Clear Sky Science · ja
再現可能な三倍体 de novo ゲノムアセンブリのための最小仮想データセット
なぜ三コピーゲノムが重要なのか
多くの作物や他の生物はヒトのように各染色体を2コピーだけ持つわけではなく、3コピー以上を持つことがあります。配列が非常に似ているが完全に同一ではないため、これらの余分なコピーを配列解析データから組み立てるのは意外に難しい。本稿は、研究者が現実的な三コピー(3倍体)問題を既知かつ再現可能な条件でテスト・比較できる、小規模だが慎重に設計された「仮想」データセットを紹介します。
単純な代用ゲノムの構築
実際の植物や動物から始める代わりに、著者はまず100万塩基長のランダムなDNA配列をきれいなテンプレートとして作成します。このテンプレートを三つの別個のバージョンに複製し、三倍体生物の三つの染色体セットを模します。実際のゲノムが時間とともにゆっくり変化する様子を模倣するために、本研究では各コピーに小さな変化―一塩基置換―を一定数ずつ段階的に導入します。この操作を100ステップ繰り返すことで、ほとんど同一に近いものから明確だが中程度の差異を持つものまでの三つ組のゲノムが得られます。この制御された「発散グラデーション」がベンチマークの基盤です。
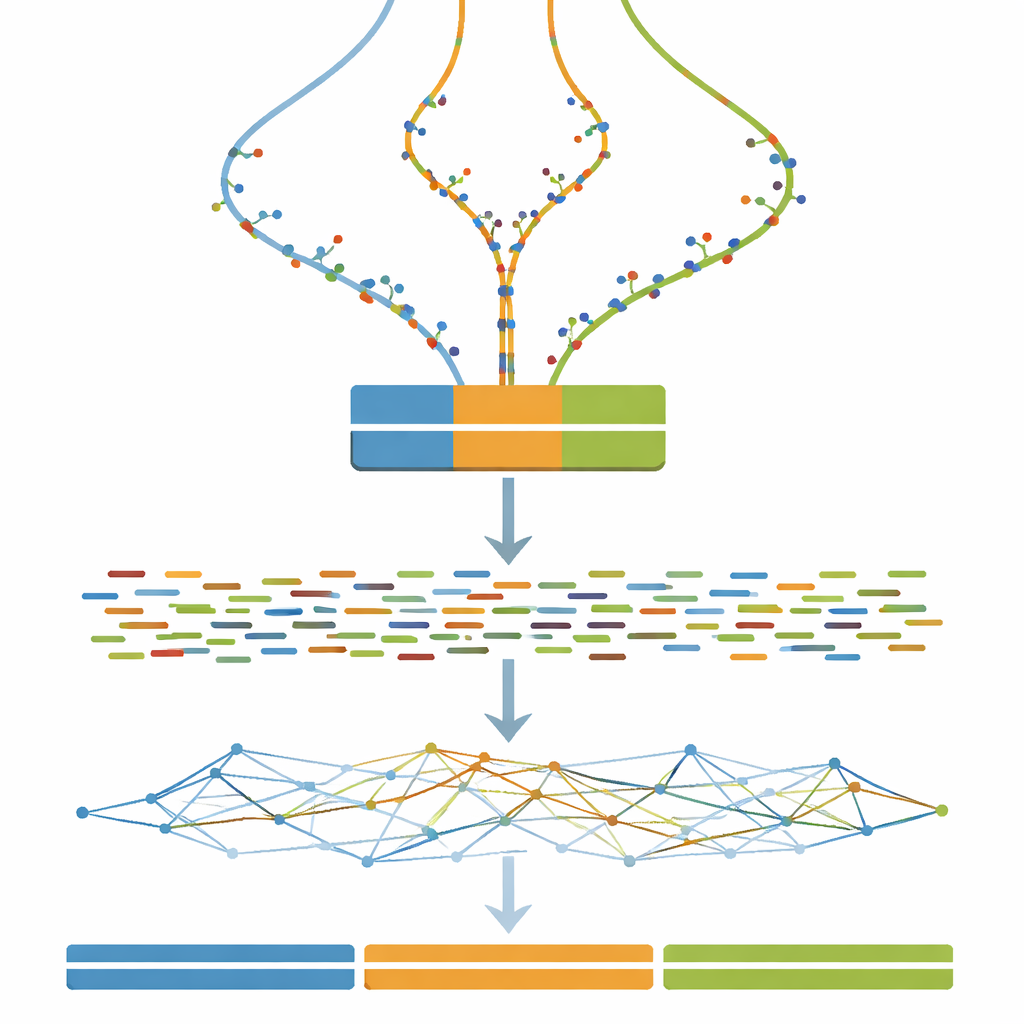
仮想ゲノムを仮想実験へ変換する
各三コピーゲノムを定義したら、次にDNAシーケンサーが実際に見るであろうデータを模倣します。本研究では広く使われているソフトウェアを用いて、Illuminaシーケンサーが生成するような短いペアードフラグメントを一定かつ比較的高いカバレッジでシミュレートします。