Clear Sky Science · ja
注釈付き臨床試験コーパスを用いたトランスフォーマー基盤の関係抽出と概念正規化
医師が適切な患者をより速く見つけられるように
すべての臨床試験は、長い条件一覧に合致する患者を見つけることに依存しています。年齢制限、既往歴、検査結果、治療歴、期間などが含まれます。現在、医師は電子カルテや試験記述を手作業で読み比べることが多く、それは遅くミスが起きやすい作業です。本稿は、スペイン語の臨床試験テキストを大規模かつ入念に検証したコレクションを提示し、最新の人工知能がその非構造化された言語を整理されたデータに変換する方法を示します。これにより、より迅速で公正かつ正確な医療研究への道が開かれます。
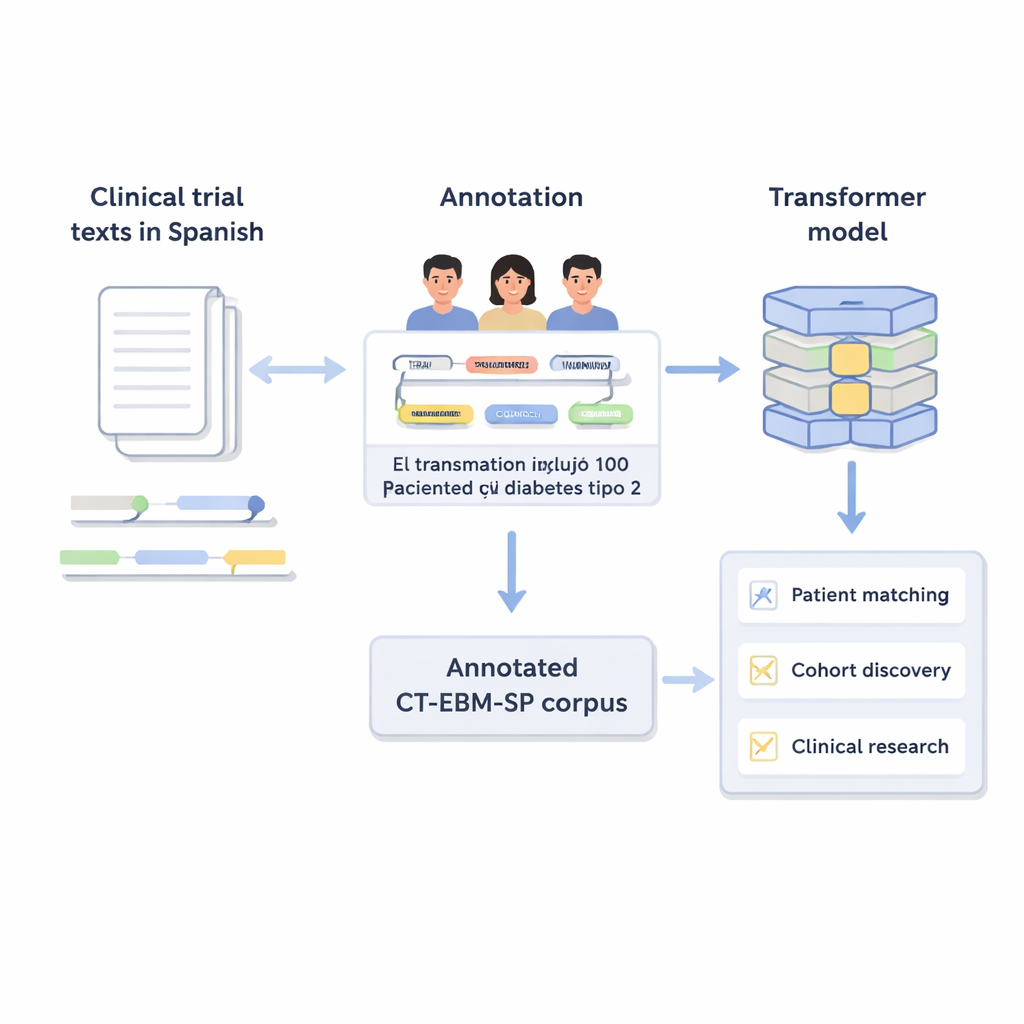
自由記述を構造化情報に変える
臨床試験では、参加可能かどうかを日常的な医療用語で記述します:年齢制限、既往症、検査値、試した治療などです。コンピュータはこの種の自由記述の処理に苦労します。著者らはCT‑EBM‑SPコーパスのバージョン3を作成しました。これは1,200件のスペイン語臨床試験テキスト、約30万語を含むデータセットです。専門家がこれらのテキストを精査し、疾患、薬剤、検査結果、時間表現など23種類の医療エンティティと、「既往なし」などの否定や不確実性を示す手がかりを注釈しました。また、事象が過去か未来か、患者本人か家族かといった詳細を示す11の属性もラベル付けしています。
医療用語を同じ言語にそろえる
医学の大きな課題は、同じ概念が多様な書き方で表されることです。これを解決するために、著者らは注釈されたエンティティの大部分をUMLS(統一医療用語システム)という巨大な多言語医療辞書の標準化コードに結び付けました。この工程を概念正規化と呼び、異なるつづりや表現が同一の一意の識別子を指すようにします。たとえば「25‑ヒドロキシビタミンD」の複数の表記が単一のUMLS概念にマップされます。コーパス全体では8万7千件を超えるエンティティと6万8千件以上の関係が含まれ、約82%のエンティティが正規化に成功しました。2人の専門家が独立してこれらの対応を確認し、高い一致率を示したため、注釈の信頼性が高いことがわかります。
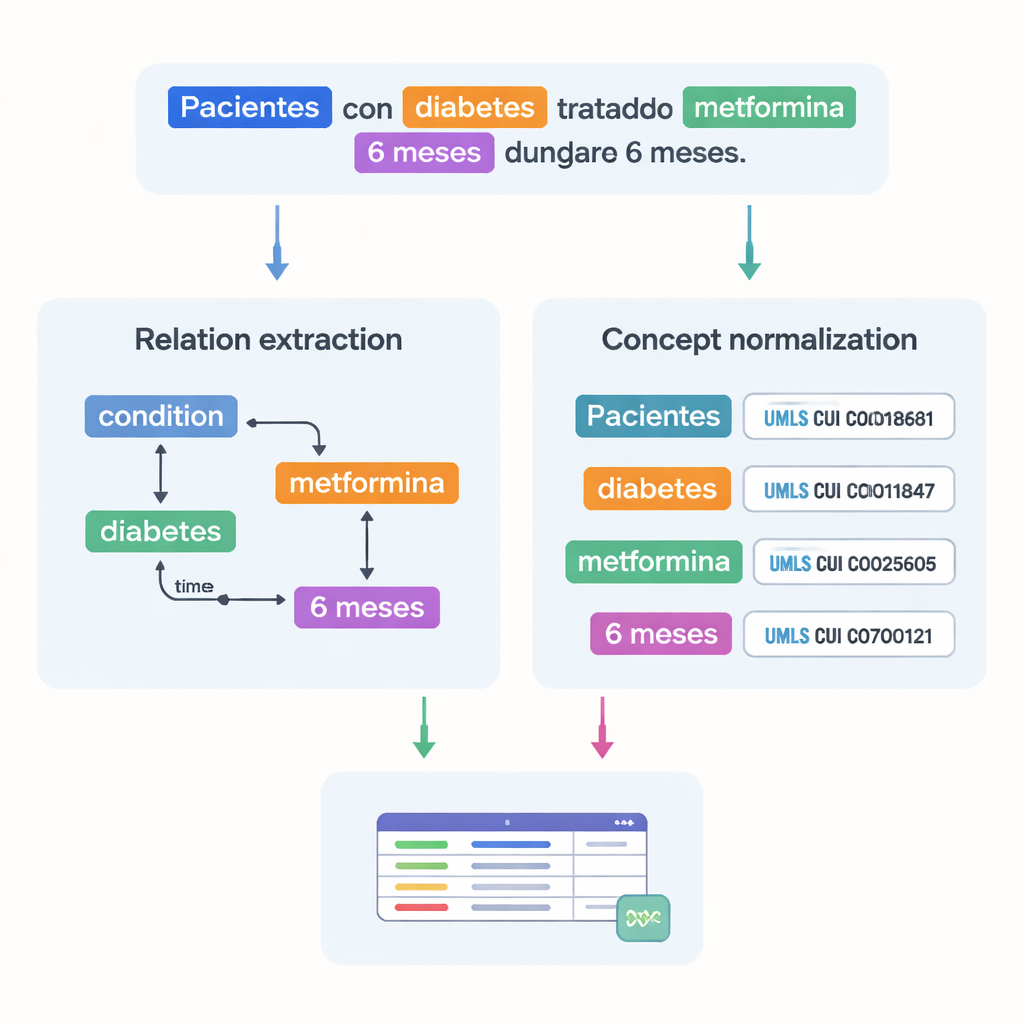
