Clear Sky Science · ja
潜航艇推進システムにおける反回転永久磁石同期モータ最適化のための強化学習駆動モデル予測制御
より賢い駆動、より静かな潜航艇
現代の潜航艇は、海洋の探索や科学的・商業的・防衛的任務を遂行するために、静かで効率的な推進を必要とします。本研究は、二つのプロペラを互いに反対方向に回転させる特殊な電動機に着目し、潜航艇が水中を滑らかかつ静かに移動するのを助けます。研究者らは、高度な予測手法と学習アルゴリズムを組み合わせることで、波や潮流、急な操縦による擾乱があってもこれらのモータを安定かつ効率的に保てることを示しています。
二つのプロペラで安定した潜航
従来の単一プロペラ方式は、高速での航行時に船体のねじれやロールを引き起こし、操縦を難しくしたり探知されやすくしたりします。これを避けるために、同軸で反対方向に回転する二つのプロペラを用いる反回転推進が採用されます。その中心となるのが反回転永久磁石同期モータ(CRPMSM)で、実質的に高トルクの小型モータを二つ積み重ねた構成です。この配置は不要なねじり力を打ち消し、エネルギー効率を高め、騒音を低減します。いずれも潜航時のステルス性や長時間任務に不可欠です。しかし、乱流や急旋回などで二つのロータにかかる負荷が不均衡になると、両側を完全に同期させ続けることは深刻な制御課題になります。 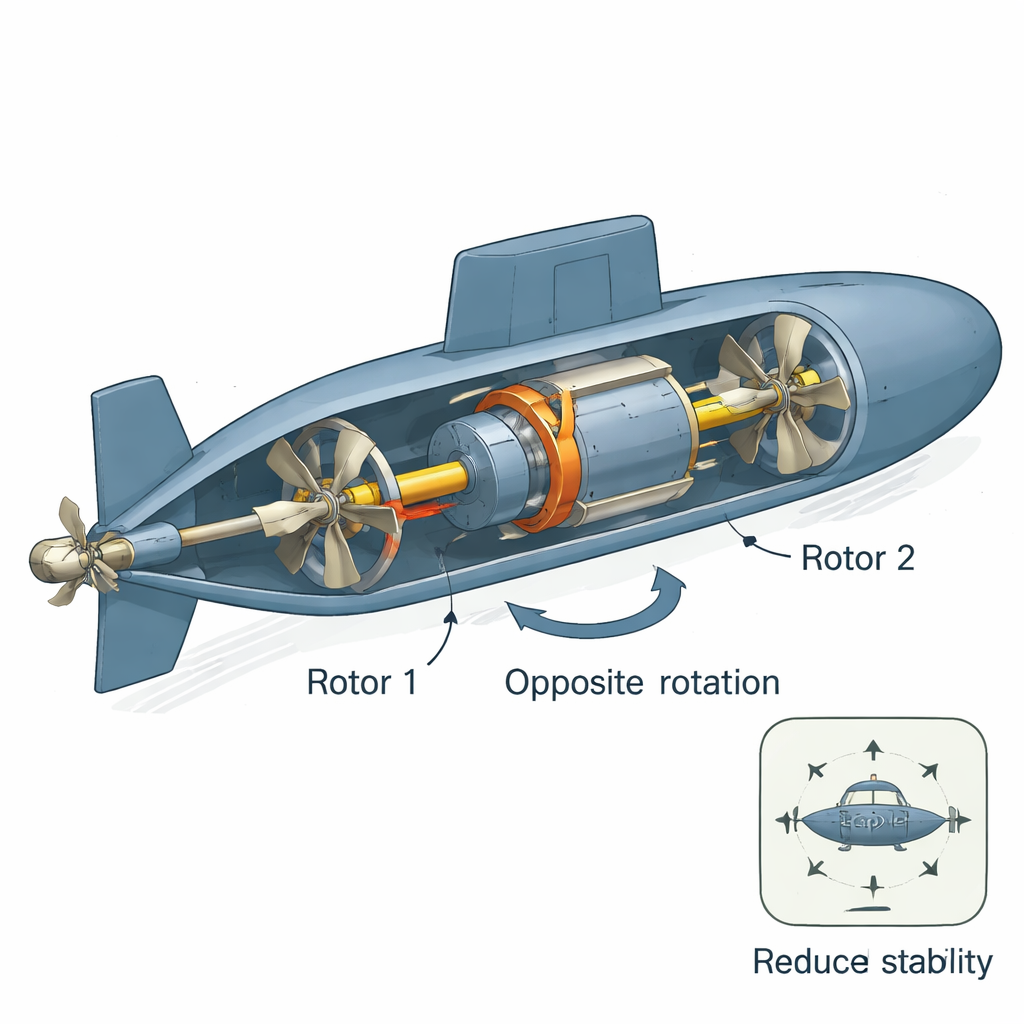
従来制御の限界
研究者らはCRPMSMのロータを同期かつ効率的に保つために多くの制御手法を試みてきました。磁束指向制御や直接トルク制御のような手法は、静的で予測可能な条件下では良好に機能しますが、水中環境が急速に変化したり著しく不均一になったりすると性能が低下します。スライディングモード、ファジー、適応制御などのより高度な手法はロバスト性を高めますが、しばしばモータや周囲の水の非常に精緻な数理モデルに依存します。現実にはこれらのモデルが完全であることはなく、不一致がトルクリプルの増大、擾乱後の回復遅延、エネルギーの浪費につながることがあります。モデル予測制御(MPC)は短期の未来を見越して最適な制御操作を計画するため応答が速いですが、やはり基礎となるモデルの品質に強く依存します。
