Clear Sky Science · ja
アラビア語NLPの堅牢性評価のための敵対的手法としての方言置換
日常のアラビア語が高度なコンピュータを混乱させる理由
多くのアプリが現在、アラビア語のテキストを読み取って感情を判定したり、ニュースを分類したり、質問に答えたりしています。しかしこれらのシステムの多くは主に標準アラビア語(MSA)から学習しており、実際の人々は日常的に地域の方言を混ぜて話します。本稿は、文章のたった一語をエジプト方言や湾岸方言に置き換えるだけで最先端の言語モデルをだますことができることを示し、カスタマーサービス、メディア監視、オンライン安全にアラビア語AIを利用する人々に懸念を投げかけます。
一つの言語、さまざまな声
アラビア語は単一の均一な話し方ではありません。MSAは学校やニュース、公式文書で使われますが、日常会話はエジプト語や湾岸アラビア語といった方言に依存します。これらの変種は語彙や語形、場合によっては文構造まで異なります。たとえば「今」のような単純な語でさえ地域ごとに非常に異なる形をとります。人間の読者にとってはこうした変化は自然で理解しやすいものですが、ほぼ完全にMSAで訓練されたコンピュータモデルにとっては方言語は見慣れないものに見え、明快な文が不可解なものに変わることがあります。
方言をAIへの負荷試験に変える
アラビア語の言語モデルがどれほど脆弱かを探るために、著者は単純な二段階のテストを設計します。まず、モデルに繰り返し問いかけて、その文の中で判定に最も影響する単語――強い形容詞、重要な動詞、話題を示す名詞など――を特定します。次に、その単語だけをエジプト語または湾岸アラビア語の同等語に置き換えるため、大規模で注意深く微調整された「方言化モデル」を使います。文の残りはそのまま残し、人間の読者にとって意味は変わりません。こうして変えられた文は現実的な敵対的事例になります:意図したメッセージを変えずにシステムをだますために作られた、ごく小さく自然に見える修正です。
ホテルレビューとニュース記事での試験
研究では四つのよく知られた深層学習モデルを攻撃対象とします:二つの大規模トランスフォーマー(AraBERTとCAMeLBERT)と二つの小規模ネットワーク(畳み込みモデルと双方向LSTM)。これらは二つの主要なMSAデータセットで訓練されています:感情分析用のホテルレビューと話題分類用のニュース記事。各テストセットから著者は1,280件の例を取り出し、方言置換手順を適用します。各文でわずか一語が変わるだけでも、その影響は顕著です。ホテルレビューでは、AraBERTのクリーンテキストでの精度は94パーセントから、湾岸方言置換で約72パーセント、エジプト方言置換で65パーセントに低下します。CAMeLBERTはさらに低下し、おおむね63および55パーセントになります。ニュース分類器も打撃を受けます:畳み込みモデルは約18〜22ポイントの低下を示し、LSTMも同様の減少を示します。
