Clear Sky Science · ja
ダンス動作解析への深層強化学習アプローチ
私たちのようにダンスを“見る”コンピュータを教える
バレエからヒップホップまで、ダンスにはリズムやポーズの微妙な変化が満ちており、人間の目はそれを瞬時にとらえますが、コンピュータには見分けが難しいことが多い。本研究は、AIがダンス動画を人間の専門家のように「見る」新しい方法を提示します。つまり、定型的な部分をすばやく飛ばして、そのスタイルを特徴づける短く示唆に富む瞬間に注目するようにするのです。その結果、はるかに短い視聴でダンスジャンルをより正確に認識できるシステムが得られ、デジタルアーカイブからスポーツやエンターテインメント技術まで幅広い分野に恩恵をもたらす可能性があります。
なぜダンス動画は機械にとって難しいのか
一見すると、ダンススタイルを認識するコンピュータを訓練するのは簡単に思えます。動画を与えて深層学習にパターンを見つけさせればよいからです。しかし実際には、多くの既存システムは無駄な処理をしてしまいます。標準的なビデオモデルはすべてのフレームを処理するか、一定間隔でクリップをサンプリングするため、すべての瞬間が同じように重要だと仮定します。しかしダンスの違いはしばしば細かい点にあり—足の回し方、パートナーの回転のタイミング、スピンのタイミング—常時の動きそのものではないことが多い。つまり多くのフレームが反復的または情報の少ないものになり、重要なポーズが固定サンプリングの間に入ってしまうと、ワルツとフォックストロットのように混同が生じます。
映像を賢く拾い読みする方法
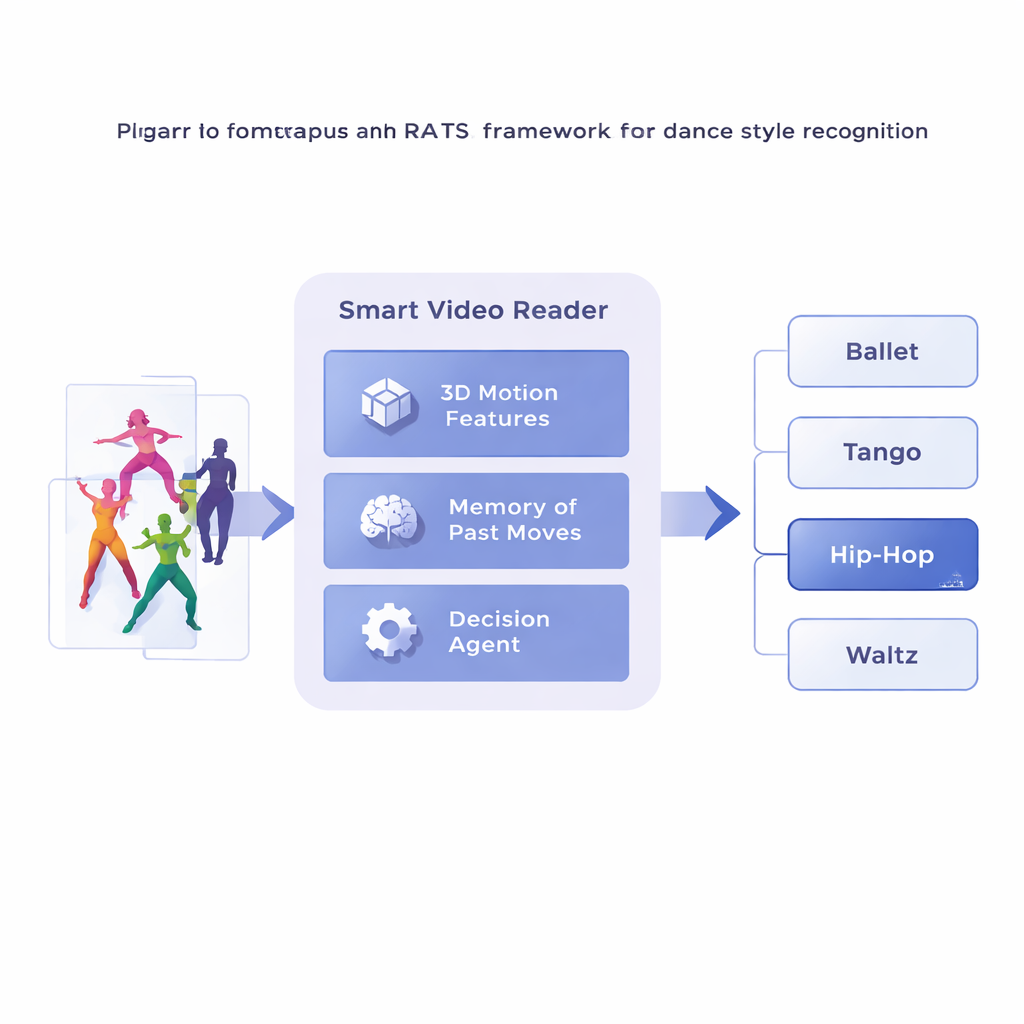
