Clear Sky Science · ja
配列、構造、結合親和性データを含む抗体およびナノボディ設計の統合データセット
小さな免疫ツールとビッグデータが重要な理由
抗体とその小型版であるナノボディは、感染症やがんに対する体の精密誘導ミサイルのような存在です。薬剤開発者は今やこれらの分子を、航空機を設計する技術者のようにコンピュータ上で設計しようとしています。しかしこれまで、人工知能による設計の原材料となる――抗体の構成要素、立体構造、標的への結合の強さに関する信頼できるデータ――は、互換性のない多くのデータベースに分散していました。本稿は、研究者が次世代の標的治療薬を設計するために必要な、洗練され包括的なデータを提供する目的で構築された公開の統合資源、Antibody and Nanobody Design Dataset(ANDD)を紹介します。
生物学的な鍵と鍵穴からデジタルな設計図へ
抗体は大きなY字型タンパク質であり、ナノボディはリャマやアルパカなどの動物に見られるずっと小さな単一鎖のバージョンです。いずれもウイルスやがん細胞、その他疾患関連タンパク質上の特定の「鍵穴」を認識します。コンピュータモデルがこの認識の仕組みを学習するには、多数の例について四種類の情報が必要です:アミノ酸配列(部品表)、三次元構造(形状)、抗原(標的)、および結合の強さ(二者がどれだけ強く結合するか)。これまでは多くの資源がこれらの要素の一つか二つしか捕捉しておらず、研究者はデータベース間を飛び回って手作業で詰め合わせる必要があり、進展が遅れ誤りが生じやすくなっていました。
散在する断片を一つの整理されたライブラリに集約
ANDDのチームは、専用の抗体・ナノボディデータベース、一般的なタンパク質リポジトリ、さらには特許文書を含む15の主要ソースからデータを収集しました。これらの生データは入念に組まれたパイプラインを通じて処理されます:ダウンロード、共通スキーマへの再フォーマット、識別子の突合、重複の除去、命名規則の整合化。データベース間で矛盾があった場合は、キュレーションされた情報や直接実験結果が優先されます。最終的に得られるのは、配列、構造、標的、結合情報を一貫性を持って結びつける単一の表と構造ファイル群であり、各レコードには出典と処理履歴をたどれるタグが付与されています。
研究ニーズに合わせた階層的な詳細度
