Clear Sky Science · ja
適応的非パラメトリック次元削減のための一般的枠組み
ビッグデータを縮めることが重要な理由
現代の生活はデータによって動いています:医療スキャン、オンライン購買履歴、写真、ニュースフィードなど。各記録は数百〜数千の測定値を含むことがあり、保存や解析、さらには可視化さえ困難です。科学者は「次元削減」を用いて、この複雑さを重要なパターンを保ったままより単純な図やモデルに圧縮します。しかし、今日広く使われている手法の多くは、多くの手動による選択や試行錯誤が必要です。本論文は、データ自身に最適な縮小方法を決めさせる手法を示し、より明瞭な可視化、より正確な学習、そしてユーザーの推測作業を減らすことを目指しています。
単純な直線から曲がりくねった現実へ
データを単純化する古典的手法である主成分分析(PCA)は、物体に光を当てて影を見るように作用します:ばらつきの大部分を説明する最良の平坦な方向を見つけます。データの構造が概ね直線的または平坦である場合には強力です。しかし、画像、テキスト、センサ測定などの実データは、多くの場合、高次元空間の中に隠れた曲がった曲面上に存在します。過去二十年で、Isomap、局所線形埋め込み(LLE)、スペクトル埋め込み、UMAP などの「非線形」手法が、こうした曲がった形状を明らかにするために開発されてきました。これらは局所的な近傍に依存し、各点について最近傍を調べ、その小さなスケールでの関係を低次元図に保とうとします。しかし、これらの手法はユーザーに二つの重要なつまみ――使う近傍数と射影先の次元数――を選ばせます。選択を誤ると、結果が誤解を招いたり計算コストが高くなったりします。
データ自身に近傍を選ばせる
