Clear Sky Science · ja
メルスペクトログラムと連続ウェーブレット変換特徴を用いた話者識別のためのハイブリッドCNNと強化学習フレームワーク
なぜあなたの声がデジタルの鍵になりうるのか
声だけで銀行口座や玄関、携帯電話のロックを解除できると想像してみてください。その安全性を保つには、背景雑音や感情、悪いマイクの影響があってもコンピュータが確実に個人を識別できなければなりません。本論文は、ロボット工学から借用した試行錯誤型の学習法と現代的な深層学習の手法を組み合わせることで、機械に「何を言っているか」ではなく「誰が話しているか」を認識させる新しい方法を探ります。
音波から声の指紋へ
各人の声には、声道の大きさや形、声帯の振動の仕方、話し方の癖といった微妙な手がかりが宿ります。研究者たちはまず、録音された音声のどの測定可能な特性が人によって実際に異なるのかを問いかけました。LibriSpeechデータセットの40人の英語話者から2,703の音声クリップを用い、音量の変動、異なる周波数帯域のエネルギー、リズム、音の複雑さや予測不能性をとらえるエントロピーなど、22の単純な音響特徴を解析しました。統計的検定により、これら22のうち21の特徴が強い話者固有の情報を持っていることが示され、特にエントロピーと高周波エネルギーが際立って識別力が高いことがわかりました。言い換えれば、個人の「声の指紋」はピッチや音量だけでなく、音の多くの側面に広がっているのです。
音を画像に変える二つの方法
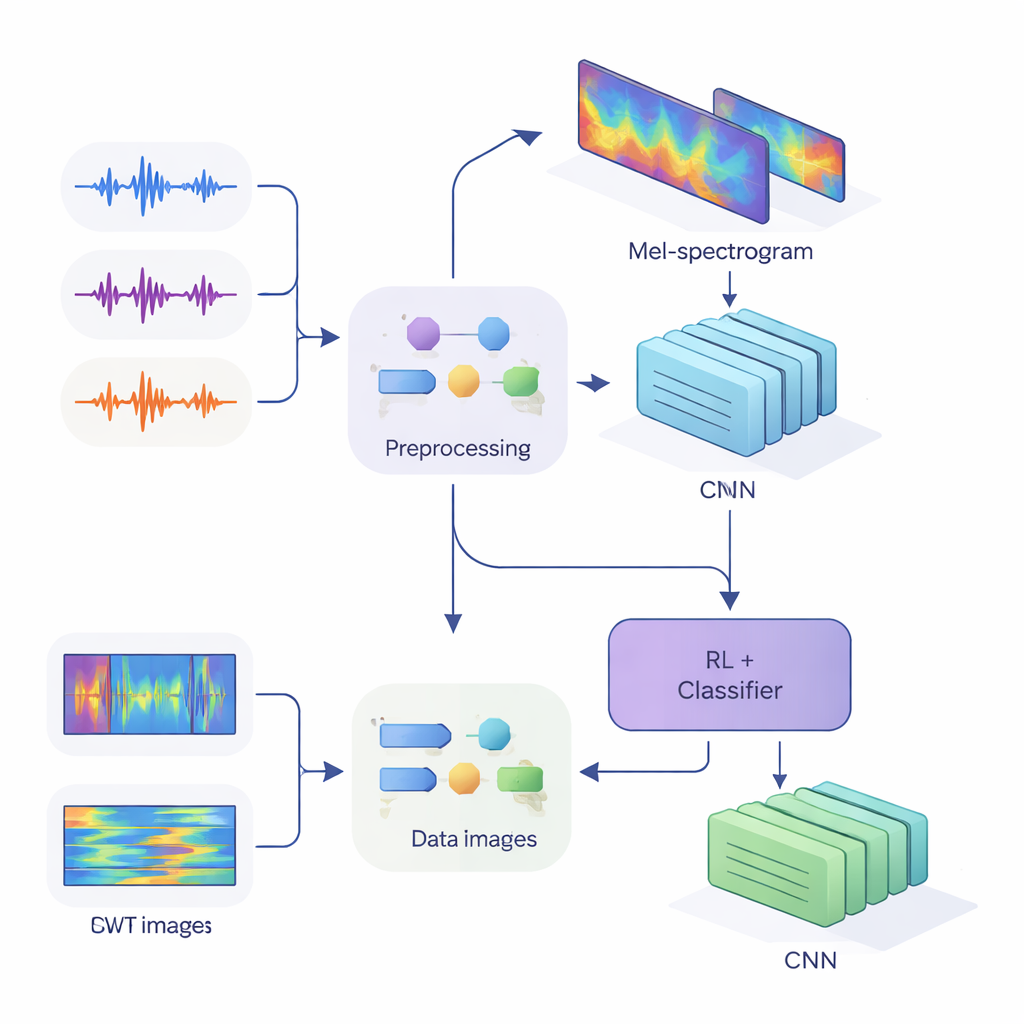
