Clear Sky Science · ja
StatLLM: 統計解析における大規模言語モデルの性能を評価するためのデータセット
日常的なデータ利用者にとっての重要性
チャット型アシスタントのような人工知能ツールが日常業務に組み込まれるにつれて、より多くの人が数値処理、実験の実行、データ分析をAIに任せるようになっています。しかし、例えば新しい医療処置の有効性を検証したり学校の成績データを調べたりするときに、AIが統計研究のためのコードを書いた場合、それが正しく仕事を遂行したかどうかはどう判断すればよいでしょうか。本論文はStatLLMを紹介します。これは大規模言語モデルが実際の統計解析タスクをどれだけ適切に扱えるかを検証するための公開データセットであり、研究者や実務家に対してAIが書いたコードをいつ信頼できるか、いつ注意が必要かをより明確に示します。
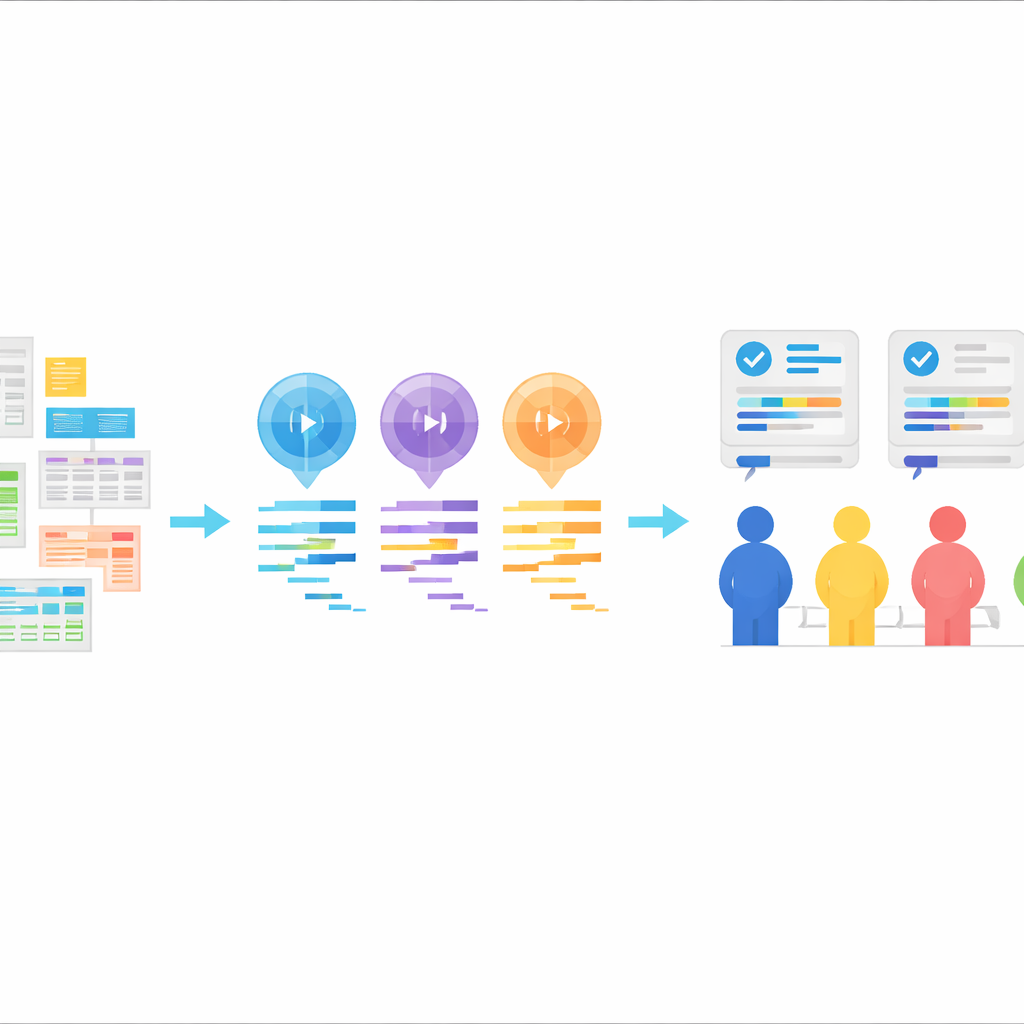
AIが書く統計コードのための新たなテストベッド
StatLLMの中核は、教育、医療、ビジネス、金融、工学、スポーツなどの分野から集めた65の実データセットから作成した207の統計解析タスクの慎重なコレクションです。各タスクには平易な言葉による問題説明、データセットと変数の詳細な説明、そして人間の専門家が作成・検証した短いSASコードが付属します。タスクは、単純なデータ要約やグラフから回帰分析、生存時間解析、より高度な手法に至るまで、統計を学ぶ学部上位〜修士レベルの学習範囲をカバーしています。これにより、AIツールが実務的な問いを理解し、それを妥当な解析手順に翻訳できるかどうかを、現実的で教育現場・業界に即した形で検証できます。
AIにコードを書かせ、その成果を採点する