ランダムなシーケンス誤りの修正や重複するリードペアのマージなど、一般的な前処理を模したオプションのクリーンアップ手順も含めることができます。したがって、このデータセットを用いることで、アセンブリアルゴリズム自体だけでなく、典型的な前処理の選択が最終的な組み立て結果に与える影響も評価できます。
アセンブリ戦略のストレステスト
本研究の核は、シミュレートされたすべてのリードを単一のゲノムアセンブリプログラムに投入し、変更するのはただ一つの重要な設定のみ―k-mer サイズ―という大規模な実験です。k-mer サイズは、ゲノムを再構築する際にソフトウェアがリードをどれだけ細かく「塊」にするかを制御するパラメータです。発散レベル(0から100ステップ)とk-mer サイズ(幅広い奇数値)の全ての組み合わせについて、毎回新しいアセンブリを構築します。付随する評価ツールは、組み立てられた断片の連続性、断片数、およびそれらの総長が既知の300万塩基の真実とどれだけ一致するかを測定します。これらの測定結果はヒートマップとして要約され、異なるコピーが一つに潰れてしまう領域、非常に小さな断片に分裂する領域、あるいは三つの長く正確なコンティグに近づく領域が広く可視化されます。
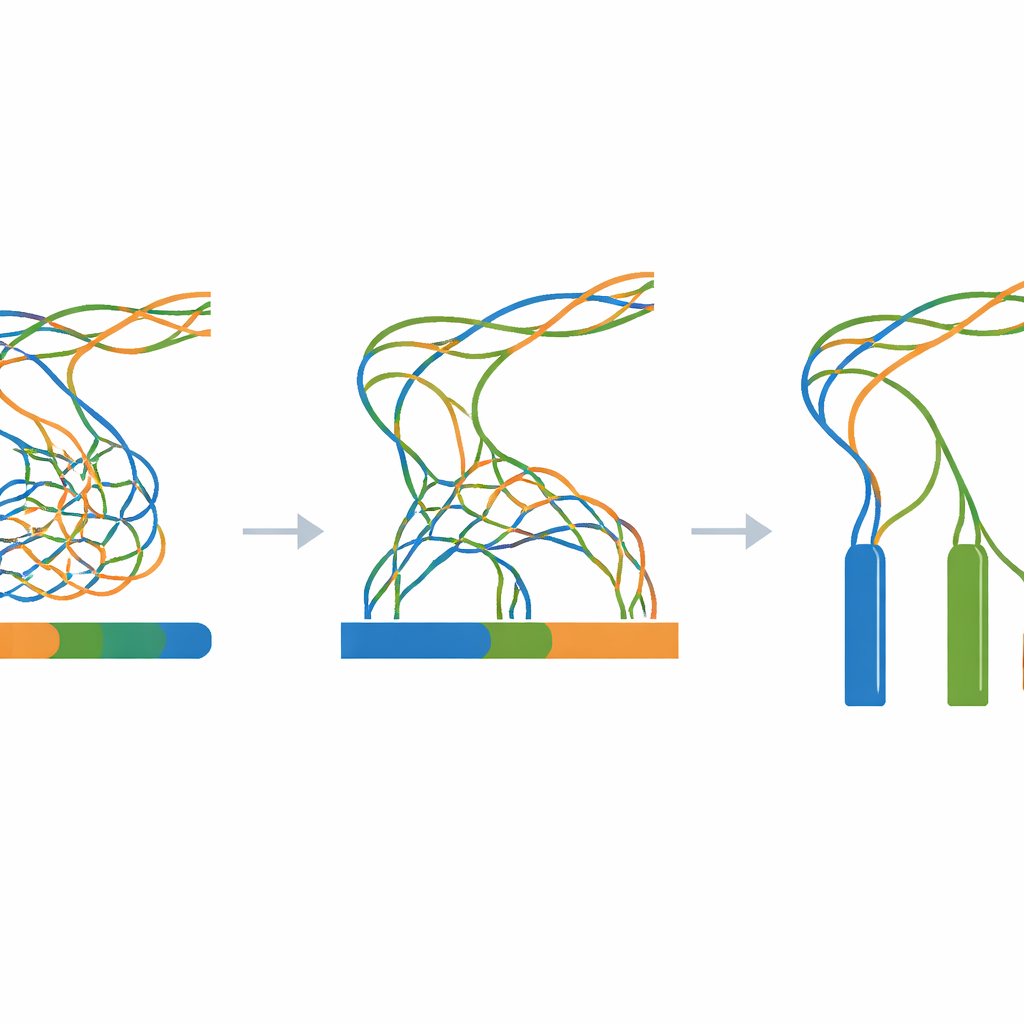
難しいゲノムのための透明なリファレンス
初期のランダムテンプレートから最終的なアセンブリに至るまで、すべての段階が合成的かつスクリプト化されているため、研究者はオープンソースツールのみで標準的なLinuxコンピュータ上に同じワークフローを再現できます。