Clear Sky Science · ja
タンパク質大規模言語モデルとハイパーグラフ畳み込みネットワークを用いた根関連タンパク質予測
なぜ根とその隠れた助っ人が重要なのか
作物の健康を考えるとき、私たちは葉や果実を思い浮かべがちです。しかし、植物の成功の多くは土の中、目に見えない場所で起きています。そこで働く特別な根関連タンパク質は、植物が水分や栄養を吸収し、干ばつや劣悪な土壌といったストレスに対処するのを助けます。これらの重要なタンパク質を実験室だけで見つけるのは時間と費用がかかります。本研究はHypergraph-Rootと呼ばれる強力な計算モデルを提示し、タンパク質配列を迅速に走査して根関連である可能性の高いものを予測できるようにし、より頑健な作物と高い収量への近道を提供します。
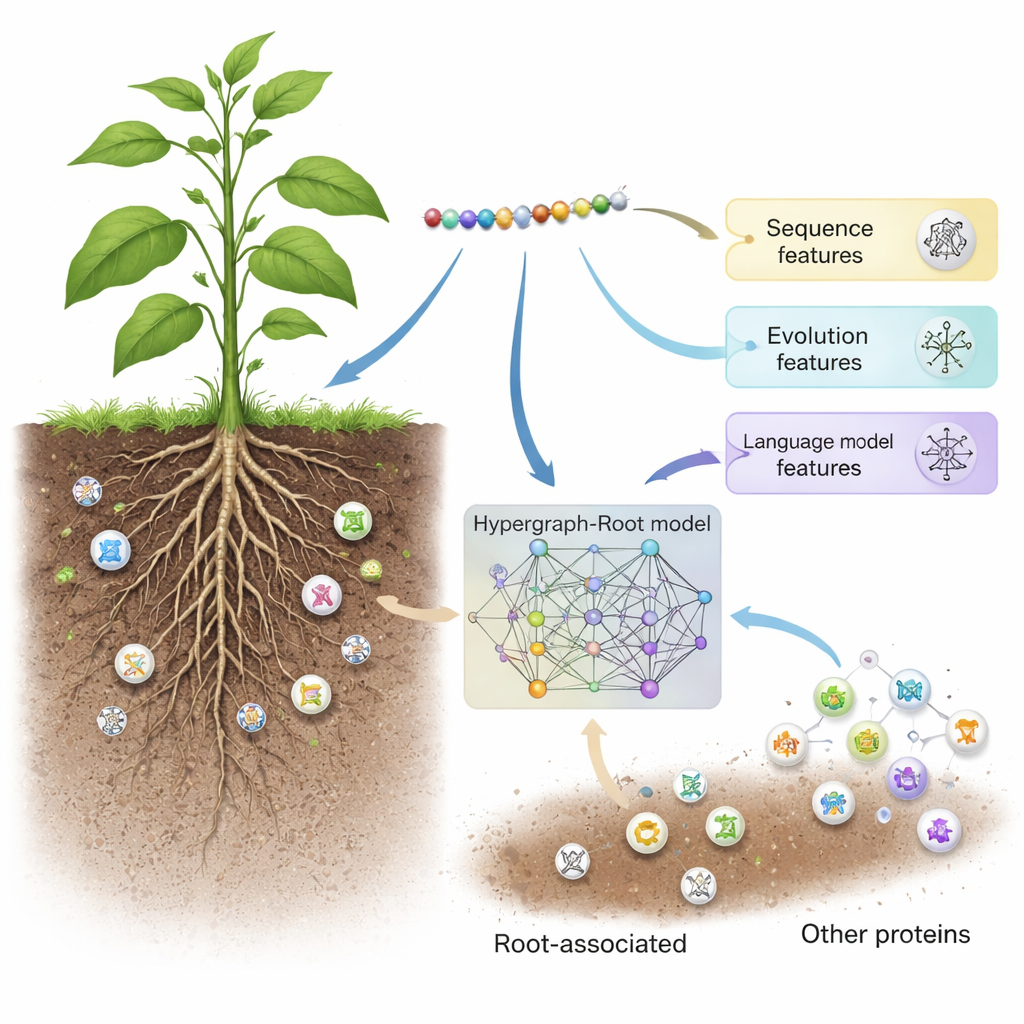
土壌の中の隠れた働き手
植物の根は単に植物を固定するだけではありません。常に周囲を感知し、鉱物を取り込み、有益な土壌微生物とコミュニケーションをとります。根関連タンパク質はこれらすべての中心にあり、根の成長、熱や干ばつ、栄養不足への応答、そして有用な微生物との相互作用を形づくります。これらのタンパク質は収量や回復力に強く影響するため、農家や育種家にとって重要ですが、目に見えないために多くが未発見のままです。従来の方法(プロテオミクスや遺伝子発現解析など)は高価な機器、複雑な解析、手間のかかる実験を必要とするためです。
タンパク質配列を手がかりに変える
タンパク質はアミノ酸の並びから成り、その並びのパターンはしばしばタンパク質の働く場所や機能を示します。これまでの計算モデルはこうしたパターンを利用して根関連タンパク質を見つけようとしましたが、精度は80%未満にとどまっていました。一因はアミノ酸間の関係を比較的単純に、通常はペアとして扱っていたことです。もう一つは配列から抽出する特徴の種類が限られていたことです。著者らは、より豊かな表現とアミノ酸関係のより賢いモデリングがあれば、根機能に関連する微妙なパターンを明らかにできると考えました。