研究者らは、Reinforcement-based Attentive Temporal Sampling(強化に基づく注意的時間サンプリング)、略してRATSというフレームワークを提案します。これは映像解析を受動的な閲覧ではなく能動的な探索として扱います。フレームを行進するように逐次処理する代わりに、システムはダンス映像を短いクリップに分割し、各クリップをまず特殊な3D畳み込みネットワークで動きのコンパクトな記述に変換します。これらの動きの要約はメモリに保存されます。その上で、意思決定エージェントがクリップ列を踏み進みながら、小さなジャンプで先に進むか、大きなジャンプで飛ばすか、あるいは停止してスタイル予測を出すかを選びます。実質的にシステムは時間をどう閲覧するかを学び、語るべきパターンに留まり、有用でない区間を飛ばします。
いつ見るべきか、いつ判断するべきかを学ぶ
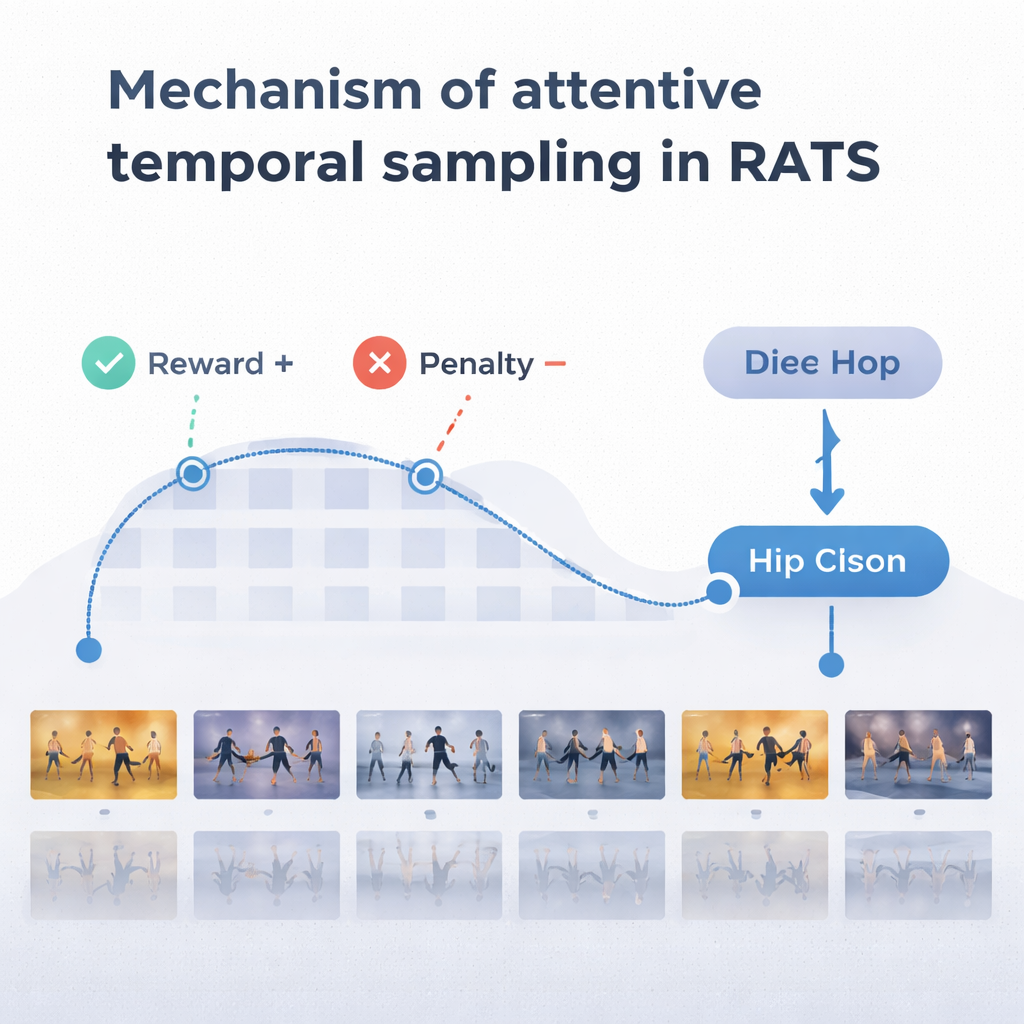
合理的な選択を行うために、エージェントは過去と現在の動きの両方を思い出す方法から着想を得た一種のメモリに依存します。双方向の再帰ネットワークがシステムがすでに「見た」ものと現在のクリップがその履歴とどう関連するかを追跡します。各ステップで、エージェントは三つの選択肢を比較検討します:細かな足さばきなどを調べるために短く跳ぶ、反復的な動きを飛ばすために長く跳ぶ、あるいは停止してダンスを分類する。システムは報酬と罰則で訓練されます:正しい判断には大きな正のスコア、誤った判断には大きな負のスコア、そして前方にジャンプするたびに小さな罰則が与えられます。このバランスにより、エージェントは十分な証拠が得られるまで待つが、動画全体を漫然と見て回らないように、正確さと効率の両方を重視するよう促されます。
