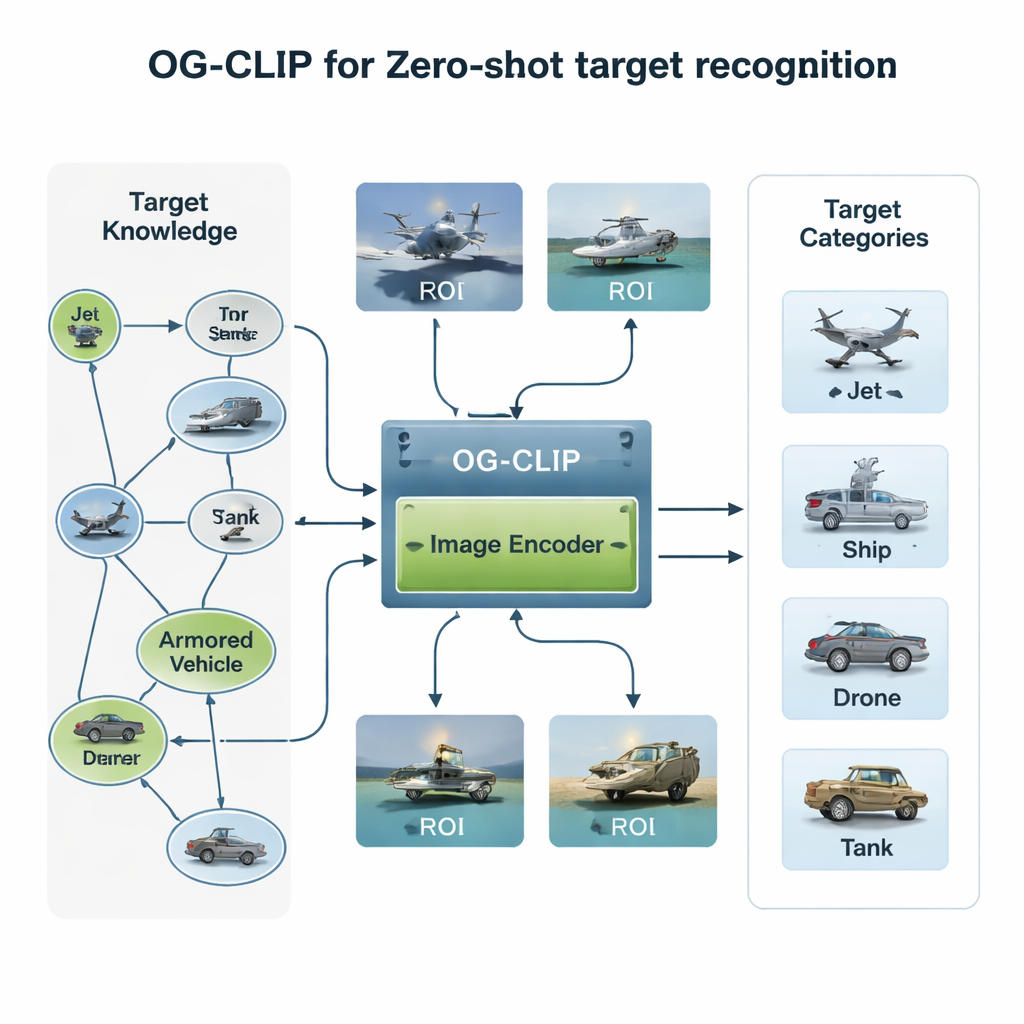
知識に富んだ訓練世界の構築
OG‑CLIPの第一の要素は、慎重に設計された訓練用のユニバースです。著者らは戦闘機や爆撃機から軍艦や民間機に至るまで、5,000種類の標的を収集し、詳細なナレッジグラフに整理しました。各エントリには射程、重量、武装構成などの構造化された事実が含まれ、公的な防衛資料、百科事典、技術文書から引き出されています。次に、公的データセット、ウェブ検索、既存の社内アーカイブ、ゲームエンジンによるシミュレーションシーンなどを使って約100万枚の画像を集めました。データの信頼性を保つため、既存モデルによるクラスタリングで外れを検出し、専門家のレビューで追跡し、誤ったラベルを除外しました。最後に、ナレッジグラフを先進的な言語–視覚ツールで各画像の豊かな自然言語記述に変換し、システムが「これはジェット機だ」だけでなく「ウィングレットが上方に曲がった単通路機」や「飛行翼形状のステルス爆撃機」のような具体的特徴まで学べるようにしています。
雑音を無視するようモデルを教える
第二の革新は、モデルがどこを見るかにあります。多くの衛星や空中写真では、実際の船や航空機は小さな領域しか占めず、周囲は空や海、地形の雑然とした背景に囲まれています。OG‑CLIPは、全フレームを見るのではなく人間が要となる物体に目を向けるような、領域注目(ROI)モジュールを追加します。最先端のセグメンテーションツールが画像内の候補物体を自動的に輪郭化し、ターゲットを強調して背景を弱めるソフトマスクを生成します。これらのマスクは元の画像とともにモデルの視覚バックボーンに入力され、注意が自然に翼形状、甲板配置、船体シルエットなどの識別的特徴に集中するようになります。このプラグイン設計はコアアーキテクチャを書き換えることなく既存システムに追加でき、より「物体誘導型」の視点を与えます。

ハードウェアに合わせて詳細度を適応させる