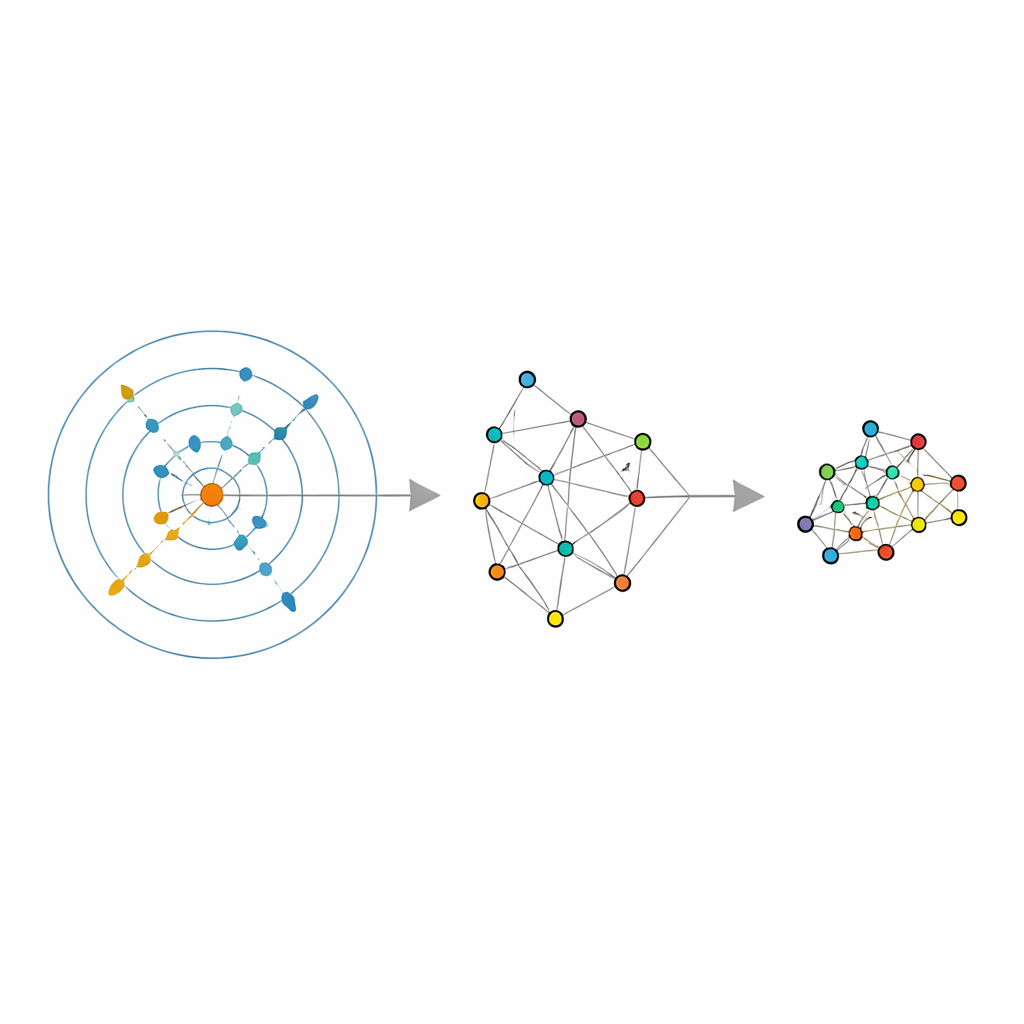
著者らは内在次元推定器と呼ばれる最近の統計ツールに基づいています。これは簡単な問いに答えようとします:ノイズを取り除いたとき、データが本当に独立に変動する方向は何本あるか? 著者らの推定器であるABIDEはそこからさらに進みます。各点の周りで、自動的にその近傍が適度に均一に見えるかどうか――小さすぎてノイズが多いわけでも、大きすぎて歪んでいるわけでもない――を探索します。これにより二つの情報を返します:データの真の次元に関する全体推定値と、各点ごとの最適な近傍サイズです。これによって従来の固定された「近傍数」は局所的に適応する量に変わり、まばらな領域では大きく、密集した領域では小さくなり、データの実際の密度に合わせます。
古典的手法を適応型へ変える
これらの適応近傍と推定された内在次元を用いて、著者らは複数の人気のある次元削減およびクラスタリング手法を改良します。LLE では、ユーザーが選ぶ単一の近傍数を ABIDE が返す点ごとの値に置き換え、目標次元も推定された内在次元に設定します。アルゴリズムは、各点を慎重に選ばれた局所群から再構成する方法を学び、それらの局所再構成を最もよく保つ全体の低次元配置を見つけます。類似の発想は、点間の類似性のグラフを使うスペクトルクラスタリングや、点の結びつきをあいまいに表す UMAP にも適用されます。いずれの場合も、固定された近傍サイズはデータ駆動の柔軟な構造に置き換えられ、データの自然な幾何に従います。
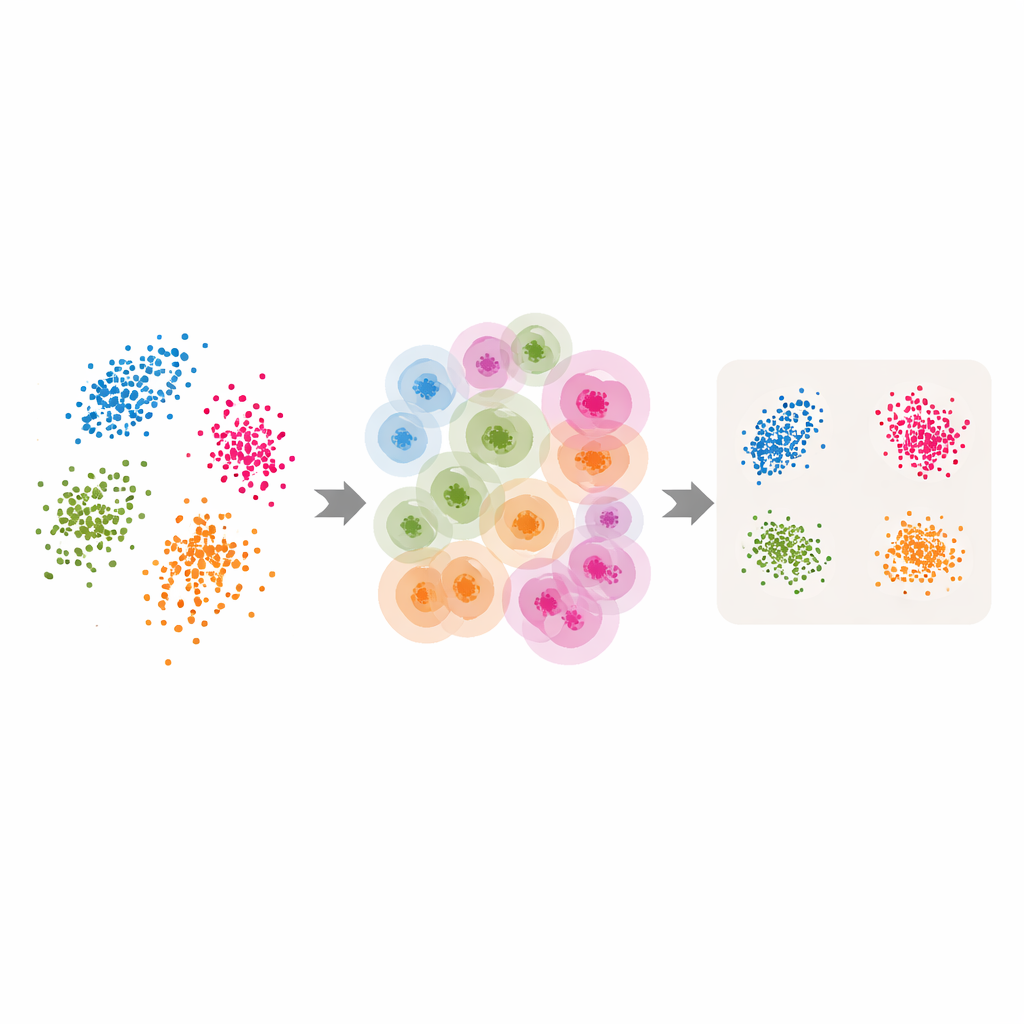
花、数字、テキスト、合成形状での検証
