Clear Sky Science · ja
否定文に特に着目したハイブリッド深層学習による文類似度スコアの算出
公平な採点には語の意味が重要である理由
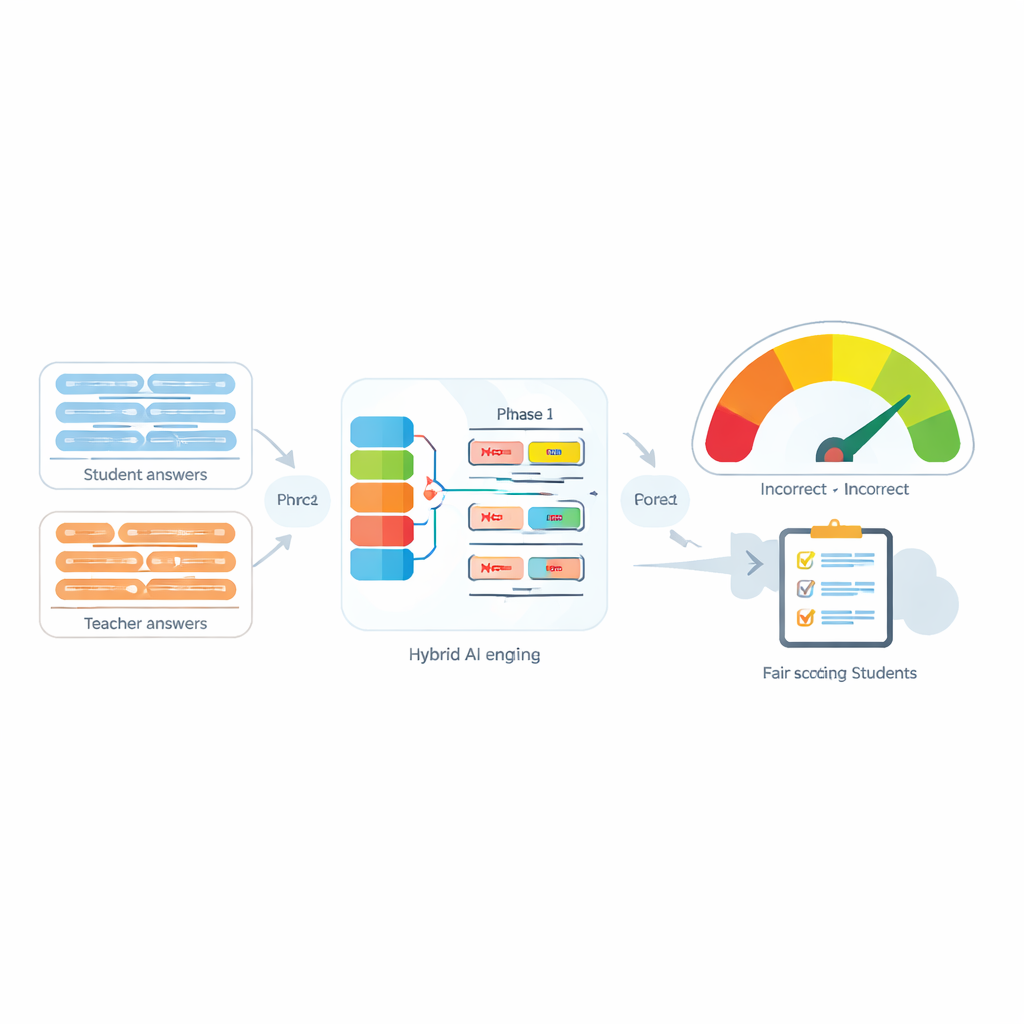
学生が自分の言葉で回答する際、教師の採点を支援するコンピュータは、共有されたキーワード以上のものを理解しなければなりません。「not」のような小さな語が文の意味を逆転させることがあり、自動化されたシステムがその逆転を見落とすと学生は不当に評価される可能性があります。本稿はこの問題に取り組み、否定語が意味をどのように変えるかに特別な注意を払いながら、文の意味を比較する新しい方法を設計しています。
影響の大きい小さな語がもたらす課題
自動評価システムは、教師の負担を軽減するために生徒の解答を模範解答と比較する用途でますます使われています。多くの現代的なツールは各文を数値的な「フィンガープリント」に変換し、そのフィンガープリント間の近さを測ります。否定が含まれない場合、こうした手法は比較的うまく機能しますが、「not」「never」「no」といった語が現れるとしばしば失敗します。たとえば「The method is accurate」と「The method is not accurate」は、意味は正反対であるにもかかわらず、コンピュータ上では驚くほど似ていると判断されることがあります。著者らは、否定語の存在だけでなく、その数や文中での配置が意図された意味を完全に変えることがあると示しています。
微妙さを教えるデータセットの構築
