Clear Sky Science · ja
地理意味特徴を統合した中国語空間関係抽出モデル
場所がどこにあるかをコンピュータに教える
私たちは日常的に「町が川の南にある」「公園が大学の近くにある」「高速道路がある省を通る」といった簡潔な表現で場所を記述します。こうした日常言語を正確なデジタル知識に変換することは、スマートマップ、ナビゲーションアプリ、地理学的研究にとって不可欠です。本論文は PURE‑CHS‑Attn と呼ばれる新しい手法を提案し、中国語テキストを読み取って場所同士の空間関係を従来よりも正確に自動抽出できるようにします。
空間言語が重要な理由
空間関係とは「内部に」「隣接して」「北に」「30キロ離れている」など、場所同士が空間的にどう結びついているかを示す語句です。これらは地図上の現実世界と私たちが頭の中で持つ概念をつなぐ橋渡しをします。地理情報システム(GIS)では、データの整理、検索、解析の基礎を成します。衛星画像の統合、映像中の動体追跡、施設配置の計画、気候や地形が生物多様性に与える影響の研究など、他分野でも中心的な役割を果たします。多くの情報が自然言語で記述されているため、テキストを読み空間関係を自動で抽出する信頼できるツールの重要性は増しています。
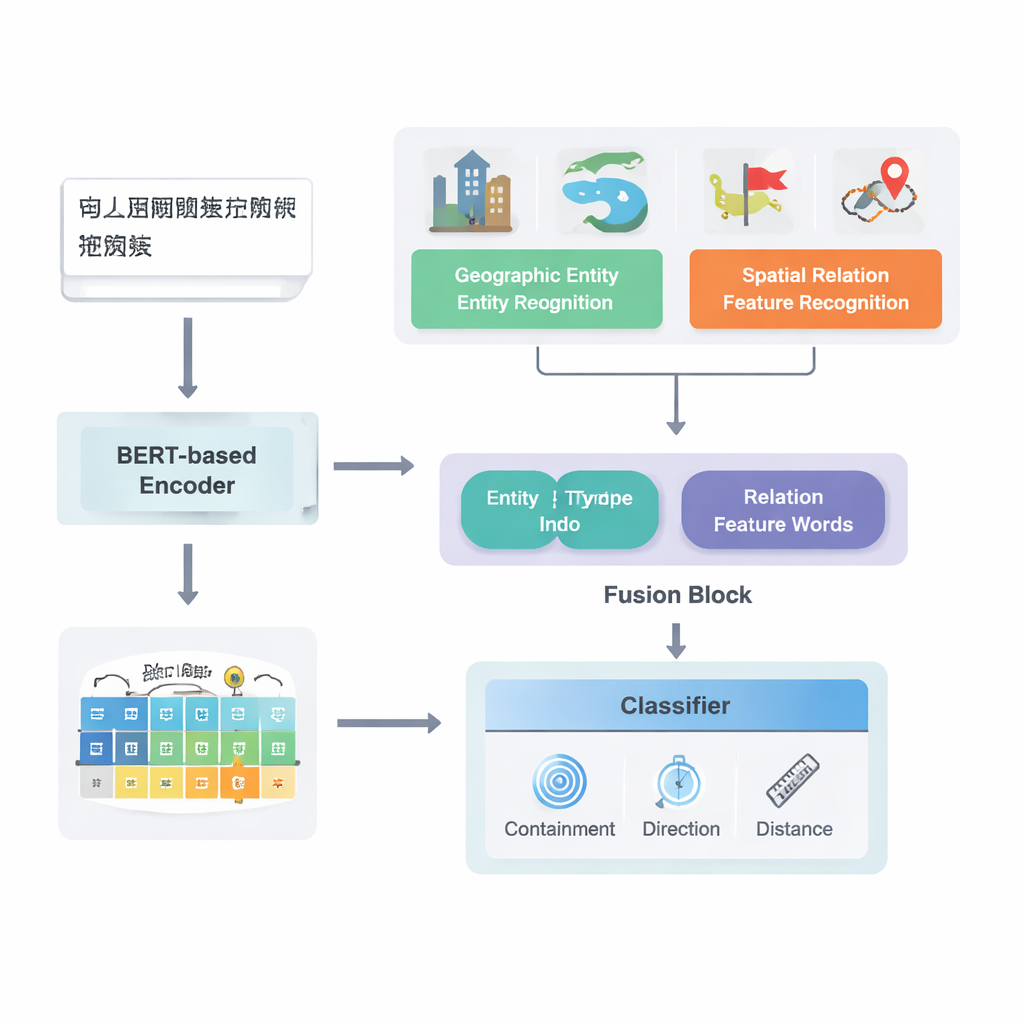
生のテキストから地図化された関係へ
著者らは中国語テキストに着目し、既存の強力な深層学習パイプラインである PURE を基盤に構築しています。拡張モデル PURE‑CHS‑Attn は複数段階で動作します。まず文を走査して山、川、都市、行政区などの地理的実体を検出し、それぞれを地表、水域、公共施設、史跡、行政区画などのタイプでラベル付けします。次に「境界」「流れる」「南に」「近く」など、二つの場所の関係を示す空間関係の特徴語を検出します。強力な言語モデル BERT‑wwm‑ext が各文の文字を意味と文脈を捉えた数値ベクトルに変換します。これらのベクトルは実体認識と関係語認識の各コンポーネントに供給され、得られた結果は融合モジュールへ渡されます。