論文にリンクされたZenodoアーカイブにはテンプレートゲノム、すべての中間変異配列、すべてのシミュレートリード、および各アセンブリ結果に加え、ログや簡単な補助スクリプトが含まれています。技術的な検査により、変異付加プロセスが期待どおりに動作していること、シミュレートリードが要求された長さとカバレッジに一致していること、そしてアセンブリが予想されるパターン―三つのコピーがほとんど同一の場合の強い過剰収束と、離れるにつれてより明瞭な分離―を示すことが確認されています。
平易な言葉で言うと何を意味するのか
平易に言えば、本稿はシャッフルされた断片の山から三つの似た説明書を再構築しようとするソフトウェアのための管理されたテストコースを提供します。三冊の説明書の違いを段階的に増し、再構築過程の重要な設定を体系的に変えることで、このデータセットは現行手法がいつどのように失敗または成功するかを明らかにします。開発者は新しいアルゴリズムを調整するためにこれを利用でき、利用者は三倍体ゲノムに対してどの設定が最適かをよりよく理解できます。DNA自体は人工的であっても、収束、分離、およびパラメータ選択の影響に関するここから得られる教訓は、多くの重要な種の複雑なゲノムを解読する実世界の取り組みに直接関係しています。
引用: Ootsuki, R. Minimum virtual dataset for reproducible triploid de novo genome assembly. Sci Data 13, 382 (2026). https://doi.org/10.1038/s41597-026-06779-2
キーワード: 三倍体ゲノムアセンブリ, 多倍体ベンチマーキング, 合成DNAデータセット, de novo アセンブリ, k-mer 最適化