言語とネットワークの手法を取り入れる
Hypergraph-Rootはまず各タンパク質を三つの補完的な方法で記述します。進化に伴うアミノ酸の置換傾向を捉える従来の配列スコアリング法(BLOSUM62や位置特異的スコア行列)を使います。さらに、ProtT5と呼ばれるタンパク質言語モデルからの最新の記述を加えます。ProtT5は数百万のタンパク質配列で訓練されたソフトウェアで、人間の言語で訓練されたテキスト予測エンジンに似た働きをします。ProtT5は各アミノ酸に対して構造や機能に関する手がかりを符号化した豊富な数値的“埋め込み”を生成します。これら三つの視点を合わせることで、本研究の各タンパク質に対して詳細なフィンガープリントが得られます。
タンパク質内部の複雑なつながりを写し取る
単純なペア比較を超えるために、研究者たちはアミノ酸がタンパク質の3次元構造内でどれだけ近いかを予測し、この情報を使ってハイパーグラフを構築しました。ハイパーグラフは単一の結びつきが複数のアミノ酸を同時に結ぶことができるネットワークです。特殊なニューラルネットワークであるハイパーグラフ畳み込みネットワークはこの構造認識型ネットワークを処理し、タンパク質フィンガープリントをより高次の特徴へと洗練します。続いてマルチヘッドアテンションモジュールが、どの部分が根関連の判定に最も有用な信号を持つかを学習します。最後に標準的な分類器がこれらの抽出された特徴を確率スコア(根関連か否か)に変換します。多数の学習試行と、均衡・不均衡のテストセットの両方で、Hypergraph-Rootは精度83%以上、ROC曲線下面積(AUC)約0.9を達成し、従来モデルを明確に上回りました。