現場で学ぶハイブリッド制御器
著者らは、両アプローチの利点を組み合わせたハイブリッドな強化学習駆動モデル予測制御(RL-MPC)フレームワークを提案します。MPCはCRPMSMの数理モデルを用いて、電流・トルク・速度が今後数ステップでどのように変化するかを予測し、目標の速度や電流を追従しつつ制限を満たす電圧指令を選びます。その上で、Twin Delayed Deep Deterministic Policy Gradient(TD3)に基づく強化学習エージェントが実際のモータの挙動を観測します。速度誤差、電流誤差、制御努力が小さいほど報酬を与えることで、学習エージェントはモデル誤差、不均衡な負荷、外乱を補償するように徐々にMPCの出力を調整します。最終的に、空間ベクトルパルス幅変調段でこれらの最適化された電圧指令をインバータのスイッチ信号に変換してモータを駆動します。
スマートモータの実機評価に向けた試験
提案手法を評価するため、研究者らはMATLAB/Simulinkで120 kWの反回転モータシステムの詳細なシミュレーションを構築し、三つの現実的な運転シナリオで試験しました。第一は速度を一定に保ちつつ両ロータの負荷が変化するがバランスは取れているケース、第二は負荷を一定にして速度を変化させるケース、第三は最も負荷の厳しいケースで、速度指令は固定のままロータが異なる負荷を受ける状況です。いずれのケースでも、RL-MPCは同じ予測・制御ホライゾンを用いた従来のMPCと直接比較されました。 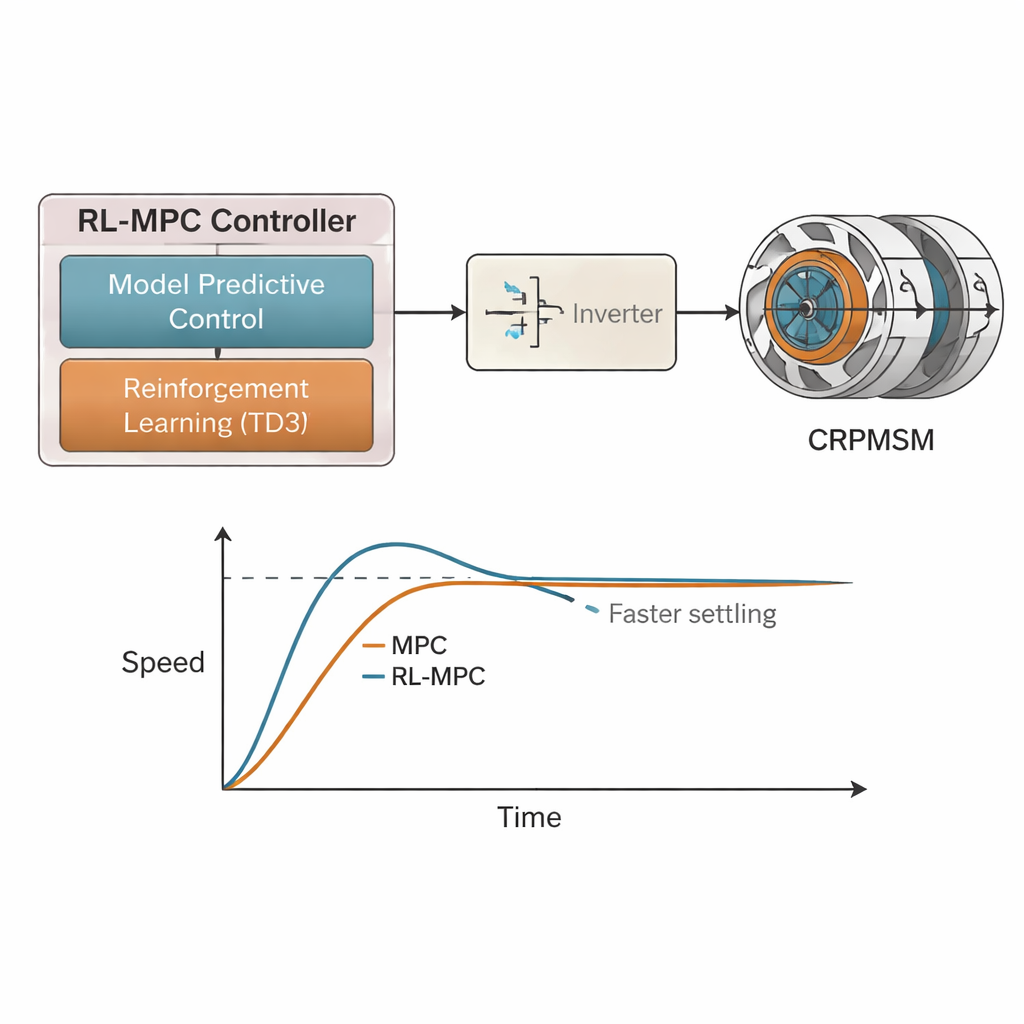
より速い応答、より良い電流品質、改善された同期性
