Clear Sky Science · ja
ガウス分布修復法とコーシー逆学習を備えた拡張一般化正規分布最適化器による特徴選択
なぜ適切なデータ選びが重要か
現代の生活は医療画像や銀行記録、ソーシャルメディアのフィードに至るまでデータに支えられています。しかし、データが多ければ良いというわけではありません。コンピュータに何千もの生データを一度に学習させると、処理が遅くなりコストが上がり、意外にも精度が低下することがあります。本稿は、これらの測定値をより賢くふるいにかけ、本当に重要なものだけを残す手法を提示します。提案手法はBinary Adaptive Generalized Normal Distribution Optimizer(BAGNDO)と呼ばれる新しいアルゴリズムです。
手がかりが多すぎる問題
病気の診断を例に考えてみてください。数百の臨床検査、画像、アンケートの回答があると、多くの「特徴」はノイズであったり冗長であったり、そもそも無関係であることがあります。それらすべてを分類器に投入すると、むしろ混乱を招くことがあります。特徴選択は、入力変数のうちより情報量の多い小さな部分集合を選ぶことで、機械学習モデルをより高速に、低コストに、信頼できるものにすることを目指します。単純な統計的フィルタは明らかに有用でない特徴を除去できますが、使用するモデルに合わせた選択にはならず、変数の微妙な組み合わせを見落としがちです。より高度な「ラッパー」法は分類器の性能を直接評価して特徴集合を判断しますが、これにより探索問題が途方もなく大きくなります。特徴数が増えると、可能な部分集合の数は爆発的に増加します。
盲目的ではなく賢く探索する