これらの手がかりを現代のニューラルネットワークに入力するため、研究チームは一次元の音声を時間と周波数の変化を捉えた二次元の画像に変換しました。第一の方法はメルスペクトログラムで、人間の耳が周波数をどのようにまとめるかを模倣しており、音声技術で標準的に用いられます。第二の方法は連続ウェーブレット変換で、短く鋭い音と長い母音の両方に対して柔軟にズームできる手法です。音声を慎重に前処理し—無音部分の除去、音量の標準化、小さな歪み(ノイズやピッチの変化)を加えてシステムの堅牢性を高め—、CNNで処理可能なサイズ、メル画像は80×313、ウェーブレット画像は128×128を生成しました。
聞き、そして疑うことを教える
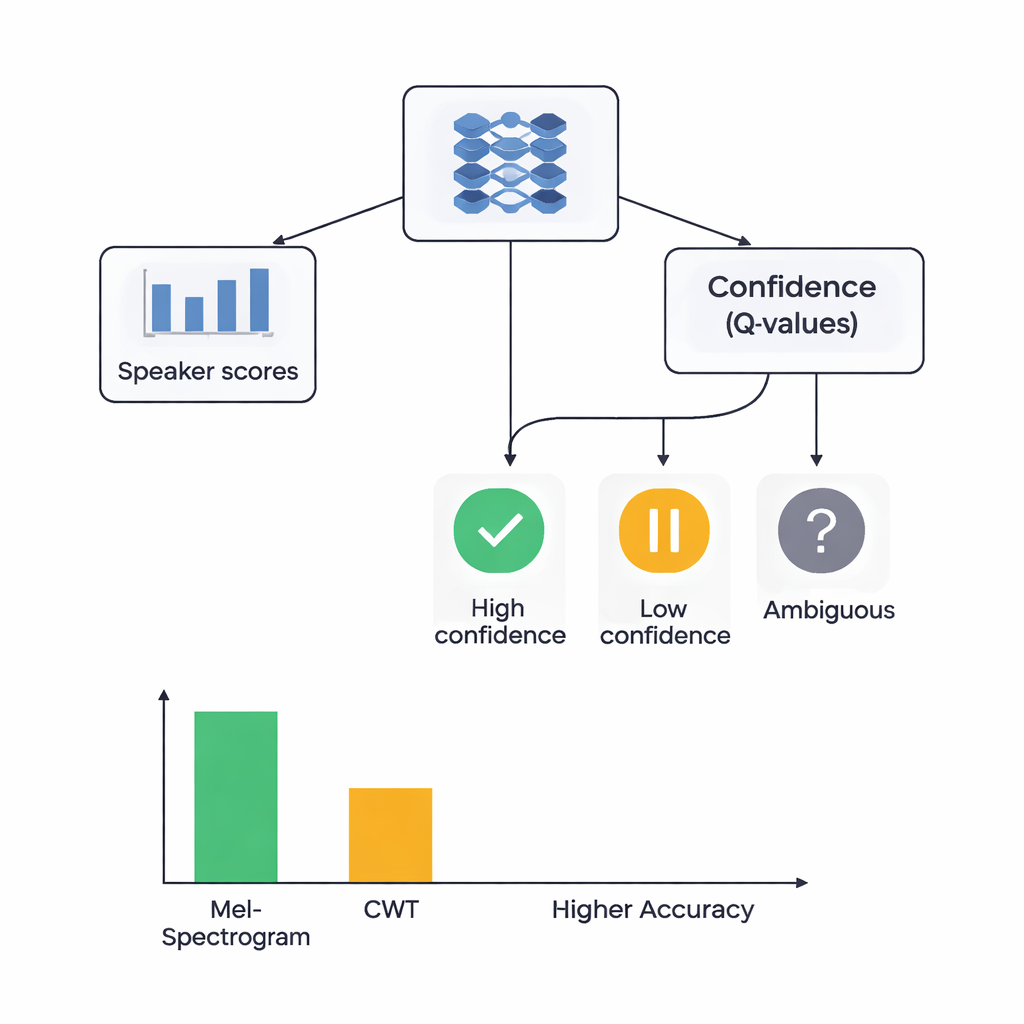
本研究の核心は、二つの学習スタイルを結合したハイブリッドアーキテクチャです。まずCNNがメルまたはウェーブレット画像をスキャンして、特定の話者に属しやすいパターンを抽出します。これは画像認識ネットワークが目やエッジを見つけるのと似ています。メルベースのシステムでは、ネットワークが最も情報量の多い時間区間に注目できるようセルフアテンションモジュールを追加しています。こうした特徴抽出器の上に、各判断における自信の程度を学習する強化学習(RL)コンポーネントを置きます。RLは常に断定的な選択をするのではなく、「これは高い自信を持って受け入れる」「低い自信として扱う」「あいまいとマークする」といった行動に値を割り当てます。多数の学習ラウンドを通じて、自信を持った判断が正しいと報酬が与えられるため、より良く較正された判断へとネットワークが誘導されます。
ハイブリッドシステムの性能はどの程度か?
