Clear Sky Science · ja
HEViTPose: カスケード型グループ空間縮小注意機構による高精度かつ効率的な2D人体姿勢推定へ
コンピュータにボディランゲージを読ませる
フィットネスアプリから運転支援システムまで、多くの技術は人の動きをコンピュータが理解する能力に依存しています。この能力は人体姿勢推定と呼ばれ、画像や動画から肩、膝、足首などの関節の位置を見つけることを意味します。課題は、日常的なハードウェアでリアルタイムに使えるだけの速度を保ちつつ高精度で推定することです。本論文はHEViTPoseという新しい手法を提案し、高い精度を維持しながら多くの現行システムよりも少ない計算資源で動作することを目指します。
なぜ画像中の関節検出は難しいのか
一見すると関節の位置を見つけるのは簡単に思えます。腕や脚を探せばよいだけだからです。しかし実際には、人はさまざまな大きさで、奇妙な姿勢を取ったり、混雑した場面にいたり、家具や車などの物体に部分的に隠れていたりします。現代の姿勢推定システムは通常、各関節について明るい点が有力な位置を示す詳細な“ヒートマップ”を作成することで対処します。ヒートマップは非常に精密ですが計算コストが高くなります。従来の手法は主に畳み込みニューラルネットワークに依存しており、局所パターンの検出は得意ですが、身体全体にわたる長距離の関係性を捉えるには層を深く重くする必要があります。近年のトランスフォーマーベースのモデルは長距離依存を良く捉えますが、大量のデータと高い計算負荷を必要とすることが多く、リアルタイムや小型デバイスでの利用が難しくなります。
重なりある切り出しでより滑らかな視覚表現を
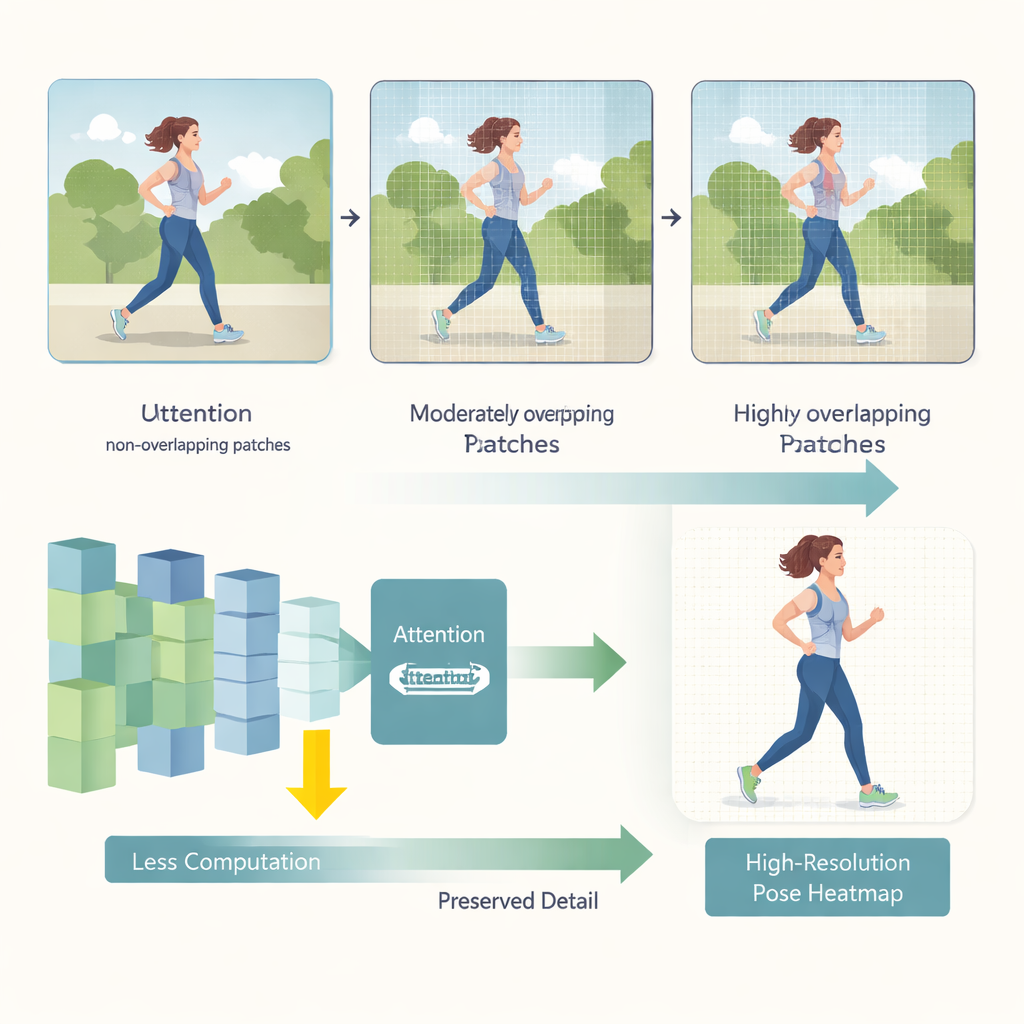
HEViTPoseはまず、画像を解析用に分割する方法を再考します。従来のトランスフォーマーモデルは非重複のタイルに画像を切り分けることが多く、隣接領域間の視覚的連続性を断ち切ってしまうことがあります。たとえば人物の腕がパッチの端で切れてしまいます。HEViTPoseは重なりパッチ埋め込みという考えを発展させ、Patch Embedding Overlap Width(PEOW)という明確で調整可能な指標を導入します。PEOWは隣接タイルが境界に沿って共有するピクセル数を単純に数えます。この重なりを体系的に変化させることで、中程度の重なりがあるとネットワークが隣接タイル間の色や形の滑らかな変化をよりよく“感じ取る”ことが示されています。そのような豊かな局所連続性は、モデルサイズや計算量を大幅に増やさずに、より正確な関節位置推定につながります。
より少ない計算で賢く注目する