否定を真に理解するシステムを訓練するには、まずこうした厄介なケースを強調するデータが必要でした。著者らはNegation-Sentence-Similarity Datasetを作成し、オペレーティングシステム、データベース、コンピュータネットワーク、機械学習という4つのコンピュータサイエンス領域から合計8,575組の文ペアを収めました。各ペアに対して、人間が否定を考慮した類似度スコアを付与しています。データセットはまた、各文が使用する否定語の数と、単一の「not」、偶数または奇数の否定の数、あるいは「because」や「but」のような接続詞と相互作用するより複雑なパターンといった否定の型も記録しています。この詳細なラベリングは、否定が意味形成に与える影響についてモデルに明示的な手がかりを与えます。
多様な視点を融合するハイブリッドエンジン
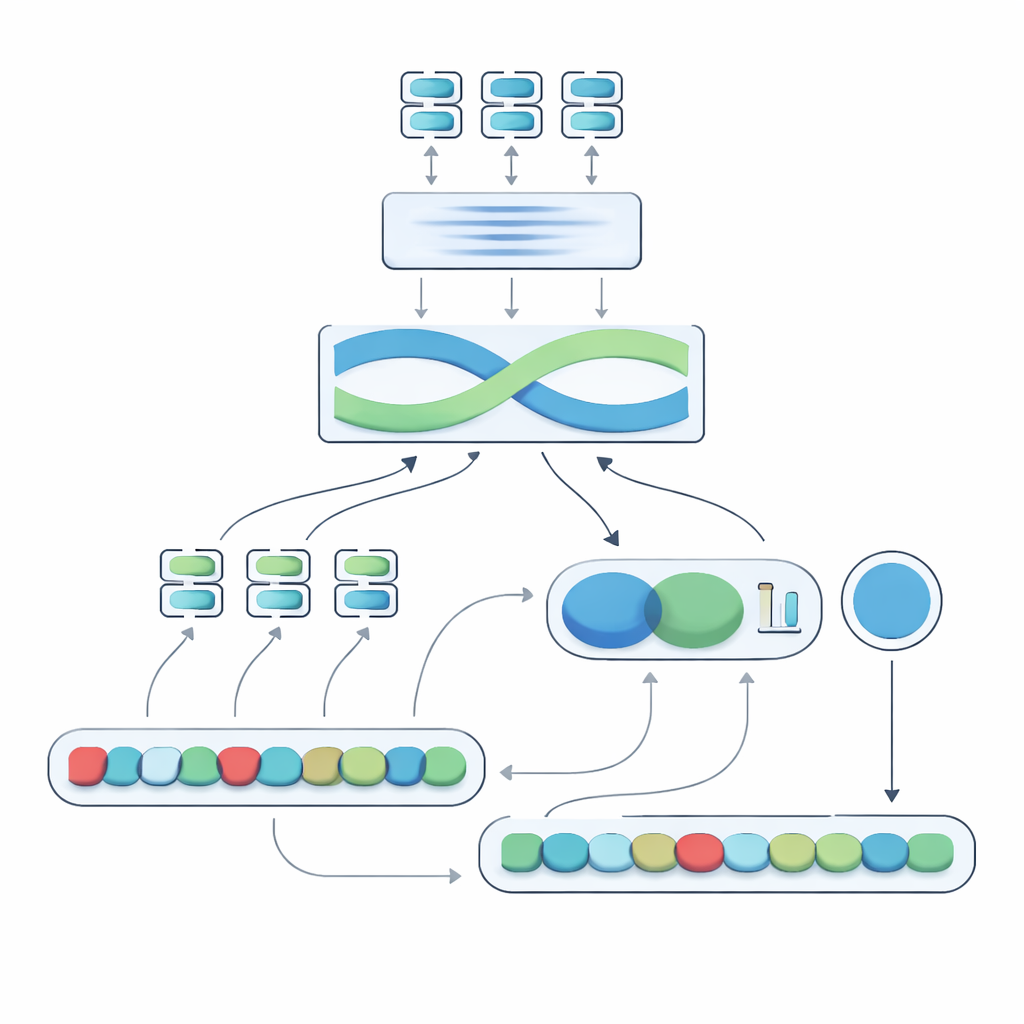
提案システムの中核であるNegation-Aligned Similarity Scorerは二段階のエンジンです。第一段階では、複数の異なる言語モデルに各文を通し、それぞれが意味のわずかに異なる側面を捉えます。それらの出力をつなぎ合わせ、双方向リカレントネットワークに渡して文全体を見渡し、語順や局所文脈を考慮します。これにより、否定語が他の語とどのように位置関係を持つかを含め、微妙な表現により適合した各文のコンパクトな要約が生成されます。
否定の反転を捉えるようモデルを教える
第二段階では、システムは二つの文要約を比較し、否定に関する明示的な情報を付加します。要約の差分や重なり具合を調べ、それらの信号を3つの単純な特徴と組み合わせます:否定語の数の差、否定の数が奇数か偶数か(否定の反転や打ち消しをもたらし得る)、および否定がおおむね対応する位置に現れるかどうか。これらすべての手がかりは小さな予測ネットワークで融合され、0から100の類似度スコアを出力します。キュレーションされたデータセットでエンドツーエンドに訓練することで、このスコアは「not」を単なる別の語として扱うのではなく、否定が意味を再形成する方法に敏感になります。