三つ目は実用的かつ重要な懸念に対処します:すべての機器が同じレベルの詳細を扱えるわけではありません。地上ステーションは高次元の特徴を処理できる一方で、小型ドローンはより高速で軽量な計算が必要です。従来の方法は一つの特徴サイズに固定するか、異なるサイズごとに複数のモデルを訓練していました。OG‑CLIPは代わりに“マトリョーシカ”方式の表現を用い、情報を入れ子人形のように複数の詳細レベルで一つのベクトルに詰め込みます。システムはこのベクトルの短いまたは長い部分を切り出して、再訓練なしで粗いあるいは詳細な記述を得ることができます。重み付け機構により各レベルが分類に最も有用な情報を保持するよう促し、追加の損失項がレベル間の意味的一貫性を保つように調整します。
実際にはどのくらい有効か?
OG‑CLIPを評価するため、研究者らは99の標的カテゴリからなる挑戦的な評価セットを構築しました。そこには51種類の軍用機、29種類の軍艦、19種類の民間または混合標的が含まれます。重要なのは、これらのカテゴリのいずれも訓練データに現れておらず、システムは言語と視覚パターンの学習に頼らざるを得ないという点です(いわゆるゼロショット試験)。複数の強力なCLIPベースのベースラインと比較して、OG‑CLIPは平均精度を11ポイント以上改善し、全体で84.28パーセントに達しました。特に混雑した複雑なシーンや、異なる戦闘機モデルなど類似するモデル間の微妙な差の識別で優れた性能を示し、これはROIモジュールと知識に富んだ記述が明確な利点を与えたためです。アブレーションスタディでは、ナレッジグラフデータ、ROIフォーカス、適応的表現の各構成要素がそれぞれ測定可能な寄与をしていることが示されました。
実世界の監視にとっての意味
専門外の読者にとっての重要な要点は、OG‑CLIPがラベル付き例が乏しい状況下でも、実世界の画像から慣れない航空機や船舶をより確実に認識できる監視・モニタリングシステムに向けた一歩であるということです。構造化された専門家知識、自動的に対象物に集中する仕組み、そして調整可能な詳細レベルを組み合わせることで、このアプローチは視覚–言語AIをより賢く、より実用的にします。防衛分野を超えて、同様の考え方は環境監視、災害対応、産業検査システムが多様なハードウェア上で複雑なシーンを理解するのに役立つ可能性があります。
引用: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
キーワード: ゼロショット認識, 視覚–言語モデル, 物体検出, リモートセンシング, ナレッジグラフ