第2の重要な革新は、Cascaded Group Spatial Reduction Multi-Head Attention(CGSR-MHA)と呼ばれる新しい注意モジュールです。注意機構はどの画像領域が各予測に影響を与えるべきかをネットワークに示しますが、画像が大きくなると計算量が急増するのが一般的です。CGSR-MHAはこれに対して三つのアプローチで対処します。第一に、特徴をグループに分割し、各グループが情報の一部だけを扱うようにします。第二に、グループごとに注意を計算する前に空間解像度を縮小し、演算量を大幅に削減します。第三に、いくつかの大きなヘッドの代わりに複数の小さな注意ヘッドを使い、計算コストを抑えつつモデルが“注目”できる対象の多様性を保ちます。グループ数、縮小率、ヘッド数の慎重な設定が速度と精度のバランスを実現します。
軽量モデルでも上位に食い込む性能
HEViTPoseを評価するために、著者らは2つの広く使われるベンチマーク、日常活動を集めたMPIIデータセットと多様なシーンの人物を含む大規模なCOCOデータセットで実験を行いました。複数のモデルサイズにわたり、HEViTPoseは主要な姿勢推定システムと同等かそれに迫る精度を達成しつつ、はるかに少ないパラメータ数と計算量で動作します。例えばあるバージョンは、高解像度ネットワーク(HRNet)の人気モデルと同程度の精度を達成しながら、学習可能なパラメータ数を60%以上削減し、計算量を40%以上削減しています。畳み込みとトランスフォーマーを混用した別の最新ハイブリッドモデルと比べても、同等の性能を提供しつつ、GPU上で約2.6倍速く動作します。これらの節約は、より滑らかなリアルタイム性能や低いハードウェア要件に直結します。
日常的な応用にとっての意義
簡潔に言えば、HEViTPoseは人体のボディランゲージをコンピュータに学習させる際に、精度と効率を両立させる必要はないことを示しています。調べる画像領域の切り出しを慎重に重ね合わせ、ネットワーク内での注意計算を再設計することで、高精度に関節を特定しつつコンパクトで高速なモデルが実現します。これはスポーツトラッキング、ビデオ監視、人間とロボットの相互作用、車内モニタリングのように速度と消費電力の双方が重要な実世界の用途にとって魅力的です。HEViTPoseの背後にある考え方――賢い重なりと効率的な注意――は、動物の姿勢追跡や顔のランドマーク検出など関連タスクにも応用でき、多くのデバイスに対してスーパーコンピュータ級のハードウェアを必要とせずにより鋭い“デジタルの目”をもたらす可能性があります。
引用: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
キーワード: 人体姿勢推定, コンピュータビジョン, ビジョントランスフォーマー, 効率的ディープラーニング, 注意機構