人間の知識と機械学習の融合
この研究の新規性の鍵は、地理的知識と学習済みテキストパターンをどう融合するかにあります。全ての語を同等に扱うのではなく、人間が自然に使う二種類の意味情報――各地理実体のタイプとそれらをつなぐ特定の空間特徴語――を活用します。融合モジュールはまず、二つの実体のベクトルをそれぞれのタイプの組み合わせ(たとえば二つの行政区同士か、川と県か)がどの関係型に関わりやすいかの頻度に基づく重みで結合します。つぎに空間特徴語のベクトルを混合します。この「基本融合」の上に、著者らは注意機構を導入し、実体–語の組合せの中で最も情報量の多い部分に動的に着目できるようにしています。最終的な融合表現は分類器に渡され、文中の各場所対に対して位相(包含・隣接など)、方向(北・南など)、距離に基づく関係など一つまたは複数の関係タイプを割り当てます。
モデルの検証
手法の評価のため、研究チームは『中国地理百科』から 1381 文と 368 件の空間関係ペアを含むデータセットを収集し、厳密に注釈しました。比較対象として、粗い位置情報のみを使うベースライン、より細かい実体タイプを加えた版、空間特徴語をさらに追加した版、そして新しい融合と注意設計を備えた完全な PURE‑CHS‑Attn を用いました。適合率(precision)、再現率(recall)、F1 スコアという標準的指標で評価したところ、PURE‑CHS‑Attn はベースラインに比べ適合率で約7%、再現率で約6.5%、F1で約6.7%の改善を示しました。特に位相関係と方向関係の認識で強く、少数例しかない「few‑shot」関係タイプも単純なモデルよりうまく扱えました。大規模言語モデルに基づくものを含む最近の最先端システム3種と比較して、PURE‑CHS‑Attn は僅差の2位に入りつつ、構成が軽量で導入しやすい点が特徴でした。