ハイブリッドなRL-MPC制御器は、すべての試験で標準的なMPCを一貫して上回りました。負荷や速度が急変した場合、RL-MPCは速度のオーバーシュートを約30%から約15〜16.6%に削減し、鎮静時間(定常状態に落ち着くまでの時間)を約1.4秒から0.7秒程度に半減させました。トルクリプルも小さく、二つの反回転ロータは、片側がより重い負荷を受ける状況でも高い同期性を維持しました。重要な点として、固定子電流の品質も著しく改善されました:合計高調波歪み(THD)は、過酷な不均衡負荷過渡時に60%以上低下し、MPCでの9.3%からRL-MPCで3.4%へ低下し、定常状態では約2〜3%まで下がることが示されました。電流がきれいになることで発熱が減り、駆動が静かになり、全体効率が向上します。
将来の水中航行体への意義
非専門家向けに要約すると、予測制御の上に学習レイヤを加えることで、潜航艇用モータはより賢く、より頑強になるということです。海況が荒れたり機体が急な操縦を行ったりして従来の固定方程式が通用しなくなっても、RL-MPCフレームワークは現場で適応し続け、二重ロータモータを同期、応答性、効率の面で保ちます。これまでの結果はシミュレーションに基づくもので、実機や実海域での検証が必要ですが、本研究は同じエネルギーでより遠く航行し、騒音を減らし、厳しい条件下でも安定して操縦可能な将来の水中航行体の方向性を示しています。
引用: Delelew, E.Y., Dulecha, K.A., Ararso, Z.T. et al. Reinforcement learning-driven model predictive control for optimizing counter-rotating permanent magnet synchronous motor in submarine propulsion system. Sci Rep 16, 5277 (2026). https://doi.org/10.1038/s41598-026-36126-9
キーワード: 潜航艇推進, 反回転モータ, 強化学習制御, モデル予測制御, 水中航行体