Clear Sky Science · ja
文脈に沿った生物医学的実体を特定する自動化:グラウンデッドLLMの活用
医療論文のより賢いタグ付けが重要な理由
毎年、遺伝子、細胞型、疾患、治療に関する詳細を詰め込んだ何千もの生物医学研究が発表されます。しかし多くの情報は長いPDFに閉じ込められたままで、他の研究者が必要なデータを正確に見つけるのが難しくなっています。本稿は、現代の人工知能、具体的には大規模言語モデル(LLM)が研究論文から重要な生物医学用語を自動抽出し、散在する公表物を整理された検索可能な資源へと変える手助けができる方法を探ります。
散らかった論文から検索可能な構成要素へ
ドイツの共同研究センターのような生物医学研究拠点は、研究を何年にもわたって再利用可能にするために明確で構造化されたデータを必要とします。従来は、研究者が生物種、細胞株、遺伝子などの重要な実体を手作業でタグ付けする必要があり、手間と時間がかかっていました。LLMは論文全文を読み文脈を理解できるため、このタグ付けの自動化に有望です。ただし問題があります:どの用語が真に関連するかは科学的な問いやデータの再利用方法によって決まります。著者らは腎臓学に焦点を当てたCRC「NephGen」の精巧に設計されたメタデータスキームの下で作業しており、AIにどの種類の実体を探しどのように整理すべきかを指示します。
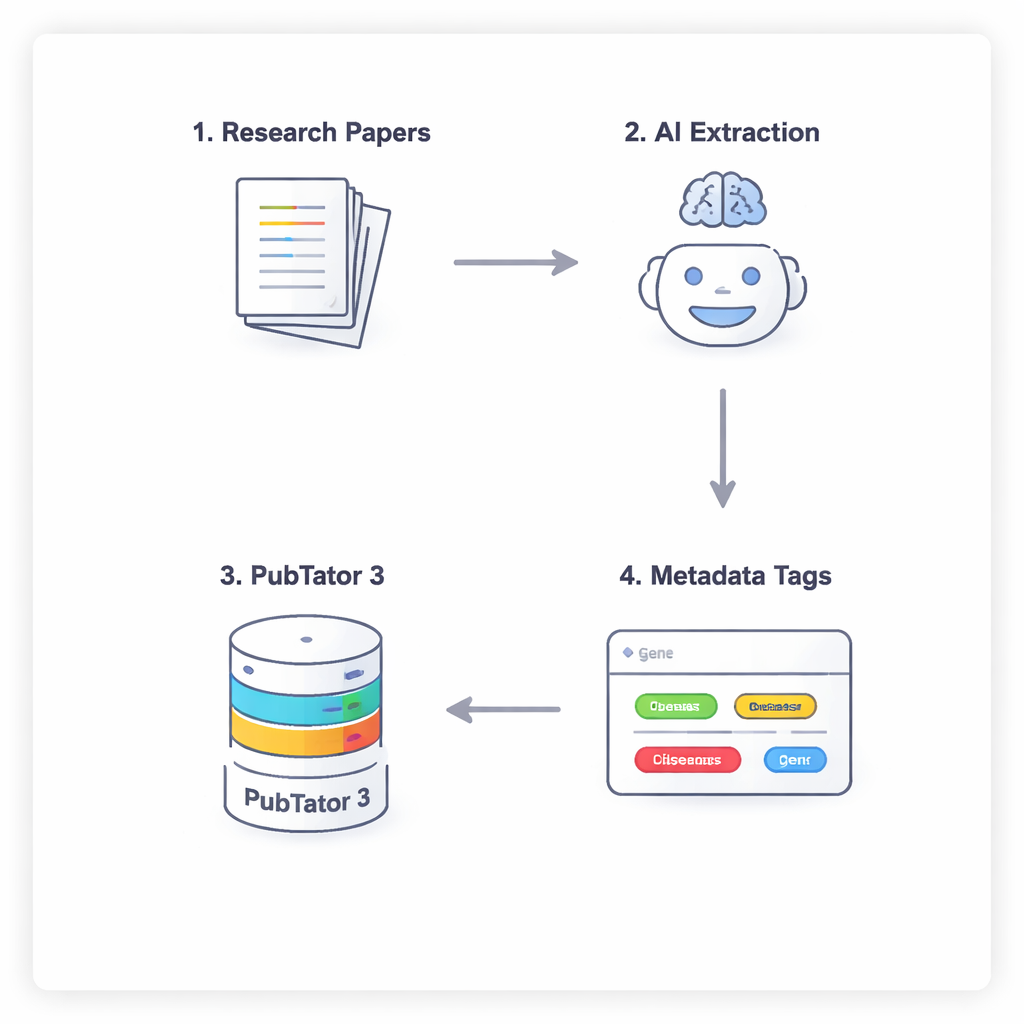
AIと生物学データベースの四段階の対話
AIが単に推測や「幻覚」を起こして生物医学的事実を捏造しないように、研究者らはモデルに慎重な推論と自己検証を強いる四段階のプロセスを用います。まず、モデルは論文の本文(議論と参考文献は除外)を走査して潜在的に関連する実体を提案します。次に、提案された各用語が実際に存在し、認識された識別子を持つことを確認するために外部ツールであるPubTator 3を参照しなければなりません。第三に、AIは確認済みの各実体を階層的で人間が設計した構造で実体をグループ化するNephGenのメタデータスキーム内のスロットに割り当てます。最後に、モデルはこれらすべてを構造化されたJSON出力に統合し、論文中の主要な生物医学的実体の機械可読な要約を作成します。
実際の腎臓研究で8つのAIモデルを検証
チームはこのワークフローを14種類のLLMのAPIで実装し、厳格な要件(有効なJSONを返すことやツールを正しく使用することなど)を確実に満たせるのは8モデルだけであることを発見しました。次にこれら8モデルを6本の腎臓学研究論文に適用し、各論文の著者に短時間の対面インタビューでAIの最終的な実体リストをレビューしてもらいました。抽出すべき実体の“正解”数が固定されないため、著者らは精度(提案された実体のうち科学者が正しいと判断した割合)に注目しました。100%に近い割合に合わせた統計的メタ解析手法を用いて、論文間のばらつきを考慮しつつ各モデルの精度を推定しました。