この爆発的な組合せを扱うために研究者はメタヒューリスティックアルゴリズムに頼ります。これらは自然や物理現象に着想を得た探索戦略で、広い探索と局所的な精緻化のバランスを取ります。ひとつの手法であるGeneralized Normal Distribution Optimizer(GNDO)は、候補解を柔軟な釣鐘型分布から得られるものと見なし、その分布を徐々により良い解に向けて移動させます。GNDOは工学やエネルギー分野で有効でしたが、特徴選択に適用すると、まずまずの解に早期収束しやすく、グローバルな探索と局所的な微調整のバランスを取るのが難しいという課題があります。著者らはここに重要なギャップを見いだします:GNDOの洗練された数理は、高次元の有無二値の特徴選択問題にそのまま強力な性能をもたらすわけではないのです。
古典的エンジンへの三段階アップグレード
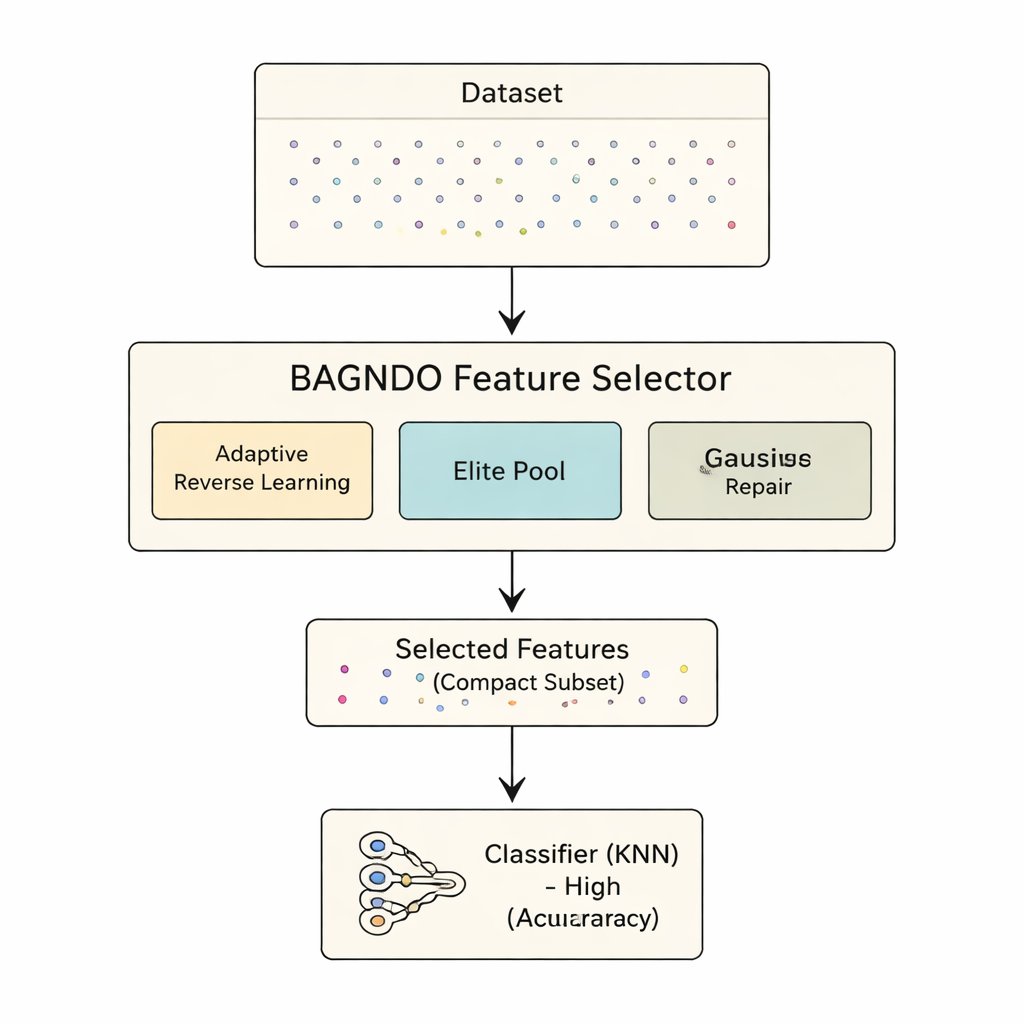
提案されるBAGNDOフレームワークは、GNDOを三つの協調したアイデアで強化します。第一に、Adaptive Cauchy Reverse Learning戦略は、重い裾の確率分布を用いて定期的に現在の解の「鏡像」を生成します。これにより探索空間の未踏領域へ大胆に跳躍することが促され、局所的な落とし穴に陥るのを防ぎます。第二に、Elite Pool Strategyは単一の最良解だけでなく、複数の上位解と混合された“ガイド”候補を保持します。このより豊かなリーダー群は多様性を保ちながらも有望な領域へ探索を導きます。第三に、Gaussian Distribution-based Worst-solution Repair法は最も弱い候補を精査し、エリート群から学んだパターンに近づけるように調整します。これにより悪い解を単に破棄するのではなく、より良いものへ再生させることができます。
手法の実証