研究者たちは4つのモデルを比較しました:RLありのメルベース、RLなしのメルベース、RLありのウェーブレットベース、RLなしのウェーブレットベース。いずれも厳密な5分割交差検証で評価され、各音声クリップは異なるラウンドで訓練とテストの両方に使われました。メル+RLのシステムが最良の成績を示し、話者を正しく識別した割合は約88%で、標準的な識別力指標では話者間の分離がほぼ完璧でした。ウェーブレット+RLは約78%の精度に達しました。重要なのは、RLを追加することで両特徴タイプともに性能が約3パーセントポイント向上し、データ分割間で結果がより一貫したことです。RLを導入すると、特に混同しやすい難しい声に対して信頼度を考慮した判断が功を奏し、高品質な認識を達成する話者クラスが増えました。
日常の音声セキュリティにとっての意味
非専門家向けの要点は、信頼できる音声による本人確認には音声の豊かな表現と、機械側の健康的な疑念(=不確かさを表明できること)の両方が必要だということです。本研究は、耳に触発されたメルスペクトログラムがアテンションと「よく分からない」と言える強化学習者を組み合わせることで、話者を区別するタスクにおいてより奇抜なウェーブレット画像よりも優れた性能を示すことを明らかにしました。研究は比較的小規模でクリーンなデータセットを用いており、まだ騒がしい実世界環境向けに調整されているわけではありませんが、深層ニューラルネットワークの上に自信認識の層を加えることで、音声認証がより正確で信頼できるものになり得ることを示しています。これは私たちの声が安全なデジタル鍵になるための重要な一歩です。
引用: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
キーワード: 話者識別, 音声バイオメトリクス, ディープラーニング, 強化学習, メルスペクトログラム