従来のダンス分類器を上回る性能
研究チームはRATSを、フラメンコやタンゴからスウィングやスクエアダンスまでの10スタイルを含む1,000本の動画という難易度の高いコレクション「Let’s Dance」データセットで検証しました。標準的な深層ネットワークや他のダンス特化モデルを含む複数の既存手法と比較して、RATSは約92%の最高精度と、精度と再現率の全体的なバランスで最良の成績を達成しました。また、単なる偶然の差ではなく、強力な競合手法より統計的に優れていることも示されました。重要なのは、システムが平均で約38%のフレームしか解析していないにもかかわらずこれらの結果を達成した点です。数フレームごとに一様にサンプリングする方法はより速いものの重要な瞬間を見落とし性能が低下し、すべてのフレームを処理する方法は遅く、それでも標的型のアプローチほど正確ではありませんでした。
ダンスフロアを越えて意味するもの
非専門家にとって核心的なメッセージは明快です:コンピュータは選択的な視聴を学ぶとより良く機能するということです。AIに時間の「黄金の瞬間」に集中することを教えることで、この研究は機械がより少ないリソースで複雑な人間の動作をより正確に認識できることを示しています。本研究はダンスに焦点を当てていますが、同じ考え方はスポーツのルーティン、監視映像、あるいは重要な出来事が短く点在する長時間の動画などで重要な要素を選び出すのにも役立つでしょう。言い換えれば、より多く見るのではなく、より賢く見ることがビデオ理解の未来かもしれません。
引用: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
キーワード: ダンス認識, ビデオ解析, 深層学習, 強化学習, 人体の動き