この適応的アプローチが効果的かを検証するため、著者らは複数のベンチマークで実験を行います:古典的なアヤメ(Iris)の測定、手書き数字画像(MNIST)、言語モデル埋め込みで表されたニュース記事、ノイズを加えた合成の三次元形状などです。適応版を標準ソフトウェア設定や注意深く調整したハイパーパラメータのグリッドと比較します。クラスタリングや可視化などの教師なしタスクでは、適応手法は通常、より明瞭なクラスタ、より密なまとまり、標準的な品質指標での良好なスコアをもたらします。例えば、点の密度が不均一な複雑な多様体では、適応手法が固定近傍版よりも真の構造をはるかによく回復します。教師ありテストでは、削減されたデータを分類器に入力した場合でも、適応アプローチは徹底的な調整を行った最良の固定設定に匹敵するかそれを上回り得ます。
日常的なデータ解析にとっての意味
専門家でない人や実務者にとっての主なメッセージは、データの縮小が推測に頼る必要はないということです。データ自身の幾何を用いて「近傍の数」と「次元数」を決めることで、この枠組みは LLE、スペクトルクラスタリング、UMAP といった広く使われるツールをより賢く、より堅牢なものに変えます。その結果、データの真の形状をより反映した信頼できる低次元の可視化や特徴が得られ、手動でのハイパーパラメータ探索に費やす時間を減らすことが多くあります。実務的には、大規模な画像コレクションの可視化、文書のグルーピング、予測モデルの入力準備といった作業が、データ自身に適応させることでより簡単かつ信頼できるものになるということを意味します。
引用: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
キーワード: 次元削減, 多様体学習, 最近傍, 内在次元, データ可視化