著者らはこれらのタスクを使い、三つの大規模言語モデル—GPT-3.5、GPT-4、および Llama‑3.1 70B—にSASコードを生成させました。各モデルには同じ材料が与えられました:タスクの説明、データセットの説明、実際のデータファイル、そしてSASコードを生成する明示的な指示です。モデルは「ゼロショット」方式で使用され、事前に正しいSASコードの例は示されませんでした。応答は説明を取り除いてコードだけが残るように整形されました。この設定は、ユーザーが欲しいことを説明し、AIがコードを返し、そのコードを統計ソフトで実行するという一般的な現実世界のパターンを模しています。
人間の専門家をゴールドスタンダードに
AIが書いたコードの実力を評価するために、チームは厳格な人間によるレビューを組織しました。9名の経験豊富なSASユーザーが3つのグループを形成し、それぞれコードの論理的正しさと可読性、実行時のエラーの有無、出力が元の質問に対して明確かつ正確に答えているか、という性能の一側面に焦点を当てました。各タスクについて、3モデルからのSASプログラムはシャッフルされ、評価者がどのモデルがどのコードを生成したか分からないようにしました。スコアは5段階で付けられ、合算して総合評価とし、数百のモデル–タスクの組合せについて長所と短所の微妙な違いを浮き彫りにしています。これらの専門家による評価は、StatLLMデータセット内のすべてのコードとタスクに付随しています。
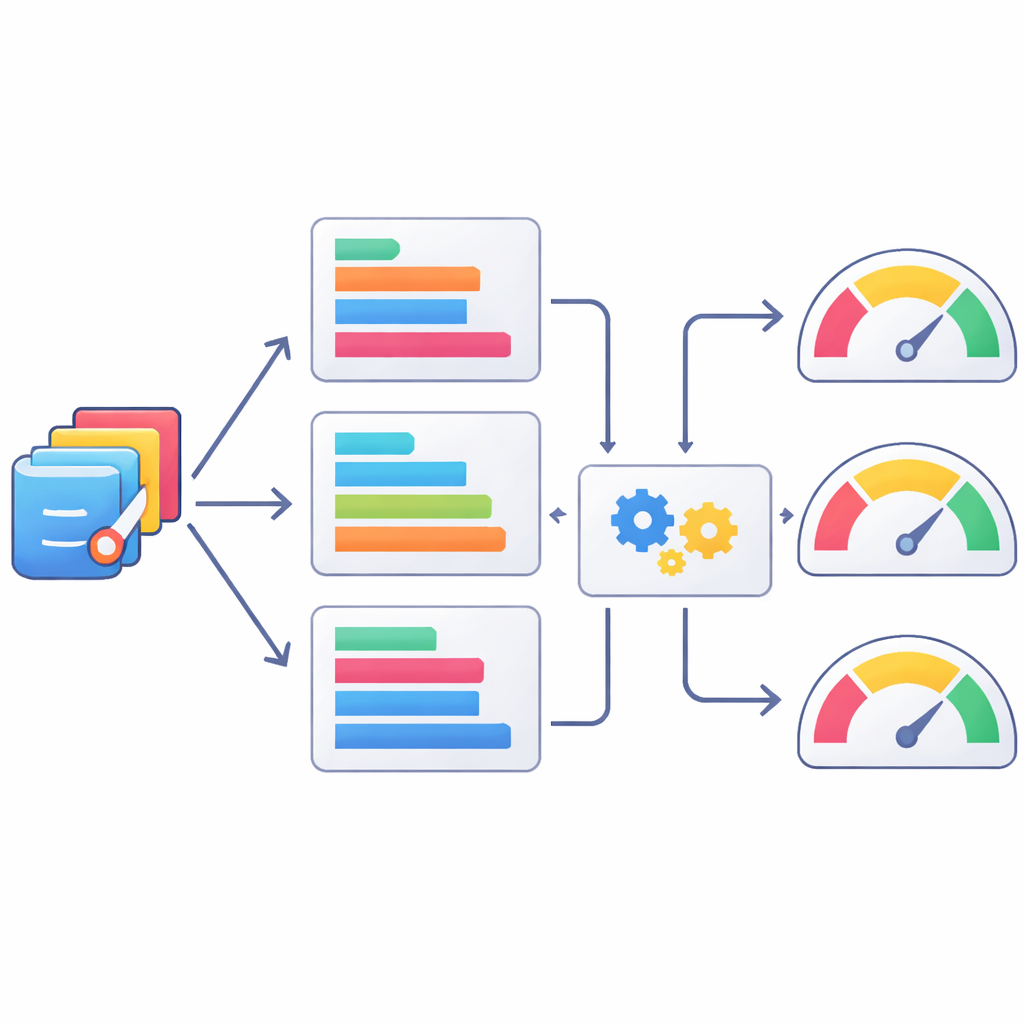
人間のようにコードを評価する機械を育てる
人手によるレビューは時間と費用がかかるため、著者らは自動のテキストベース指標が統計コードの品質判定の粗い代替になり得るかも調べました。彼らはAI生成のSASプログラムと人間が検証したバージョンを、よく知られた自然言語処理の指標群で比較し、これらのスコアが人間の評価とどの程度一致するかを確認しました。短いトークン列の重複を追うROUGEの変種のような一部の指標は人間の判断と比較的高い相関を示しましたが、全体としては中程度の一致にとどまりました。さらに一歩進めて、これらの指標の組合せから人間のスコアを予測する機械学習モデルを訓練しました。XGBoostのような手法は人間評価との一致を改善しましたが、それでも専門家の判断を完全に再現するには遠く及ばず、自動スコアがあくまで部分的な代理にすぎないことを示しています。