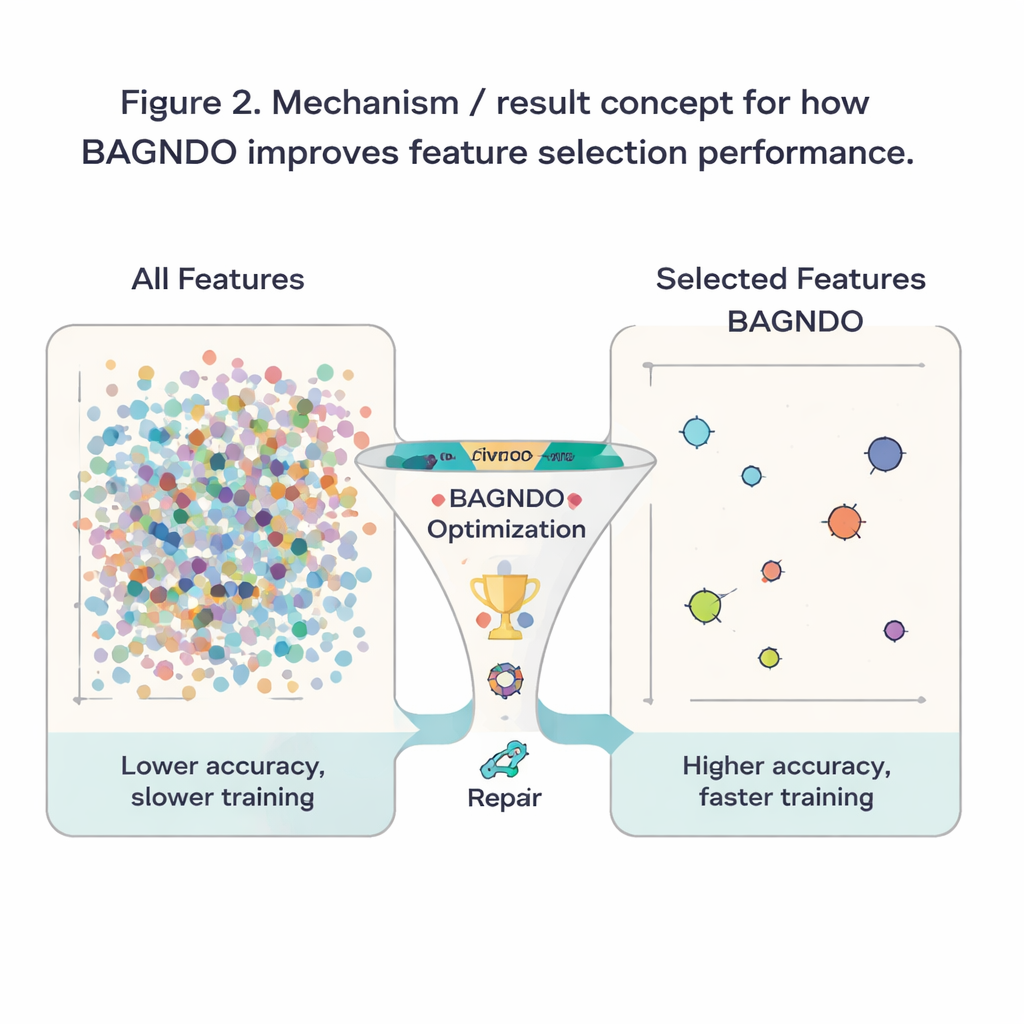
これらのアイデアが実際に効果を発揮するかを確認するため、著者らはUCIリポジトリからの医療診断、ゲーム、信号などを含む18のよく知られたベンチマークデータセットにBAGNDOを適用しました。各ケースで、標準的なk近傍法分類器が高い予測精度を出すような特徴の部分集合を探索しました。BAGNDOは粒子群最適化や遺伝的手法、いくつかの近代的な群知能アルゴリズムなど、9つの強力な競合手法と比較されました。テスト全体を通じて、BAGNDOは予測精度を維持あるいは向上させながら、より小さな特徴集合を一貫して見つけました。18データセット中14で最もコンパクトな特徴集合で最高の精度を達成し、統計検定によりこれらの改善が偶然によるものではないことが確認されました。
日常の機械学習にとっての意義
一般に分かりやすくまとめると、著者らは学習アルゴリズムがデータセット内で本当に重要なものに集中できるようにする、より規律ある「特徴選択ツール」を構築したということです。広い探索、エリートによる指導、および低評価候補の修復をうまく組み合わせることで、BAGNDOは不要な入力を削ぎ落としつつ精度を維持または向上させます。これによりモデルの高速化、記憶・計算コストの削減、どの測定値や質問が最も情報を持つかについての洞察が得られやすくなります。手法は一部の単純な代替法より計算コストが高いものの、精度や解釈性が重要な問題、たとえば医療の意思決定支援や産業監視などにおいて強力なツールを提供します。
引用: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
キーワード: 特徴選択, メタヒューリスティック最適化, 機械学習, 次元削減, 分類精度