Clear Sky Science · ja
データ駆動型通信ネットワークでのスケーラブルかつ効率的なルーティングを支える、GPU加速による高性能IP検索
なぜ高速なインターネット回線が重要なのか
あなたが共有する写真やストリーミングする動画、送信するメッセージはいずれもルーターと呼ばれるデジタルの交差点の迷路を通過します。各ルーターは、あらゆるデータパケットを次にどこへ送るかを瞬時に決定しなければなりません。世界的なインターネット利用が急増する中で、これらの判断は1秒間に何十億回と行われており、わずかな遅延でさえ閲覧速度の低下やネットワークの輻輳につながります。本稿は、この判断プロセスで最も時間を要する段階の一つを、ビデオゲームやAIを支えるグラフィックスプロセッサ(GPU)の大規模並列処理能力を活用して高速化し、将来のネットワークを高速かつスケーラブルに保つ手法を探ります。
インターネットの隠れた住所録
すべてのルーターの中核には、フォワーディングテーブルと呼ばれる巨大な住所録があり、IPアドレスの範囲を次の経路(ネクストホップ)に対応付けています。パケットが到着すると、ルーターは「最長一致(longest prefix match)」ルールに従って、宛先に最も適合するエントリを検索する必要があります。従来のソフトウェア的手法はこれらのプレフィックスを木構造に格納し、段階的に辿っていきます。これでも機能しますが、テーブルのエントリ数が数万〜数十万に増えると処理は遅くなり、特に同時に処理できるタスクが限られた汎用プロセッサではメモリ消費も増大します。
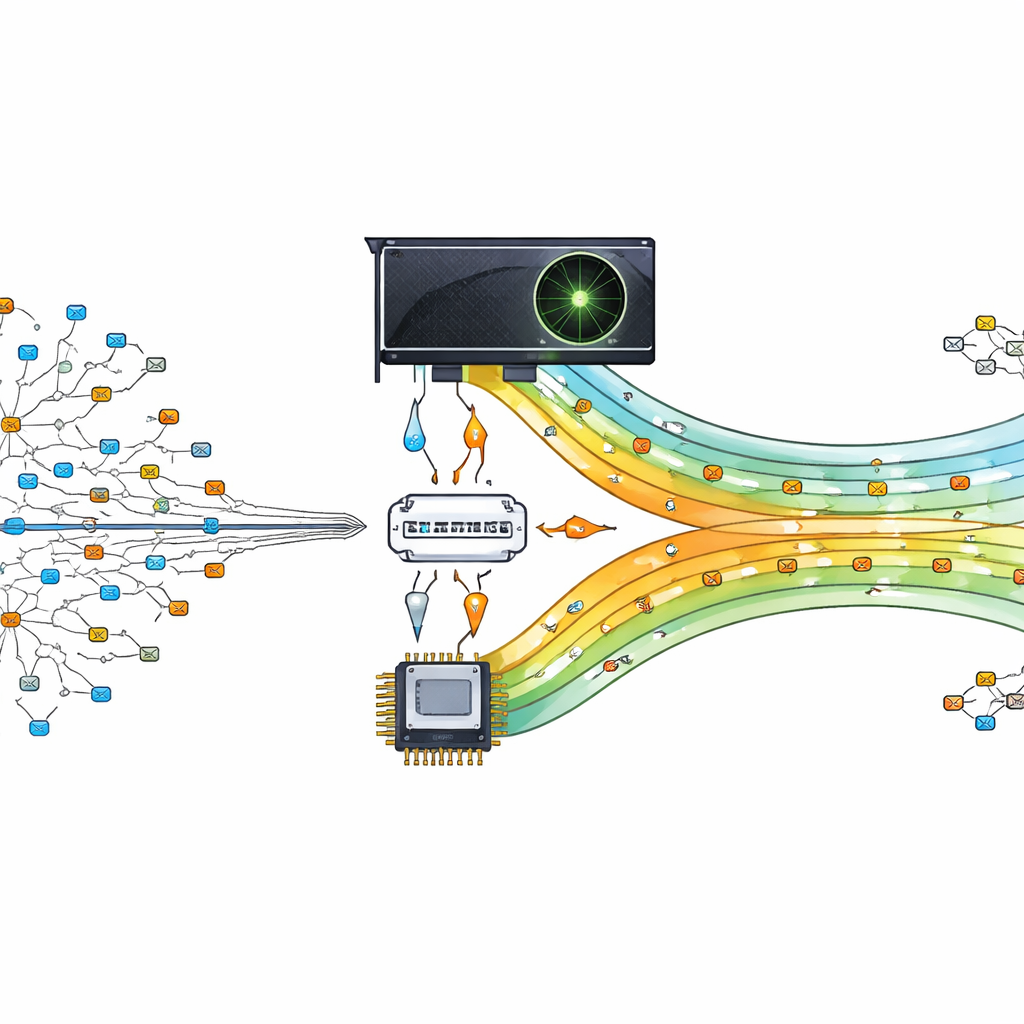
グラフィックスチップを交通整理役に変える