ANDDの各エントリが同じだけの情報量を持つわけではないため、著者らは詳細度の段階に沿ってコレクションを整理しました。最も広いレベルでは、配列情報を持つ48,683件の抗体およびナノボディのエントリがあります。大きなサブセットは三次元構造を追加し、さらに小さなサブセットは標的タンパク質の配列も含みます。最も詳細な層――数千件規模――は測定または予測された結合強度を含みます。例えば抗体では、18,464件が配列を有し、同数が配列と構造を併せ持ち、8,000件超が抗原配列も含み、7,737件が配列・構造・抗原・親和性の全情報を備えています。ナノボディにも並行した階層が存在し、実験者とモデル構築者の双方に柔軟性を与えます:大規模で単純なデータセットを選ぶことも、情報量の多い小規模なサブセットを選ぶことも可能です。
結合強度の不足を埋める
結合強度は薬剤設計にとって重要ですが、実験値は希少で報告が不均一です。このギャップに対処するため、著者らはデータと予測の区別を曖昧にしない方針で、構造はあるが測定値がないエントリに対してのみ、専門の深層学習ツールANTIPASTIを用いて結合強度を推定しました。こうして得られた2,271件の予測値は明確にラベル付けされ、約7,000件の実験的に測定された値とは別に管理されています。チームは別のモデルであるAlphaBindや結合に関する数学的に関連する指標との比較を用いて整合性を確認しました。強い相関と低い誤差は、キュレーションされた実験値が信頼できること、また予測値が合理的な傾向に従っているが真実と同一視されるべきではないことを示唆しました。
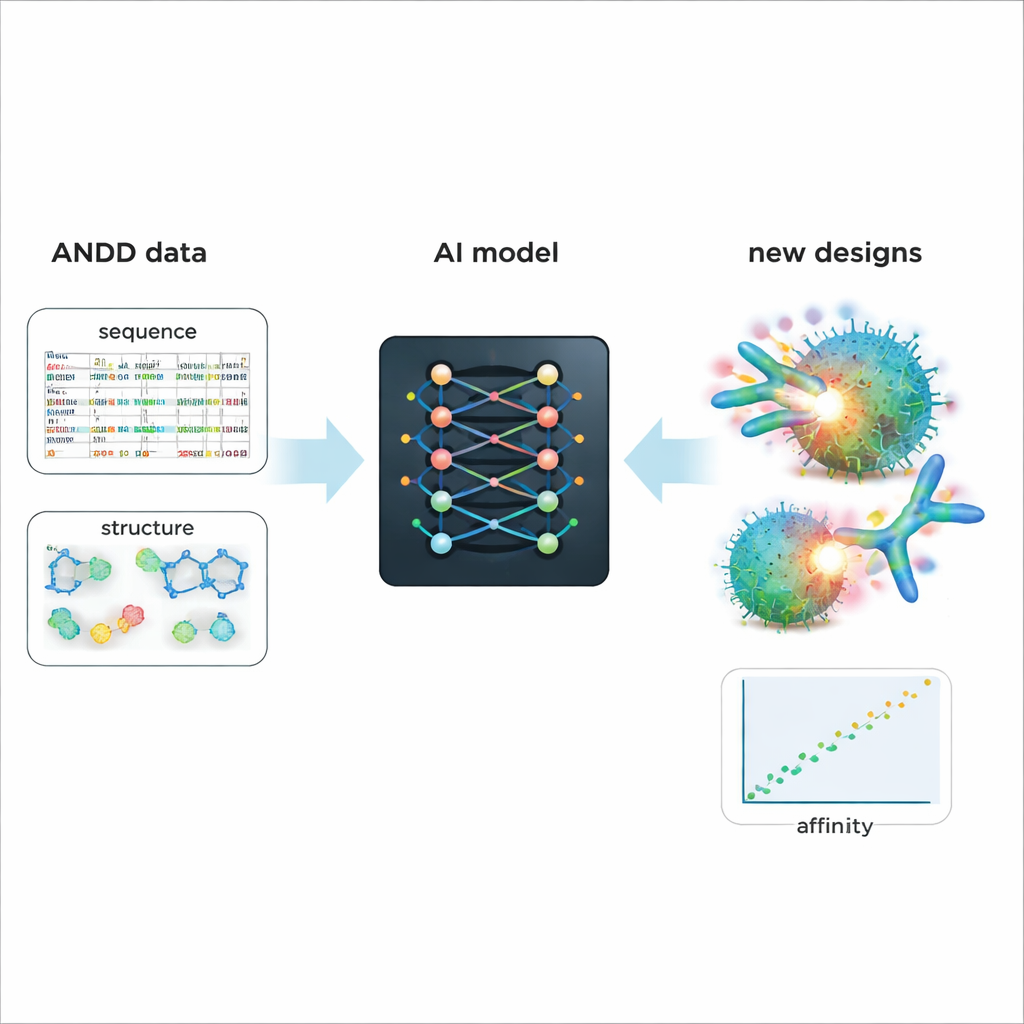
将来の医薬品設計を賢くする原動力
ANDDの実用性を示すために、著者らは既存の抗体・ナノボディ設計用の生成AIモデルをファインチューニングしました。ANDDの配列、構造、標的、親和性情報で訓練したところ、古い単純なデータで訓練したベースラインモデルに比べ、より良好な予測結合とより現実的な立体形状を備えた分子が生成されました。この事例研究を越えて、ANDDは寛容なライセンスの下で公開され、完全なドキュメントと再現可能なビルドパイプラインを備え、定期的に更新されるよう設計されています。専門外の読者にとっての要点は、ANDDがばらばらで雑然とした抗体データの寄せ集めを一貫性があり信頼できるライブラリに変え、AIツールに対して正確で効果的な生物学的医薬品を設計するためのはるかに良い出発点を提供する、ということです。
引用: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
キーワード: 抗体設計, ナノボディ, 結合親和性, 生物学的治療薬, AI 医薬品探索