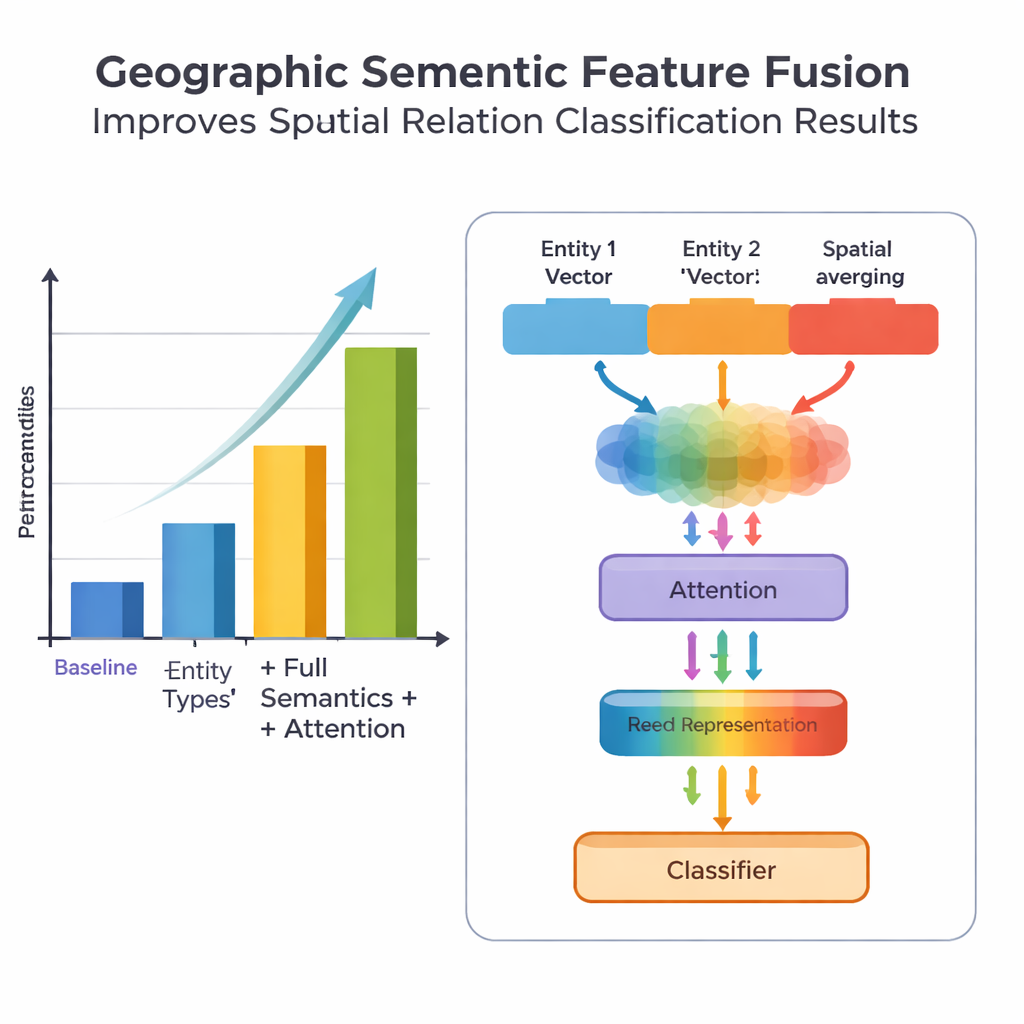
課題と今後の方向性
こうした改善にもかかわらず、モデルは依然として距離に関する関係の扱いに苦戦しており、特に学習例がほんのわずかしかない場合に顕著です。著者らは自分たちのデータセットにそのようなケースが非常に少ないことを示しており、データを多く必要とする手法の学習が制約されると述べています。また、文中の多数の空間特徴語を無差別に平均化するとノイズが入ることがあり、注意機構は改善するものの完全な解決には至っていません。今後の有望な方策として、データ拡張による訓練データの拡充と均衡化、そして地理意味融合を大規模言語モデルやプロンプトベース学習と組み合わせることで、データ希薄な状況でも効率を維持しつつさらに性能を高めることを提案しています。
日常の地図利用にとっての意義
平たく言えば、この研究はコンピュータに中国語の空間記述を人間のように読み取らせる方法を教えており、どの種類の場所が言及され、どのような表現でその関係が述べられているかに注意を払います。PURE‑CHS‑Attn は構造化された地理知識と最新の深層学習を融合することで、テキストから「誰がどこに、何に対して」をより正確かつ堅牢に抽出できることを示しています。これにより、より賢い自動化された GIS システム、豊かな地理知識グラフ、および科学、政策、日常的コミュニケーションにおける空間表現の探索を助ける優れたツールの実現が期待されます。
引用: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
キーワード: 空間関係抽出, 地理空間AI, 地理意味論, 中国語テキストマイニング, GIS自動化