高精度だが手間・コスト・速度にトレードオフあり
全モデルを通じて、AIシステムは約91%の総合精度を達成し、提案された実体の大多数が正しいと判断されました。GPT-4.1、GPT-4o Mini、Gemini 2.0 Flashは最も高い精度(おおむね94%〜98%)を示しましたが、その差は統計的には明確ではありませんでした。Gemini系モデルは全体としてより多くの実体を提案する傾向があり、正しいタグも多くなる一方で人間がチェックすべき項目も増えます。GPT-4.1 Nanoのような小型で低価格のモデルは高速で安価ですが、精度はかなり低くなることがありました。著者らはこれらの緊張関係をパレート前線で可視化し、精度、正しい実体数、コスト、処理時間のバランスを取るモデルの組み合わせを特定しました。例えば、精度と低コストの両方が優先される場合、GPT-4o Miniが特に魅力的であることが示されました。
なぜ人間が依然として必要なのか
高い性能にもかかわらず、本研究は重要な限界を浮き彫りにします。モデルは発表された論文に関する情報と、将来の利用者が再利用したいデータセットの本質にとって真に関連する詳細を混同することがありました。この混乱は自動テキストマイニングにおけるより広い課題を反映しています:論文は共有されるデータセットに含まれる以上のことを論じることが多いのです。したがって著者らは、AI生成注釈が公開される前に専門家によるレビューを継続することを推奨します。また評価は6本の腎臓学論文のみに限られるため、分野横断的なさらなる検証が必要であると指摘しています。時間をかけて「人間を介した」ルーチンワークフローが合意された参照セットを構築すれば、精度だけでなくAIが見逃した実体の数も測定できるようになります。
将来の生物医学データ共有にとっての意味
本研究は、信頼できるデータベースに基づき丁寧に指示を与えれば、現代のLLMが生物医学論文の注釈付けを確実に支援し、研究者の手作業の負担を大きく軽減できることを示しています。最良のモデルは専門家レベルの精度に近づきつつ、網羅性、コスト、速度の間でさまざまなトレードオフを提供します。現時点では注釈がデータセットや研究文脈と真に一致することを保証するために人間のレビューが不可欠です。しかしツールやオープンソースモデルが成熟するにつれ、このようなワークフローは今日の医療論文の洪水を明日の整理された再利用可能なデータコモンズに変える標準的な基盤となり得ます。
引用: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
キーワード: 生物医学テキストマイニング, 大規模言語モデル, メタデータ注釈, グラウンデッドAI, 腎臓学研究