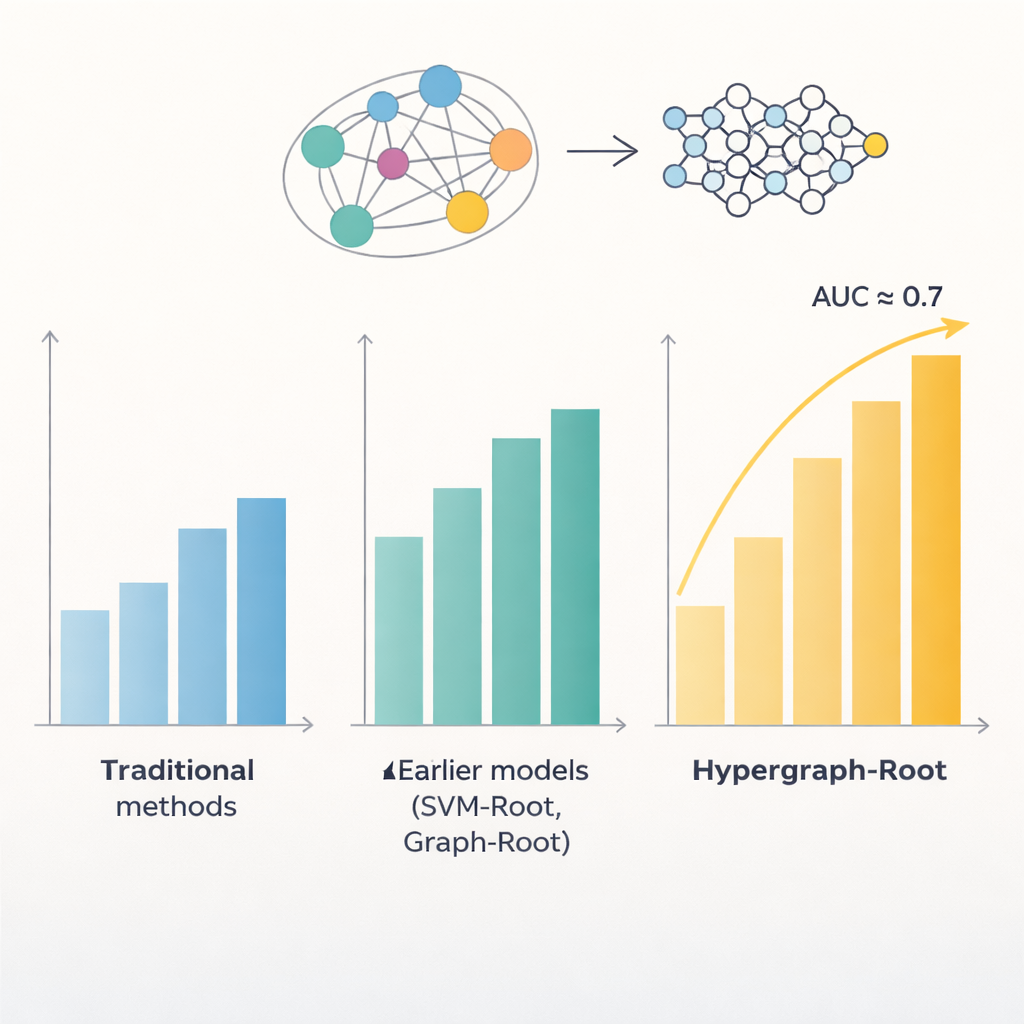
モデルが示すこと、そしてその意義
単なる精度を超えて、モデルはどの情報が重要かについての洞察も提供しました。ProtT5言語モデル由来の特徴は従来の配列・進化的特徴よりも大きく寄与しており、大規模な事前学習済みモデルが従来法では捉えにくい微妙な生物学的信号をとらえられることを示唆します。ハイパーグラフ成分も重要であり、これを取り除くか単純なグラフモデルに置き換えると性能が低下しました。研究者らが従来は根関連としてラベル付けされていなかったタンパク質にHypergraph-Rootを適用したところ、膜輸送や根におけるタンパク質のタグ付けなどの既知の機能から根生物学で役割を果たしていそうな候補がいくつか浮かび上がりました。これらの候補は実験生物学者が実験で検証すべき明確なショートリストを与えます。
賢い予測から強い作物へ
日常的な比喩で言えば、Hypergraph-Rootは植物生物学の専門司書のような存在です。タンパク質の“文字”だけを与えられても、それが根で働く可能性が高いかを推定します。言語モデルの洞察、進化的履歴、複雑な構造的関係を組み合わせることで、過去の予測ツールを大幅に改善しました。実験に取って代わるものではありませんが、数千の候補を扱いやすい少数にまで絞り込むことで時間と費用を節約できます。長期的には、このようなモデルが熱、干ばつ、劣悪な土壌に耐える作物を助ける根関連タンパク質の発見を加速し、変わりゆく気候に対応したより回復力のある農業への重要な一歩となるでしょう。
引用: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
キーワード: 根関連タンパク質, 植物バイオインフォマティクス, ディープラーニング, タンパク質言語モデル, 作物の回復力