医療事実の関係性を捉える
単に医療用語を列挙するだけでなく、データセットはそれらがどのように結びつくかも記録しています。著者らは18種類の関係を設計し、どの用量がどの薬剤に対応するか、治療がどれくらい続くか、患者がどの状態を経験しているかといった試験で重要なパターンを捉えています。時間的な関係はある事象が別の事象より前か後かを示し、ほかに病変の発生部位や否定・推定を表すリンクもあります。これらの関係により、コンピュータは単語を認識するだけでなく、患者の状況を示すグラフ――患者像、罹患している状態、受けている治療、時間的条件――を構築できます。
最新のAIモデルの訓練と評価
コーパスの実用性を示すため、著者らは多言語版BERTやRoBERTaを含むいくつかのトランスフォーマー系AIモデルをファインチューニングしました。モデルは関係抽出(エンティティ間のリンクを復元するタスク)と医療概念正規化(テキストをUMLSコードにマップするタスク)の2つの課題で訓練されています。関係抽出では、最良のモデルがF1スコアで約0.88を達成し、大部分の関係を比較的少ない誤りで正しく識別しました。概念正規化では、追加訓練なしで用いられた多言語モデルSapBERTが、一次推定でほぼ90%の確率で正しい概念を当てました。これらの結果は、よく注釈された中規模データセットが、大規模な汎用言語モデルがなくても正確で効率的なモデルを支えることを示しています。
なぜこの資源が今後の医療に重要なのか
CT‑EBM‑SPコーパスと関連モデルは、スペイン語の臨床試験テキストを自動で解析し、患者記録と照合し、病院でのコホート探索を支援するツールの基盤を提供します。データが国際的な医療基準に整合し、専門家によって入念にチェックされているため、デジタル資源が乏しい他言語向けの同様の資源開発にも役立ちます。日常的には、この研究は適切な患者に適切な試験をより簡単かつ安全に提供し、医療発見を加速させつつ医療従事者の負担を減らすことに関わる仕事です。
引用: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
キーワード: 臨床試験, 医療テキストマイニング, スペインの医療, トランスフォーマーモデル, エビデンスに基づく医療