新しいスコアラーの実際の性能
提案手法を検証するため、著者らは自身のカスタムデータセットと広く使われる文類似度ベンチマークの両方で評価を行いました。標準的手法を用いる強力なトランスフォーマーベースのベースラインと比較して、新しいスコアラーは予測誤差が小さく、分類品質が大きく向上し、F1スコアは約0.97に達しました。注意深く選んだ例では、否定が明確に意味を逆転させる場合には低い類似度を示し、二重否定が実質的に打ち消す場合には高いスコアを与える一方で、競合モデルは依然として類似度を過大評価する傾向があります。アブレーション研究により、列順を認識するリカレント層と明示的な否定特徴という両方が、この性能向上に重要であることが確認されました。
学生と今後のツールへの意味
一般読者への要点は明快です:否定の言い方は重要であり、機械はそれを学習できるということです。複数の言語モデル、文脈処理、そして否定語の単純な数や位置のカウントを融合することで、提案されたスコアラーは二つの文が実際に同じ意味を持つかどうかを判断する際に、より公平で信頼できる方法を提供します。これにより「is not allowed」を「is allowed」と誤って扱うような重大な誤りを自動採点システムが避けられます。手法は計算コストが高く、依然として技術的領域に焦点を当てているものの、日常言語の細かな論理をより良く捉える将来のツールへの道を示しており、自動化された言語技術をより賢明で信頼できるものにします。
引用: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
キーワード: 文の類似度, 言語における否定, 自動採点, 自然言語処理, 深層学習モデル