著者らは、この重い検索作業をGPUにオフロードすることを提案します。GPUは数千の小さなタスクを並列に実行するよう設計されたチップです。彼らの設計では、GPUはメインプロセッサの補助役として扱われます。中央プロセッサはルーティングテーブルを準備・整理し、圧縮したコンパクトなデータをGPUに送ります。パケットが到着すると、その宛先アドレスは分割されGPUに渡され、数多くのスレッドが同時に最適な一致を探索します。数百〜数千の検索を並行して行うことで、ルーターは現代のデータ駆動型通信需要に追従できます。
検索を加速するためのアドレス短縮
本研究の重要な洞察は、短いアドレスの方が検索が速いという点です。生のIPアドレスをそのまま使う代わりに、著者らは可逆圧縮であるハフマン符号化を用いてアドレスを圧縮し、頻出するアドレスパターンに短いコードを割り当てます。これにより各エントリを表現する平均ビット数が減り、メモリ使用量と基底となる探索構造の高さを削減できます。さらにプレフィックスを一度に複数ビットずつ調べる「マルチビット」木に格納し、ステップ数をさらに減らします。GPUの特性に合わせて、この木構造を単純な一次元配列に変換し、複雑なポインタ追跡を規則的なインデックス計算に置き換えることで、数千のスレッドが効率的に処理できるようにしています。
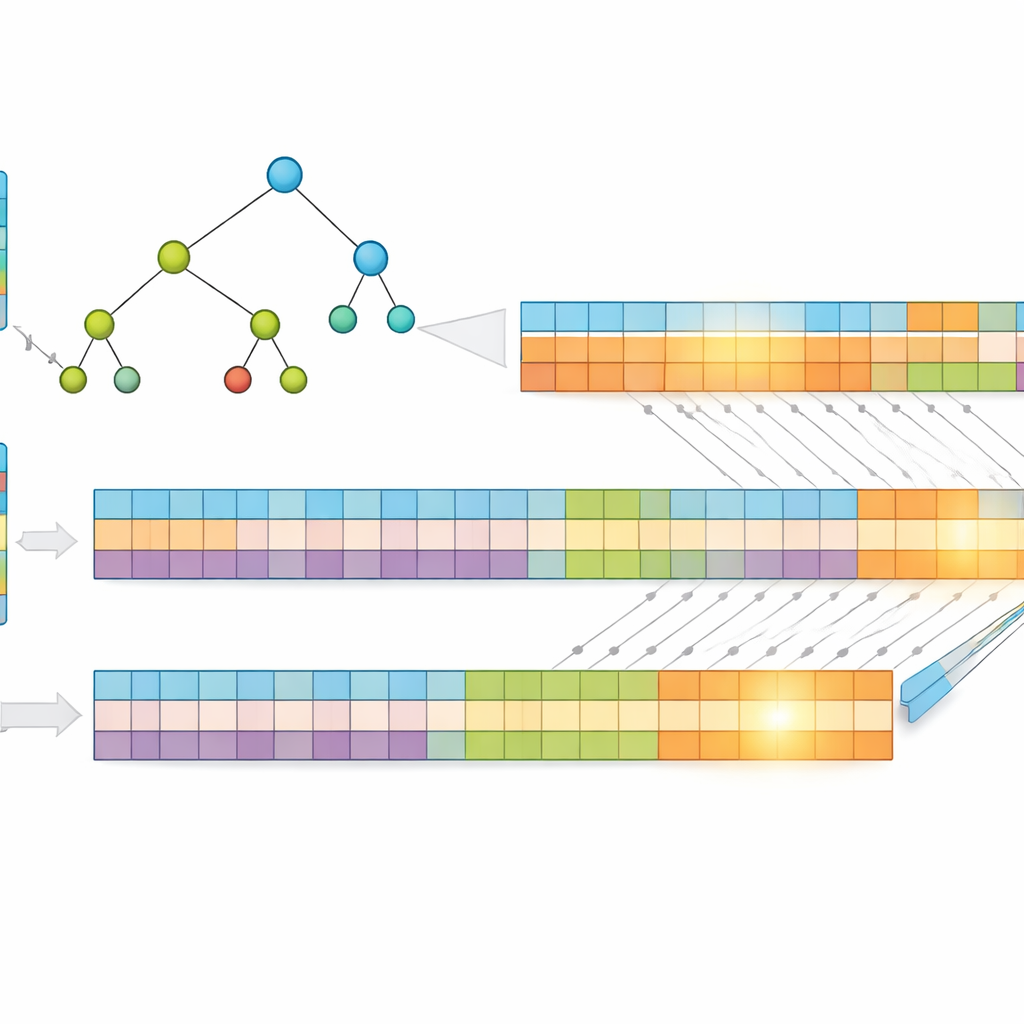
大規模並列処理のための問題分割
性能をさらに押し上げるために、研究者たちは圧縮された各アドレスを等しい2つの半分に分割し、前半用と後半用の2つの独立した木を構築します。パケットが到着すると、GPUは両方の木を並列に検索します。それぞれの検索は小さな候補集合を返し、最終的な答えはこれらの集合の交差を取ることで共有される最も具体的なプレフィックスを見つけます。作業が分割され同時に処理されるため、所要時間は主に最大プレフィックス長と1ステップで検査するビット数に依存し、テーブル内のエントリ数にはほとんど影響されません。実際のインターネットのルーティングデータを用いたテストでは、テーブルが大きくなってもほぼ一定の検索時間を維持することが示されました。