将来のAI駆動統計ツールに向けて構築する
ベンチマーク提供にとどまらず、著者らはStatLLMが新しいツールや研究方向を支える方法も示しています。各タスクは一般的な形で記述されているため、同じ問題セットをRやPythonなど他言語でのコード生成のテストに用いることや、複数言語のコードを組み合わせる用途にも使えます。論文は信頼性向上のために異なるAI生成解を混ぜるアンサンブルアプローチを取り上げ、ユーザーがデータセットとタスク記述をアップロードするとAIが自動でRコードを生成・実行するプロトタイプのR Shinyアプリを実演しています。StatLLMは自然言語の指示を理解しつつ明確で計測可能な基準に基づいて評価される次世代の統計ソフトウェアを設計・検証するためのプラットフォームにもなります。
データ分析におけるAI利用の意味
非専門家に向けた主要な結論は、AIは短い統計コードの断片を既に書けるが、特に単純な例を超えるタスクでは信頼性が保証されているわけではない、ということです。StatLLMは異なるモデルがどの程度の性能を示すかを透明かつ再利用可能な方法で示し、生成コードの自動チェックを改善し、安全で堅牢なデータ分析ツールを設計するのに役立ちます。新しい言語モデルが登場するたびにこれを生きたベンチマークに差し替えて評価できるため、AIが真剣な統計業務で何ができ、何がまだできないかを公正に保つ手段となります。
引用: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
キーワード: 大規模言語モデル, 統計解析, コード評価, ベンチマークデータセット, SASプログラミング