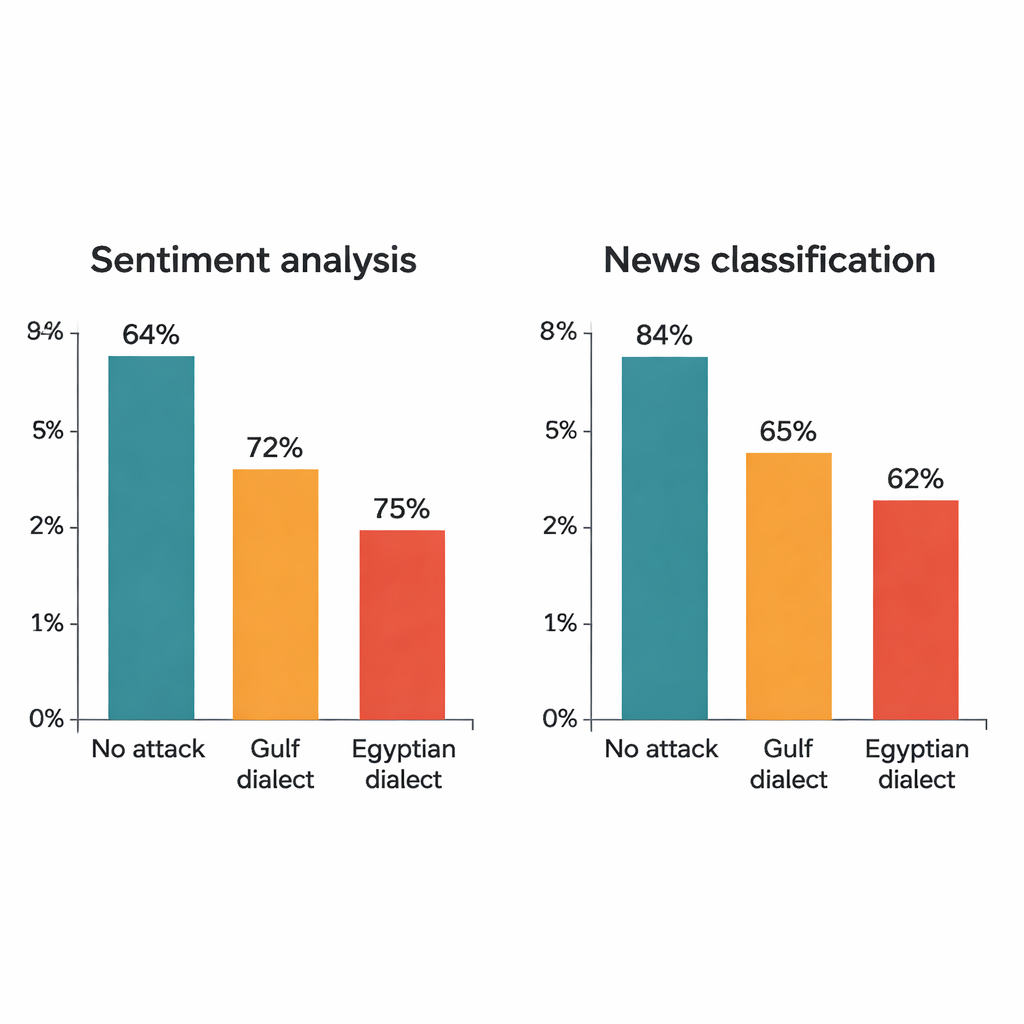
モデル内部で何が起きているか
詳細に見ると、最も脆弱な単語は人間が実際にテキストを読む際に重視する語と一致していることがわかります。ホテルレビューでは、標的にされた単語のほぼ半分が「良い」や「ひどい」のような感情的重みを持つ形容詞です。ニュース記事では、選ばれる語の大半が政治、スポーツ、金融などの話題を示す名詞や固有名詞です。これらのトリガー語が方言形に置き換えられると、MSAのみで訓練されたモデルはしばしばそれらを認識できません。トランスフォーマーモデルは特に脆弱で、サブワード断片への依存やごく少数の高重みトークンへの注意が、一語の方言で予測をひっくり返すのに十分になります。文全体に注意をより均等に配分する小規模モデルもだまされますが、やや堅牢性が高い傾向があります。
エジプト方言と湾岸方言:すべての方言が同じではない
攻撃はまた、エジプトアラビア語が湾岸アラビア語よりもモデルを混乱させやすいことを示します。言語学的研究もこれを支持しており、湾岸変種は語彙や構造面でMSAに比較的近いことが多い一方、エジプトアラビア語は歴史的経緯や他言語との接触によりより独自の形を取り入れてきました。その結果、湾岸方言の置換は元のMSAに十分似ていてモデルが何とか対処できる場合があるのに対し、エジプト方言の置換はモデルがこれまで見たことのない範囲に入りやすくなります。統計検定は、この観察された性能低下がランダムではなく、現行システムがアラビア語の二言語使用(ディグロシア)を扱う際の体系的な盲点を反映していることを確認します。
アラビア語AIにとっての含意
一般利用者にとっての結論はシンプルです:今日のアラビア語AIは、人間にとっては完全に明瞭な普通の方言語によって容易に混乱させられます。ホテルレビューのたった一語の方言表現がモデルの判定を肯定から否定にひっくり返したり、ニュース記事の話題を誤ラベル付けしたりすることがあり得ます。研究者や開発者に向けたメッセージは、MSAと地域方言の両方で学習する「ディグロシア対応」システムを構築し、方言置換のような現実的なストレステストを堅牢性評価に用いることを促すものです。それが行われるまでは、「アラビア語はMSAだけだ」と仮定するアプリケーションは実世界で重大な誤解を招くリスクを抱えています。
引用: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
キーワード: アラビア語NLP, 方言の差異, 敵対的事例, 感情分析, テキスト分類