実験が示すもの
チームは自分たちのGPUベース手法を、古典的な二分木、圧縮木、ハッシュ法や二分探索木などの既存のGPU加速スキームを含む複数のよく知られた手法と比較しました。実ルーティングデータセット上では、彼らのシステムは大幅な性能向上を示しました:代表的な汎用プロセッサベースの木構造法に対して約83~91%の高速化、以前のGPU手法に対して約89~97%の高速化を達成しました。圧縮により平均で約3分の1ほどメモリ使用量が削減され、限られたオンチップメモリへの負担を軽減するとともにGPUの探索構造を浅く効率的に保ちました。重要なのは、手法の性能がルーティングテーブルのサイズに対して安定していたことであり、成長するネットワークに対する適応性を裏付けています。
一般利用者にとっての意味
専門外の読者にとっての結論は、著者らがグラフィックスチップをインターネットデータの高効率な交通整理役に変える方法を示したという点です。アドレス情報の賢い圧縮と分割、より効率的な木の配置、そして大規模並列探索を組み合わせることで、既存の多くの手法よりもはるかに速く各パケットの最適経路を見つけられ、アドレス帳が拡大しても速度が落ちにくくなります。本研究は主に現行のアドレス体系で示されていますが、同じ考え方は将来のより大きなアドレス空間にも拡張でき、データ需要が増え続ける中でオンラインサービスの応答性を保つのに貢献する可能性があります。
引用: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
キーワード: GPUルーティング, IP検索, ネットワークのスケーラビリティ, パケット転送, 並列計算